小样本图像目标检测研究综述——张振伟(计算机工程与应用 2022) 论文阅读
目前,小样本图像目标检测方法多基于经典的俩阶段目标检测算法Faster R-CNN作为主干网络,当然也有将YOLO,SSD一阶段目标检测算法作为主干网络的。
检测过程中不仅需要提取分类任务所关注的高层语义信息,还要获取低层级像素级信息实现目标的定位。
1、方法分类
1.2.1 基于度量学习方法
基于度量学习的方法是在获取潜在目标区域特征的前提下,将目标区域特征和支持图像特征转换到相同的嵌入空间,通过计算距离或者相似度对潜在的目标区域进行分类,进而实现对图像中不同目标的检测。
==基于度量学习的方法另一个研究的重点是损失函数设计。一个有效的损失函数应当能使得同类别具有高度的相似度,而不同类别之间相似度尽可能小。==如[23 One-shot Object Detection with co-attention and co-excitation_2019]设计了基于裕度的排名损失(margin-based rank loss),用于隐式学习一种度量来预测区域建议和查询特征的相似性。
度量学习主要体现在最后的分类器部分,用于类别相似度度量。
基于度量学习的方法更容易实现增量式学习,即模型在基类数据集上完成训练后可以直接用于新类别目标检测。但同时由于度量学习重点关注类别相似性,而定位信息则主要依赖于前一阶段区域建议网络,使得模型检测性能还需要进一步验证。
1.2.2 基于数据增强的方法
Wu等[10 Multi-scale positive sample sample refinement for few-shot object detection] 提出了一种多尺度正样本优化方法(MPSR),如下图所示,通过构建目标金字塔(object pyramids),形成多个尺度正样本,而后利用特征金字塔网络(feature pyramid net,FPN)构建特征金字塔(feature pyramids)进一步增强数据多样性,用于对网络进行训练。

1.2.3基于模型结构的方法

在常规检测模型基础上,通过构建新的模型结构提供有效的辅助信息,从而降低对样本数量的依赖,达到小样本条件下检测的目的。
[19 Context-transformer: tackling object confusion for few-shot detection]
直接采用迁移学习,在目标定位方面表现的比较好,但是在分类层面是就比较容易出现混淆等问题。因为目标定位只需要区分定位的目标属于前景还是背景,所以基于此,[19]提出了一种即插即用的上下文转换器模块,该模块由相似性发现(affinity discovery)和上下文聚合(context aggregation)俩个字模块构成,能够发现基类和新类的关联关系,通过上下文关联关系有效解决目标混淆问题。
[8 Few-shot object detection with attention-RPN and multi-relation detector - IEEE 2020]
认为区域候选网络在没有足够辅助信息支持的情况下,难以过滤掉与目标不相关的前景信息,导致网络产生大量的目标不相关信息,为解决上述问题,提出一种新的注意力网络,通过权值共享充分学习目标间的匹配关系以及同类别的通用知识。
[32 Leveraging bottom- up and top-down attention for few-shot object detection 20年7月]
[32] 结合元学习和迁移学习的优点,引入了新颖的注意力目标检测器,能够结合自下而上和自上而下的注意力,其中自下而上的注意力提供了显著区域的先验知识,自上而下的注意力从目标标注信息进行学习。同 时,在常规目标检测损失函数的基础上设计了目标聚焦损失和背景聚焦损失项,目标聚焦损失有助于将同一物体的特征聚集到一起,而背景聚焦损失有助于解决部分未标注目标被错分为背景的问题,最终通过混合训练策略,模型获得了较好的检测性能。
1.2.4基于元学习的方法
[12Meta RCNN: towards fast adaptation for few-shot object detection with Meta learing-2019]
在 Mask RCNN 的基础上提出了 Meta R-CNN,利用支持分支获取类别注意力向量后与兴趣区域特征相融合作为新的预测特征用于检测或分割
[35 Few-shot object detection and viewpoint estimation for objects in the wild-2020]
在 Meta R-CNN的基础上对融合网络进一步改进获得了更好的检测性能
[36 Incremental few-shot object detection-2020]
借鉴CenterNet的结构和思路提出一种中心点预测的元学习方法,该模型能够实现增量式学习,即在添加新类后无需再访问基类数据。
[38 Meta-DETR: few-shot object detection via unified image-level meta-learning]
认为现有的元学习方法主要局限于区域级预测,性能主要依赖于最初定位良好的区域建议。针对这一问题,在 Deformable DETR[39] 基础上,将近年来流行的Transformer[40] 与元学习相结合,提出了图像级元学习小样本目标检测模型,用编码、解码器替代了原有的非极大值抑(NMS)、锚框等启发式组件,实现了在图像层级上的目标定位和分类。
1.2.5 基于微调的方法
首先利用大量的基类数据对现有的模型进行预训练,然后利用少量的新类别对部分参数进行微调。

