目录
一、Apriori
二、FP-Growth
一、Apriori
算法理论部分参考:
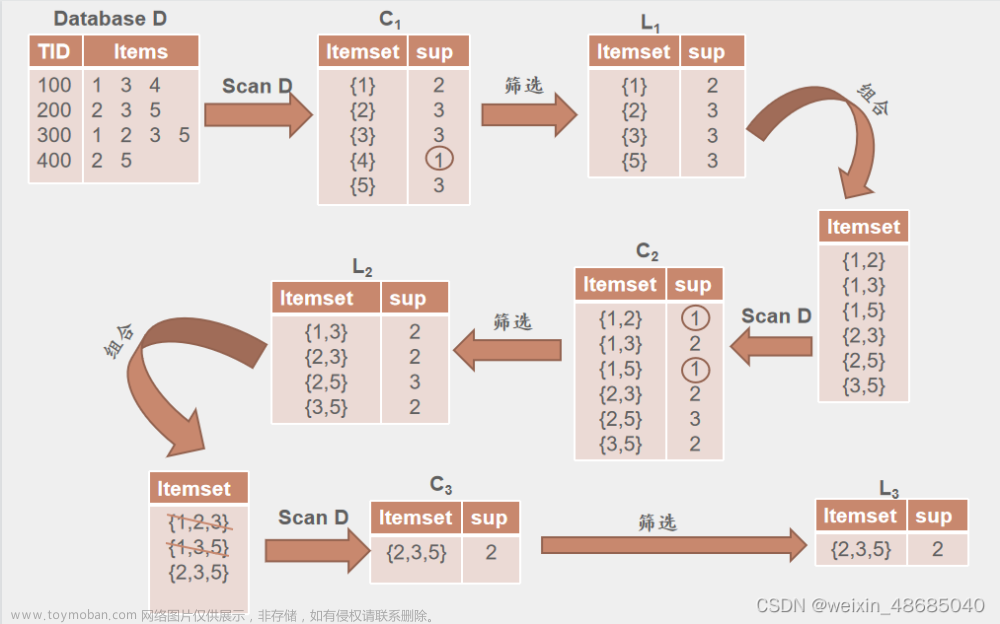
(28条消息) Apriori算法与FP-Tree算法_messi_james的博客-CSDN博客
import pandas as pd
# 构造数据集
item_list = [('牛奶','面包','尿不湿','啤酒','榴莲'),
('可乐','面包','尿不湿','啤酒','牛仔裤'),
('牛奶','尿不湿','啤酒','鸡蛋','咖啡'),
('面包','牛奶','尿不湿','啤酒','睡衣'),
('面包','牛奶','尿不湿','可乐','鸡翅')]
item_df = pd.DataFrame(item_list)
item_df
# 数据格式处理,传入模型的数据需要满足bool值得格式
from mlxtend.preprocessing import TransactionEncoder
te = TransactionEncoder()
df_tf = te.fit_transform(item_list)
df = pd.DataFrame(df_tf,columns=te.columns_)
df
# 计算频繁项集
from mlxtend.frequent_patterns import apriori
# use_colnames=True表示使用元素名字,默认得False使用列明代表元素,设置最小支持度min_support
frequent_itemsets = apriori(df, min_support=0.05, use_colnames=True)
frequent_itemsets.sort_values(by='support',ascending=False, inplace=True)
# 计算关联规则
from mlxtend.frequent_patterns import association_rules
# metric可以有很多的度量选项,返回的表列名都可以作为参数
association_rule = association_rules(frequent_itemsets,metric='confidence',min_threshold=0.9)
# 关联规则以提升度排序
association_rule.sort_values(by = 'lift',ascending=False,inplace=True)
# 找出单项且项集支持度较高的关联规则
association_rule[(association_rule.antecedents.apply(lambda x: len(x)) == 1)
&(association_rule.consequents.apply(lambda x: len(x)) == 1)
&(association_rule['antecedent support'] >=0.8)
&(association_rule['consequent support'] >=0.8)
]
二、FP-Growth
import pandas as pd
# 构造数据集
item_list = [['Milk', 'Broccoli', 'Sauce', 'Beef', 'Eggs', 'Yogurt'],
['Wine', 'Broccoli', 'Sauce', 'Beef', 'Eggs', 'Yogurt'],
['Milk', 'Apple', 'Beef', 'Eggs'],
['Milk', 'Fish', 'Corn', 'Beef', 'Yogurt'],
['Corn', 'Broccoli', 'Broccoli', 'Beef', 'Banana', 'Eggs']]
item_df = pd.DataFrame(item_list)
# 数据格式处理,传入模型的数据需要满足bool值的格式
from mlxtend.preprocessing import TransactionEncoder
te = TransactionEncoder()
df_tf = te.fit_transform(item_list)
df = pd.DataFrame(df_tf,columns=te.columns_)
df
# fp growth
from mlxtend.frequent_patterns import fpgrowth
# 计算频繁项集
frequent_itemsets_fp=fpgrowth(df, min_support=0.02, use_colnames=True)
# 计算管理那规则
rules_fp = association_rules(frequent_itemsets_fp, metric="confidence", min_threshold=0.9)
# 关联规则以提升度排序
rules_fp.sort_values(by = 'lift',ascending=False,inplace=True)
# 找出单项且项集支持度较高的关联规则
rules_fp[(rules_fp.antecedents.apply(lambda x: len(x)) == 1)
&(rules_fp.consequents.apply(lambda x: len(x)) == 1)
&(rules_fp['antecedent support'] >=0.8)
&(rules_fp['consequent support'] >=0.5)
]
参考:文章来源:https://www.toymoban.com/news/detail-538814.html
(28条消息) 【机器学习】关联规则及python实现_mlxtend.frequent_patterns_为什么昵称不能重复的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-538814.html
到了这里,关于关联规则算法(Apriori算法、FP-Growth算法)小案例(python mlxtend)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!