开头
最近刷短视频看到了很多关于AI绘图,Midjourney,gittimg.ai,Stable Diffusion等一些绘图AI工具,感受到了AI绘画的魅力。通过chatGPT生成关键词再加上绘图工具,真是完美
Midjourney 算是体验最好的了,生成的图片也特别完美,使用也简单,它是在线网页,计算在云服务器上
新人有 25 次免费使用次数,不加入特定指令的情况下,是能生成四合一的图片的(算一次),单独挑出其中一张选择U或V(U是放大图片,U1\U2\U3\U4 分别指的是放大四张图片中的某一张,V是采用图片的构图形式,重新生成),只需要在输入框输入“/imagine”就可以开启AI智能图片之旅。输入指令 /info 能查看剩余分钟,订阅信息。Midjourney
gittimg.ai是一套神奇的 AI 工具,可以大规模生成原始图像、修改照片、将图片扩展到原始边界之外,或创建自定义 AI 模型
平台提供了20多个基于Stable Diffusion的AI模型。特别友好的是,每个用户每月免费提供了100张图片生成。几秒钟就能生成一张图片,还是很快的。getimg.ai
Stable Diffusion 开源免费,出图速度与电脑配置有关
和Midjourney功能差不多,可以文字转图片。电脑显卡越好出图越快。不过安装过程挺费劲的,花费了一天的时间才安装好,本篇文章将围绕Stable Diffusion从安装到使用的过程来介绍。项目地址
由AI画出来的人物,够真实吧

