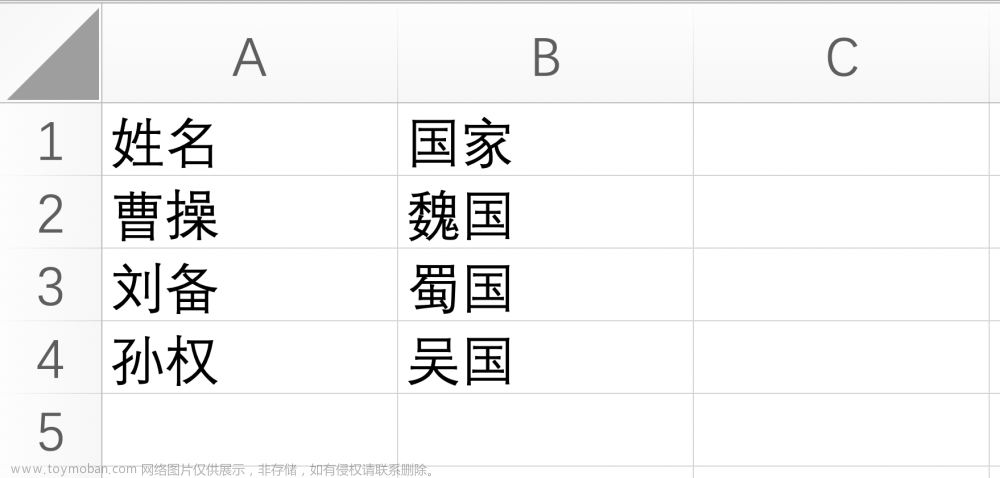
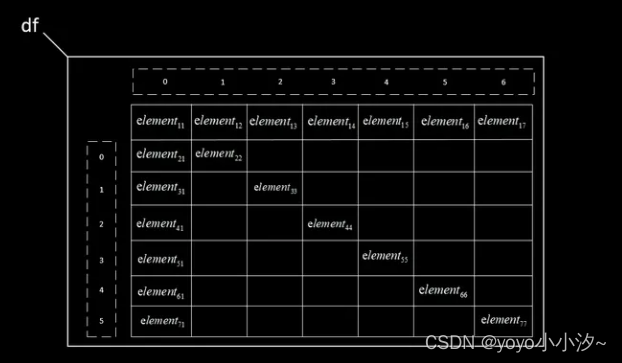
python实现对excel表格不同文件形式的读取
我最近在用 pycharm 读取excel数据出现几个莫名其妙的问题, 我解决问题之后,觉得还是把这些坑都写清楚,方便 python 的初学者。
用xlrd库读取.xls文件
xlrd库只能读取.xls文件 是因为xlrd在高版本中该库认为.xlsx文件存在漏洞
用库openpyxl读取.xlsx文件
用库openpyxl是不能读取.xls文件的
'.xls文件的读取'文章来源:https://www.toymoban.com/news/detail-537670.html
# xlrd库只能读取.xls文件 是因为xlrd在目前的版本中该库.xlsx文件存在漏洞
def excelread(catalog, path):
# 获取文件路径
base_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(base_dir, catalog, path)
data = xlrd.open_workbook(file_path)
table = data.sheets()[0]
nrows = table.nrows # 行数
ncols = table.ncols # 列数
datamatrix = np.zeros((nrows - 1, ncols - 1)) # 减去第一列
for x in range(ncols - 1):
cols = table.col_values(x + 1) # 索引从1开始 从excel第二行开始 减去excel左侧目录
datamatrix[:, x] = cols[1:] # 把数据进行存储 减去excel上侧目录
return datamatrix
m = excelread('files', 'zz.xls')'.xlsx文件的读取' 文章来源地址https://www.toymoban.com/news/detail-537670.html
# .xlsx文件 选用库openpyxl读取 注意该库不能读取.xls文件
def excelread2(catalog, path):
# 获取文件路径
base_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(base_dir, catalog, path)
wb = load_workbook(file_path)
sheet = wb.worksheets[0]
nrows = sheet.max_row # 行数
ncols = sheet.max_column # 列数
datamatrix = np.zeros((nrows - 1, ncols - 1)) # 减去第一列
index = 0
for row in sheet.iter_rows(min_row=2):
cell_list = row[1:]
text_list = []
for cell in cell_list:
if cell.value is None:
cell.value = float('inf')
text_list.append(cell.value)
# text_array = np.array(text_list) # 列表转数组
text_mat = np.mat(text_list) # 数组转矩阵
# print(text_mat)
datamatrix[index, :] = text_mat
index += 1
return datamatrix
m = excelread2('files', 'zz.xls')到了这里,关于【python读取excel文件保存为矩阵形式】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!