其难点在于如何相对准确地区分类别相关和类别无关参数以及选择合适的超参数。尽管上述是将骨干网络部分和ROI池化部分作为类别无关的组件,但这种划分仍然缺乏足够的理论支撑。
1.2.6 基于集成的方法
就是将各种方法的优点集成到一起。

2. 实验设计
2.1 数据集

2.2实验设计
文献[16]首次详细介绍了PASCAL VOC和MSCOCO数据集划分设置,在之后的小样本目标检测研究中,基本沿用了文献[16]的数据集设置方式。对于 PASCALVOC 数据集,采用 3 种不同的类别分组,每种分组按照15 个类别作为基类,剩余 5 个类别作为新类进行设置;对于MSCOCO数据集则选择与VOC数据集类别重合的20个类作为新类,剩余80个类别作为基类。对于FSOD数据集则按照文献[8]的实验设置,选择与其他类别相似度较小的200类作为新类,其余800类作为基类。训练过程中,对于基类,均提供全部图片及标注信息,对于新类,则根据1/2/3/5/10-shot(VOC)或者10/30-shot(MSCOCO)等不同的实验设置选取相应的图片及标注信息。

文献
[23 One-shot Object Detection with co-attention and co-excitation_2019]增量学习
[10 Multi-scale positive sample sample refinement for few-shot object detection] 数据增强
- 模型结构
[19 Context-transformer: tackling object confusion for few-shot detection]
[8 Few-shot object detection with attention-RPN and multi-relation detector - IEEE 2020]
[32 Leveraging bottom- up and top-down attention for few-shot object detection 20年7月]
- 域适应小样本目标检测
[64 Few-shot adaptive faster RCNN_IEEE2019] 首个真正意义上的域适应小样本目标检测文章来源:https://www.toymoban.com/news/detail-538976.html
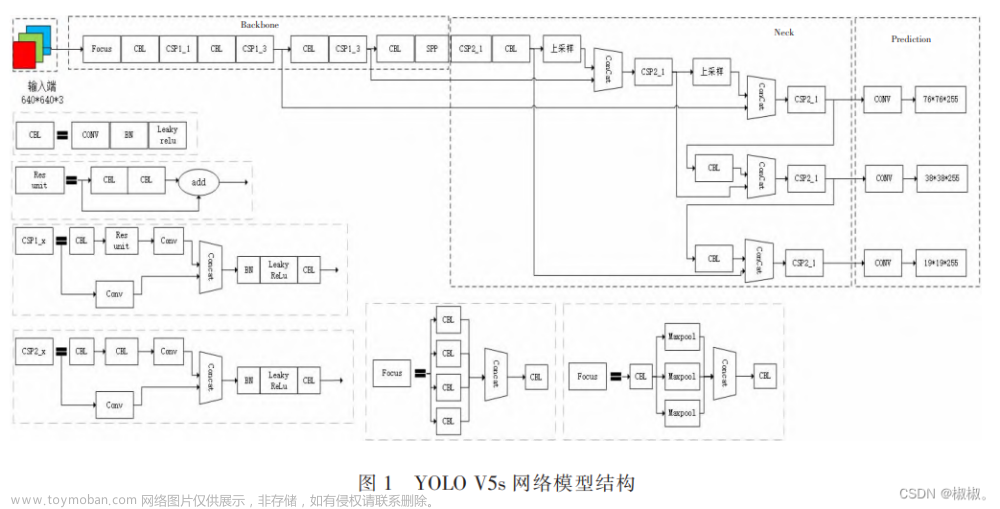
传统的小样本图像目标检测普遍采用俩段式Faster RCNN作为基础框架,模型相对复杂,不易部署,将来可以尝试使用YOLO作为基础框架,兼顾精度和检测速度俩个方面。让模型部署成为可能。文章来源地址https://www.toymoban.com/news/detail-538976.html
到了这里,关于小样本图像目标检测研究综述——张振伟论文阅读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!