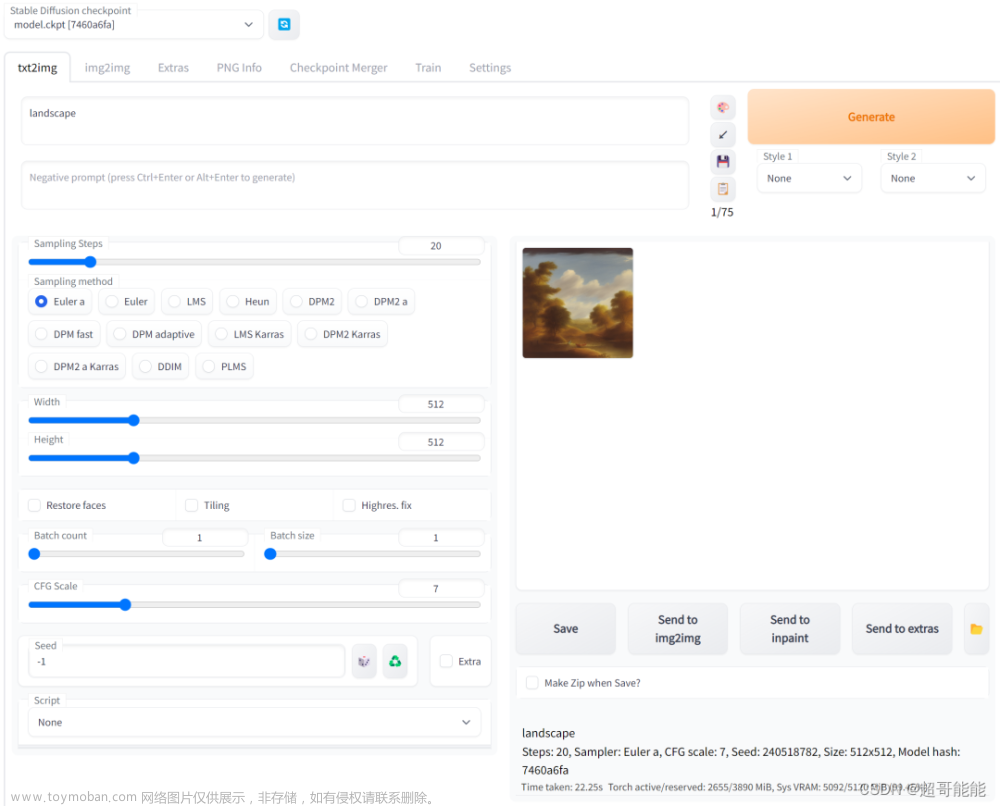
还有风景图,这个是用默认模型画的

AI绘图
什么是AI绘图
AI绘图是指使用人工智能(AI)技术生成或辅助创建图像和视觉内容的过程。AI绘图工具通常利用深度学习算法,如生成对抗网络(GANs)、变分自编码器(VAEs)和其他神经网络架构,以生成新的图像、对现有图像进行风格迁移、涂色,甚至根据文本描述生成相应的图像。
-
艺术创作:AI可以生成独特的艺术作品,模仿著名画家的风格,或者根据用户输入的指导进行创作。 -
设计:AI辅助设计工具可以帮助设计师更快地创建图标、插图、海报等视觉元素。 -
动画与游戏:AI可以自动生成游戏角色、场景和物品,减轻开发人员的负担,并提高创作效率。 -
影像处理:AI可以用于自动进行图像修复、去噪、涂色等操作,提高处理质量和效率。 -
图像生成:基于文本描述生成图像的AI模型可以为广告、社交媒体和其他平台提供定制的视觉内容。
Stable Diffusion
介绍 Stable Diffusion 是一个开源的工具,我们可以用文字来描绘 并将文字发给它,它就能帮我们生成对应的图片,同时它还支持图生图功能,等等。
模型
使用这个工具需要使用模型,官方也提供了对应的图像模型,下载即可。同时还可以去C站下载小模型来绘制不同领域的图片
配置
这个工具对硬件要求不是特别高,所以在我们个人电脑也能跑,不过生成的速度取决于电脑配置,显卡越好速度越快。由于该工具比较复杂,然后我们需要借助Stable Diffusion web ui 可视化工具来操作
安装
在线使用
在线使用需要借助谷歌的服务:stable-diffusion-webui-colab。需登录谷歌账户,然后点击页面中的启动 即可直接使用。在线使用本期先不细讲
本地安装使用
这里我使用的设备是笔记本电脑,window11,RTX20250,16g内存,12代因特尔处理器,生成一张图大概20秒
Stable Diffusion web ui依赖于Python3.10.6,所以需要先下载安装Python
安装Python
Python下载地址https://www.python.org/downloads/windows/
我这里下载的是安装版本,安装时候记得勾选添加到PATH,这样省得自己添加环境变量了

下载Stable Diffusion web ui
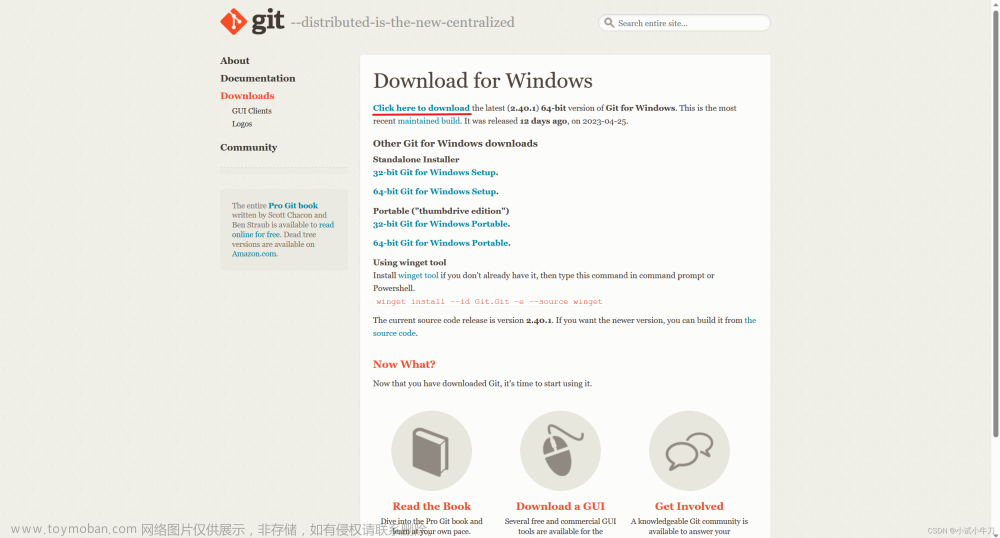
如果你没有安装git,那么需要安装一下git 下载地址
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
安装依赖
直接运行项目目录下的webui-user.bat文件,它将会自动安装所有的依赖,这里最好打开科学上网(git走的是终端的网络,上网工具需要开网卡模式),不然下载很慢还容易失败。
安装完依赖后会自动启动,因为首次要安依赖所以很慢,下次启动就会很快了

终端出现127.0.0.1:7860字样就代表启动成功了,然后使用浏览器访问即可,安装好默认是英文的

设置语言为中文
- 选择
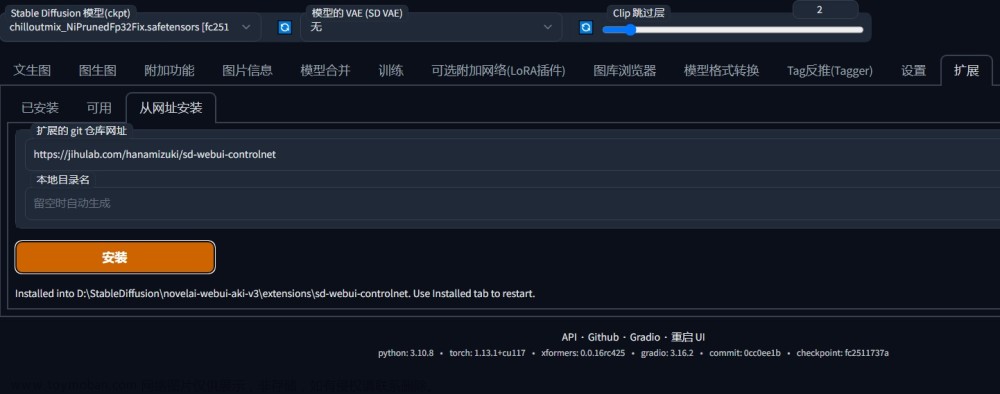
Extension选项卡,点击Install from URL子选项卡 - 复制git仓库地址
https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN
-
点击install按钮 进行安装。如图

