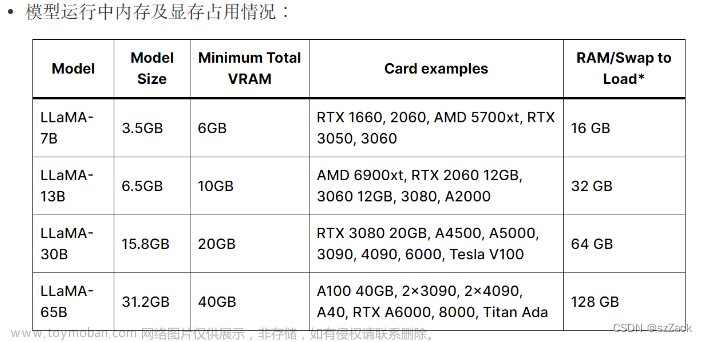
最近在开源项目ymcui/Chinese-LLaMA-Alpaca的基础上完成了自己的中文模型精调工作,形成了两个工具共享给大家。ymcui/Chinese-LLaMA-Alpaca
构建指令形式的精调文件
如果用于精调,首先要准备精调数据,目标用途如果是问答,需要按问答格式准备数据。因此写了第一个工具,用于从xlsx文件中读取数据,并按形成json格式的问答数据。

[
{
"instruction": "系统操作员,用户说:",
"input": "我想查询我的xx记录",
"output": "response:\n请稍后,正在对接相关服务\ncommand:\nsearch(\"xx查询接口\")"
},
....
]JSON文件的内容是一个对象数组,数组中的每一个对象包含instruction、input和output三个字段的内容,对应着一次对话中的提示,输入和输出。
因此我们的工具主要负责从目录中扫描所有xlsx文件,读取其中的内容,按行形成该格式的内容。
merge: 合并xls中的条目,形成用于微调的json文件 (gitee.com)https://gitee.com/bjf-fhe/merge
在线执行合并操作
形成数据文件之后,合并我们采用了在线利用Google Colab的方式,这里共享的是整体合并脚本
mege-chinese-llama/在线合并中文模型.ipynb at main · baijiafan/mege-chinese-llama (github.com)https://github.com/baijiafan/mege-chinese-llama/blob/main/%E5%9C%A8%E7%BA%BF%E5%90%88%E5%B9%B6%E4%B8%AD%E6%96%87%E6%A8%A1%E5%9E%8B.ipynb该脚本包含一些分支步骤,使用时请按指示选择不同的分支。
包括
1)第一次执行,执行ymcui/Chinese-LLaMA-Alpaca的合并步骤,形成中文基础模型,存储到Google Drive中
2)其他时候执行,则不用执行上述步骤,直接从Google Drive中加载相关模型
和选择不同存储方式等选项。
上述脚本会根据精调文本和基础模型形成精调后的Lora模型,该模型可以通过本地合并形成最终的中文精调模型。
 文章来源:https://www.toymoban.com/news/detail-534865.html
文章来源:https://www.toymoban.com/news/detail-534865.html
为什么没有直接在线合并?我的建议是将lora模型拷贝回本地进行合并,一是因为合并的设备要求不高,在本地就可以完成,另外是因为lora模型的体量较完整模型小,我这里7B版本的原始合并模型在16G左右,精调权重大概1.5G,差很多,这样,在国内环境下,下载精调模型更容易一些。 文章来源地址https://www.toymoban.com/news/detail-534865.html
到了这里,关于在中文LLaMA模型上进行精调的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!