1.简介
GitHub - qinL-cdy/auto_ai_subtitle
github上开源的一款字幕生成和字幕翻译的整合工具,可以根据视频中提取到的音频来转换成字幕,再根据需要将字幕进行翻译,基于whisper
2.效果
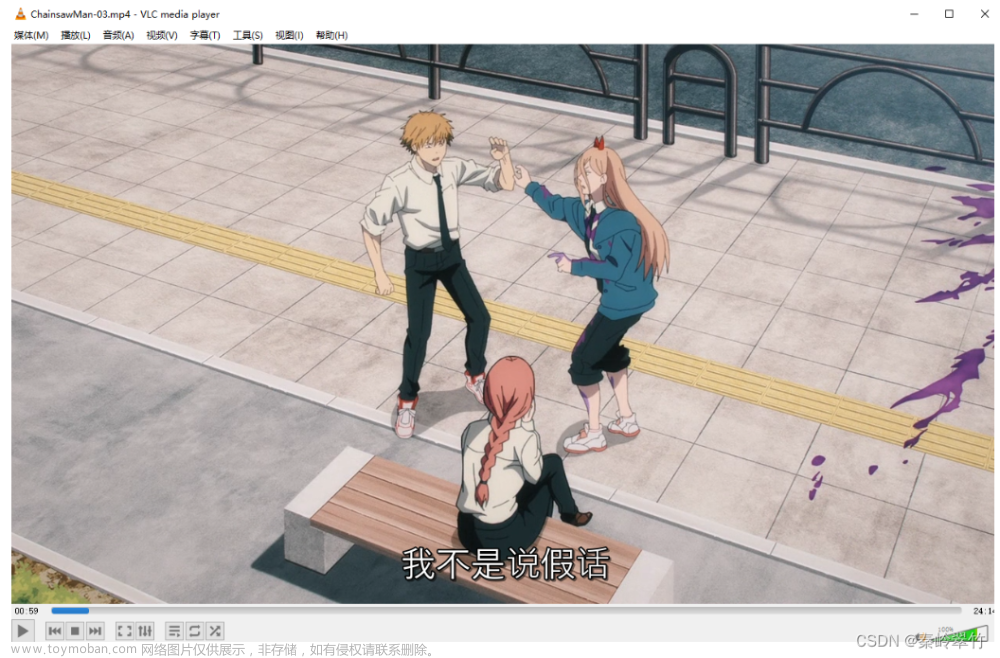
3.使用
1)安装ffmpeg
安装ffmpeg的教程比较多,就不详细介绍了,Windows上安装完成后记得添加环境变量,最后在cmd中输入"ffmpeg –version",有相应打印即可
2)拉取代码
使用git拉取代码即可,没有git的可以参考网上资料安装一下
git clone https://github.com/qinL-cdy/auto_ai_subtitle.git3)安装python依赖
使用pip安装相关依赖,当然前提是已经安装好python环境了
进入git下来的工程目录,可以看到有一个requirements.txt
在目录下执行
pip install -r requirements.txt这样pip就会自动安装所有需要的依赖了
4)填写配置信息
打开当前目录下的config.yaml文件,根据提示填写对应的信息,例如:
#输入的视频文件
input: D:\download\ChainsawMan-03.mp4
#中间过程会生成的音频文件
output: D:\download\ChainsawMan-03.mp3
#生成的原始字幕文件
srt_path: D:\download\ChainsawMan-03.srt
#生成的翻译后的字幕文件
srt_translate_path: D:\download\ChainsawMan-03-zh.srt
#翻译时开启多少线程
translate_threads: 10
#翻译源语言
from: ja
#翻译目标语言
to: zh5)执行程序
最后一步,使用python命令执行程序即可
python main.py6)其他用法
观察main.py文件:
import yaml
from script import translate_tool, audio_tool, whisper_tool
if __name__ == '__main__':
with open('config.yaml', encoding='utf-8') as f:
config = yaml.load(f.read(), Loader=yaml.FullLoader)
print("audio extract begin")
audio_tool.audio_extract(config['input'], config['output'])
print("audio extract success")
print("whisper begin")
whisper_tool.do_whisper(config['output'], config['srt_path'])
print("whisper success")
print("translate begin")
translate_tool.do_translate(config['srt_path'], config['srt_translate_path'], config['from'], config['to'],
config['translate_threads'])
print("translate success")
print("success")可以看到脚本是由多个独立的调用步骤组合而成的,所以也可以根据自己的需要调整来自定义执行某一个或多个功能
例如,只执行音频提取和字幕生成,但不进行翻译:
import yaml
from script import translate_tool, audio_tool, whisper_tool
if __name__ == '__main__':
with open('config.yaml', encoding='utf-8') as f:
config = yaml.load(f.read(), Loader=yaml.FullLoader)
print("audio extract begin")
audio_tool.audio_extract(config['input'], config['output'])
print("audio extract success")
print("whisper begin")
whisper_tool.do_whisper(config['output'], config['srt_path'])
print("whisper success")
#print("translate begin")
#translate_tool.do_translate(config['srt_path'], config['srt_translate_path'], config['from'], config['to'],config['translate_threads'])
#print("translate success")
print("success")4.原理
1)音频提取
import ffmpeg
def audio_extract(input, output):
ffmpeg.input(input, vn=None).output(output).run()使用了ffmpeg的能力,其中vn=None代表忽略视频,所以执行后只会输出对应的音频
2)字幕提取
字幕生成使用了openai开源的whisper
def do_whisper(audio, srt_path):
model = whisper.load_model("base")
print("whisper working...")
result = model.transcribe(audio)
print("whisper execute success")
print("writing srt file...")
write_srt(result['segments'], srt_path)
print("write srt success")这里只是用了最基本的模型,所以在精度上可能不够高,使用者可以基于whisper开源的模型做进一步优化
3)字幕翻译文章来源:https://www.toymoban.com/news/detail-535940.html
字幕翻译使用了常用的开源库translate,就不做进一步介绍了,感兴趣可以查看相关资料文章来源地址https://www.toymoban.com/news/detail-535940.html
到了这里,关于github开源推荐,基于whisper的字幕生成和字幕翻译工具——再也没有看不懂的片啦的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!