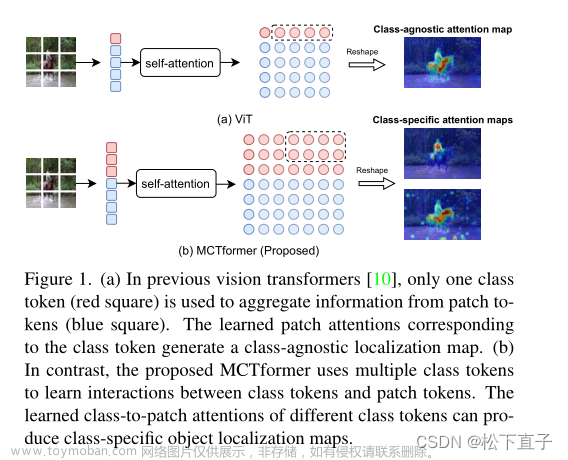
目标:
在NLP领域,基于公开语料的预训练模型,在专业领域迁移时,会遇到专业领域词汇不在词汇表的问题,本文介绍如何添加专有名词到预训练模型。
例如,在bert预训练模型中,并不包含财经词汇,比如‘市盈率’等财务指标词汇,本文将介绍:
- 如何把专业名词添加到词汇表中
- 方法1:修改 vocab
- 方法2:更通用,修改分词器tokenizer
- 如何保留现有模型能力,并训练新词汇的embedding表示
内容:
NLP的分词
NLP的处理流程:
- 对输入的句子进行分词,得到词语及下标
- 通过embedding层获得词语对应的embedding
- embedding送入到预训练模型,经过attention注意力机制,获得token在句子中的语义embedding向量
- 利用语义embedding向量,构建下游任务。
其中,预训练模型是在公开语料上训练的,我们在做迁移学习,把模型迁移到财经领域时,会面临的一个问题,就是财经词汇不在词汇表,会被拆分成单个字,从而会导致专业名词的完整意思的破坏,或者让模型去学习时,不那么直观,比如:
- ‘华为的市盈率较高’ 默认会被拆分为:['
, ‘’, ‘华为’, ‘的’, ‘市’, ‘盈’, ‘率’, ‘较高’, ‘’] - 可见,市盈率被拆分成了 ‘市’, ‘盈’, ‘率’。
- 我们可以让显式的告诉分词器,市盈率是一个专业名词,无需拆分。因此,经过处理后,词汇被分成了[‘
’, ‘’, ‘华为’, ‘的’, ‘市盈率’, ‘’, ‘较高’, ‘’] - 达到了预期目标
from transformers import AutoTokenizer,AutoModel
PRE_TRAINED_MODEL_NAME='xlm-roberta-base'
tokenizer = AutoTokenizer.from_pretrained(PRE_TRAINED_MODEL_NAME)
e = tokenizer.encode('华为的市盈率较高')
s = [tokenizer.decode(i) for i in e]
print(s)
# ['<s>', '', '华为', '的', '市', '盈', '率', '较高', '</s>']
tokenizer.add_tokens(["市盈率"])
e2 = tokenizer.encode('华为的市盈率较高')
s2 = [tokenizer.decode(i) for i in e2]
print(s2)
# ['<s>', '', '华为', '的', '市盈率', '', '较高', '</s>']
实现方式:
有两种实现
-
- 在vocab.txt中,利用前100里的[unused],将[unused]换成自己想要添加的。具体有多少个[unused]要看自己的预训练模型,可能100个,可能1000个,但都有限。如果要添加的词汇量小,并且预训练模型确实有vocab.txt文件,则可以,比如bert,目前看对于领域来说,量不够大。
-
- 更加通用的办法:通过tokenizer,向词汇表中追加新的专业词汇,没有不限。特别是现在比较复杂的模型,都没有单独的vocab.txt文件了,只能通过这种方式。
import torch
from transformers import AutoTokenizer,AutoModel
PRE_TRAINED_MODEL_NAME='xlm-roberta-base'
tokenizer = AutoTokenizer.from_pretrained(PRE_TRAINED_MODEL_NAME)
model = AutoModel.from_pretrained(PRE_TRAINED_MODEL_NAME)
print(len(tokenizer)) # 250002
tokenizer.add_tokens(["NEW_TOKEN"])
print(len(tokenizer)) # 250003
新词汇embedding的生成:
新词汇的加入,势必会不适配原始embedding的维度,原始的embedding维度为[vocab_size,hidden_size],但是我们又不可能重新去训练整个embedding,我们想尽量保留原始embedding参数,因此,这里比较巧妙的运用了reshape技巧,人为添加新词汇的embedding(随机的,没学习),然后使用领域材料进行学习。
这种方法,因为是添加token,需要修改embedding matrix。
实验证明resize matrix不会打扰原始预训练的embeddings。文章来源:https://www.toymoban.com/news/detail-536085.html
import torch
from transformers import AutoTokenizer,AutoModel
PRE_TRAINED_MODEL_NAME='xlm-roberta-base'
tokenizer = AutoTokenizer.from_pretrained(PRE_TRAINED_MODEL_NAME)
model = AutoModel.from_pretrained(PRE_TRAINED_MODEL_NAME)
print(len(tokenizer)) # 250002
tokenizer.add_tokens(["NEW_TOKEN"])
print(len(tokenizer)) # 250003
x = model.embeddings.word_embeddings.weight[-1, :] # 原始最后一个token的embedding
model.resize_token_embeddings(len(tokenizer)) # 调整embedding维度
# The new vector is added at the end of the embedding matrix
print(model.embeddings.word_embeddings.weight[-1, :])
# Randomly generated matrix 添加的embedding是随机值。
with torch.no_grad():
model.embeddings.word_embeddings.weight[-1, :] = torch.zeros([model.config.hidden_size])
# 人为设置新添加的embedding为0
print(model.embeddings.word_embeddings.weight[-1, :])
# outputs a vector of zeros of shape [768]
y = model.embeddings.word_embeddings.weight[-2, :] # 原始最后一个token变成倒数第二了,取其embedding
print(x == y) # 原始token的embedding会改变吗?原来embedding weight 不会变
e = tokenizer.encode('华为的市盈率较高')
s = [tokenizer.decode(i) for i in e]
print(s)
tokenizer.add_tokens(["市盈率"])
e2 = tokenizer.encode('华为的市盈率较高')
s2 = [tokenizer.decode(i) for i in e2]
print(s2)
有了这个初始embedding,经过MLM等任务,就可以训练新词汇的embedding表示了,通过下游任务来学习这个embedding。文章来源地址https://www.toymoban.com/news/detail-536085.html
掌握:
- 添加领域词汇的方式
- 修改新embedding的方式
- 训练新token的embedding
到了这里,关于Pytorch transformers tokenizer 分词器词汇表添加新的词语和embedding的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!