-
然后重启webui,以确保插件载入成功。选择
Settings,点击Reload UI重启
-
在
Extensions选项卡,确定已勾选本扩展☑️;如未勾选,勾选后点击Apply and restart UI橙色按钮启用本扩展

- 切换语言包(zh-CN)
- 在
Settings选项卡中,找到User interface子选项

-
然后去页面最底部,找到
Localization (requires restart)小项,找到在下拉选单中选中zh_CN(如果没有就按一下🔄按钮),如图
-
然后按一下 页面顶部左边的 橙色
Apply settings按钮 保存设置,再按 右边的 橙色Reload UI按钮 重启webUI

到这里就完成了设置中文,重启webui后就切换为中文界面了

下载模型
模型说明
大模型 画图主要就是使用大模型的一些数据来生成图片,小模型lord的功能就是对大模型的一些参数做一些微调
大模型
下载官方提供的大模型https://github.com/camenduru/stable-diffusion-webui-colab
打开页面后,滑动到下面。如图。我这里下载的是1.5版本,稳定版

然后跳转页面,往下滑,找到Download,选择4.27G的这个

如果你想要绘制人物,那么推荐下载这个模型,绘制美女就用这个模型chilloutmix是日本的一位作者开发的AI人像模型,符合亚洲用户喜好的美女人像,上面的美女就是本模型画出来的

然后将下载的大模型放到 指定的文件内\stable-diffusion-webui\models\Stable-diffusion

小模型Lora
我们可以去C站找喜欢的小模型下载Civitai

找到你喜欢的图像,然后点击进去,选择下载,一般小模型就几百M

小模型我们放到 Lora文件夹\stable-diffusion-webui\models\Lora

以下是一些使用chilloutmix模型画出来的的图
使用
Stable Diffusion web ui 功能很多,我们主要用到如下两个功能
-
文生图(text-img)就是通过描述词来画图 -
图生图(img-img)导入图片,然后在加上描述词进行画一张新的图片
文生图
(如何下载导入模型在前面的安装篇章有说)
如图,页面左上角这里,选择大模型,我们可以切换想要的大模型。我选择官方默认模型

输入一些正面提示词
green sapling rowing out of ground,mud,dirt,grass,high quality,photorealistic,sharp focus,depth of field

使用chilloutmix模型
首先去C站找到喜欢的模型图片,然后点击图片右下角叹号

小模型下载说明在前面已经讲了。然后将提示信息,和对应的参数 在Stable diffusion web ui 上填写,然后就可以生成啦

启动参数
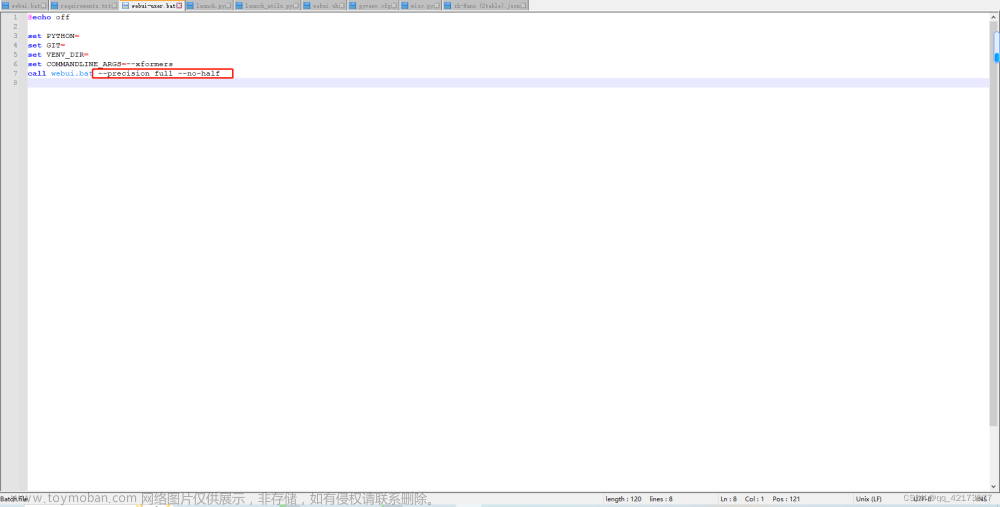
可以编辑项目目录下的 webui.bat文件,加入一行参数,如图

这里加的参数意思分别为
-
--listen启用局域网访问,这样就可以在别的电脑访问啦 -
--port 8888设置端口号为8888 -
--use-cpu设置使用cpu来处理,没显卡的电脑需要设置一下,因为默认是使用显卡GPU
如果想要通过api调用来生成图片,可以使用--api参数,启动webui后,在url地址上加上/docs就能看见api接口文档了。这样就能自己编写代码来调用文生图等等一些功能了接口详细文档
还有很多参数可以查阅官方文档文章来源:https://www.toymoban.com/news/detail-535389.html
其它
默认使用的是GPU,如果没独显可能需要配置一下参数选择使用cpu处理文章来源地址https://www.toymoban.com/news/detail-535389.html
到了这里,关于记录 AI绘图 Stable Diffusion的本地安装使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!