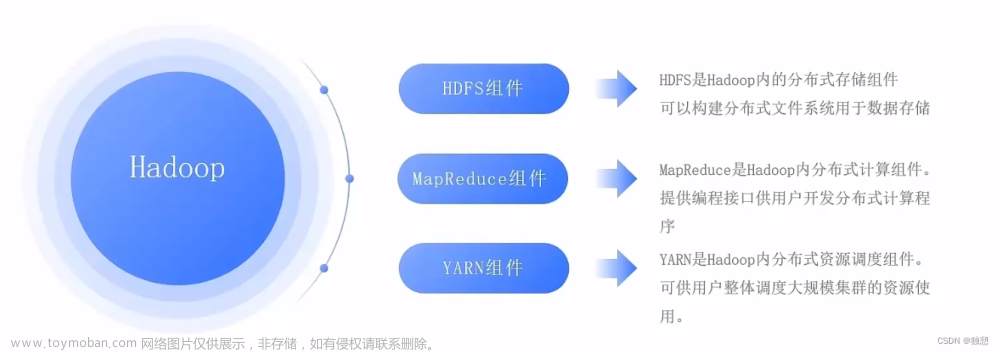
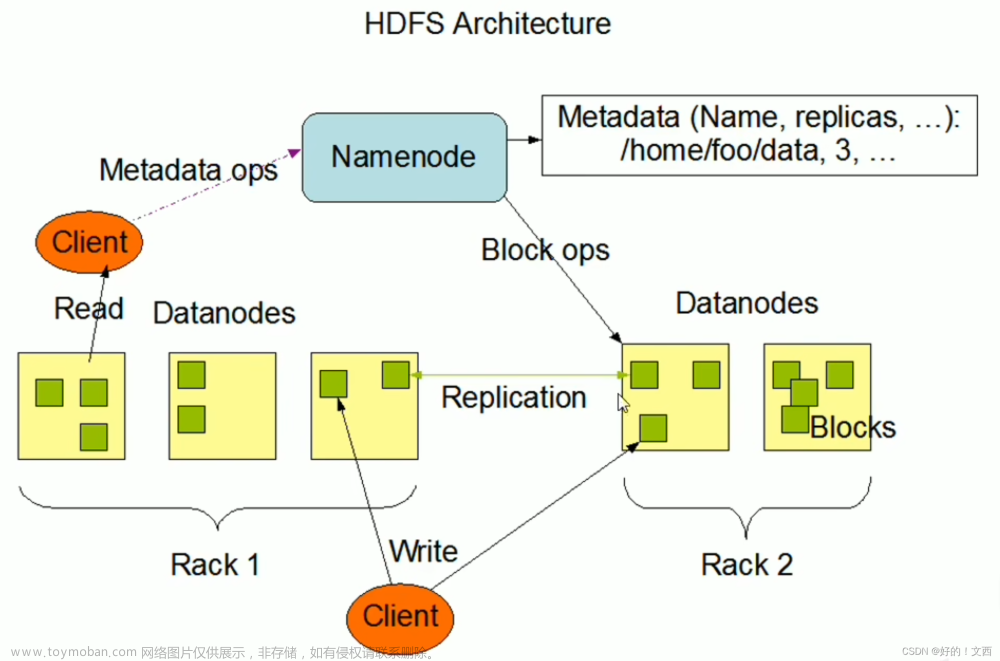
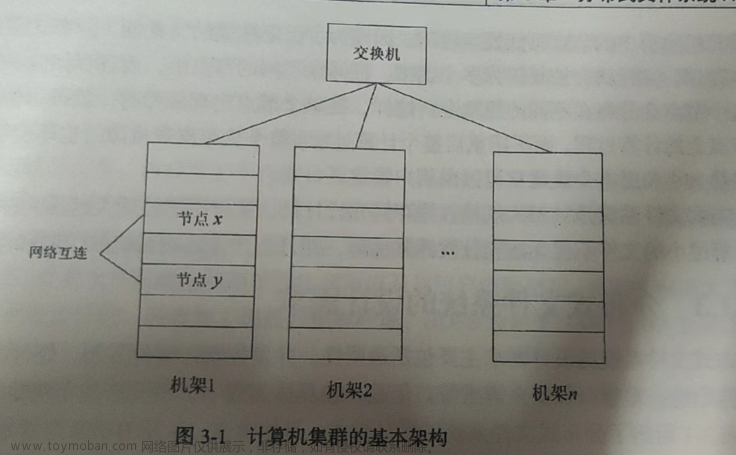
在HDFS的早期版本中,出于种种考虑,没有支持文件的追加写。但从1.0.4版本开始,支持了文件追加写。配置文件中也有是否开启该功能的选项:
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>而对于公有云上常见的对象存储,比如S3和OSS,是否支持追加写呢?
OSS的一般文件不支持append。不过可以创建追加写类型文件,就能够支持append。调用AppendObject接口会创建一个追加类型文件,后续就可以对该文件进行追加写操作。但这种模式似乎很少使用。
S3同样是不支持append的。
在对象存储服务上想对文件追加内容,一般都需要下载后追加然后再上传覆盖原来的文件。
以下论述摘自hudi官网:Hudi interacts with lake storage using the Hadoop FileSystem API, which makes it compatible with all of its implementations ranging from HDFS to Cloud Stores to even in-memory filesystems like Alluxio/Ignite. Hudi internally implements its own wrapper filesystem on top to provide additional storage optimizations (e.g: file sizing), performance optimizations (e.g: buffering), and metrics. Uniquely, Hudi takes full advantage of append support, for storage schemes that support it, like HDFS. This helps Hudi deliver streaming writes without causing an explosion in file counts/table metadata. Unfortunately, most cloud/object storages do not offer append capability today (except maybe Azure). In the future, we plan to leverage the lower-level APIs of major cloud object stores, to provide similar controls over file counts at streaming ingest latencies.
大意是说:Hudi 使用 Hadoop FileSystem API 与湖存储交互,这使其能够兼容从 HDFS 到云存储甚至内存文件系统(如 Alluxio/Ignite)的所有实现。Hudi 内部实现了自己包装过的文件系统,以提供额外的存储优化(例如:文件大小)、性能优化(例如:缓冲)和指标体系。值得一提的是,Hudi 充分利用了像 HDFS 之类的存储模式所支持的“append"特性。这有助于 Hudi 提供流式写入,而不会导致文件计数 / 表元数据激增。不幸的是,目前大多数云 / 对象存储都不提供“append”功能(Azure 除外)。未来我们计划利用主流云对象存储的低级 API,在流式摄取延迟时提供对文件计数的类似控制。文章来源:https://www.toymoban.com/news/detail-534496.html
该官网文章发表与2021年中,目前AWS EMR已声称集成了hudi,而hudi与OSS也似乎做了更多适配工作。文章来源地址https://www.toymoban.com/news/detail-534496.html
到了这里,关于关于hudi与HDFS/对象存储的文件追加写(Append)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!