1. Spark RDD是什么
RDD(Resilient Distributed Dataset,弹性分布式数据集)是一个不可变的分布式对象集合,是Spark中最基本的数据抽象。在代码中RDD是一个抽象类,代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
每个RDD都被分为多个分区,这些分区运行在集群中的不同节点上。RDD可以包含Python、Java、Scala中任意类型的对象,甚至可以包含用户自定义的对象。RDD的转化操作都是惰性求值的,所以我们不应该把RDD看作存放着特定数据的数据集,而最好把每个RDD当作我们通过转化操作构建出来的、记录如何计算数据的指令列表。
RDD表示只读的分区的数据集,对RDD进行改动,只能通过RDD的转换操作,由一个RDD得到一个新的RDD,新的RDD包含了从其他RDD衍生所必需的信息。RDD之间存在依赖,RDD的执行是按照依赖关系延时计算的。如果依赖关系较长,那么可以通过持久化RDD来切断依赖关系。RDD逻辑上是分区的,每个分区的数据抽象存在,计算的时候会通过一个compute函数得到每个分区的数据。如果RDD是通过已有的文件系统构建的,那么compute函数读取指定文件系统中的数据;如果RDD是通过其他RDD转换而来的,那么compute函数将首先执行转换逻辑,也就是将其他RDD的数据进行转换[yx1] [2] 。
2. RDD的主要属性
RDD的主要属性如下:
(1)A list of partitions:多个分区。
分区可以看作数据集的基本组成单位。对于RDD来说,每个分区都会被一个计算任务处理,并决定了并行计算的粒度。用户可以在创建RDD时指定RDD的分区数,如果没有指定,就会采用默认值。默认值就是程序所分配到的CPU Core的数目。每个分配的存储是由BlockManager实现的。每个分区都会被逻辑映射成BlockManager的一个Block,而这个Block会被一个task负责计算。
(2)A function for computing each split:计算每个切片(分区)的函数。
Spark中RDD的计算是以分区为单位的,每个RDD都会实现compute函数以达到这个目的。
(3)A list of dependencies on other RDDs:与其他RDD之间的依赖关系。
RDD的每次转换都会生成一个新的RDD,所以RDD之间会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
(4)Optionally,a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned):
对存储键-值对的RDD来说,还有一个可选的分区器。只有存储键-值对的RDD,才会有分区器;没有存储键-值对的RDD,其分区器的值是None。分区器不但决定了RDD的本区数量,也决定了父RDDShuffle[yx3] [4] 输出时的分区数量。
(5)Optionally,a list of preferred locations to compute each split on (e.g. block locations for an HDFS file):存储每个切片优先位置的列表。
比如对于一个HDFS文件来说,这个列表保存的就是每个分区所在文件块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到它所要处理的数据块的存储位置。
3. RDD的处理过程
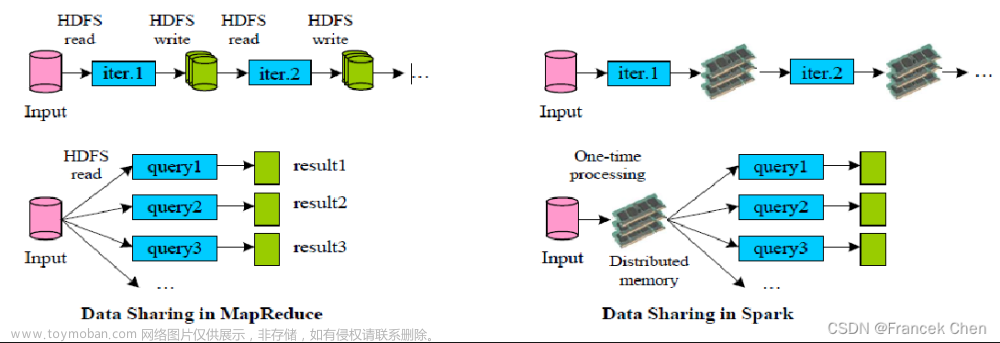
Spark用Scala语言实现了RDD的API,程序开发者可以通过调用API对RDD进行操作。RDD经过一系列的“转换”操作,每一次转换都会产生不同的RDD,以供下一次“转换”操作使用,直到最后一个RDD经过“行动”操作才会被真正计算处理,并输出到外部数据源中,若是中间的数据结果需要复用,则可以进行缓存处理,将数据缓存到内存中。整个处理过程如图所示。

文章来源地址https://www.toymoban.com/news/detail-537059.html
 文章来源:https://www.toymoban.com/news/detail-537059.html
文章来源:https://www.toymoban.com/news/detail-537059.html
到了这里,关于Spark弹性分布式数据集的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!