kafka消费方式

pull(拉)模式:
consumer采用从broker中主动拉取数据。
Kafka采用这种方式。
push(推)模式:
Kafka没有采用这种方式,因为由broker决定消息发送速率,很难适应所有消费者的速率。例如推送速度是50m/s,consumer1,consumer2就来不及处理消息
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一致返回空数据
消费者总体工作流程

1)每个消费者的offset由消费者提交到系统主题保存
2)每个分区的数据只能由消费者组中一个消费者消费
3)一个消费者可以消费多个分区数据
消费者原理

Consumer Group(CG):消费者组,由多个consumer组成,形成一个消费组的条件,是所有消费组groupid相同。
消费者组内每个消费者负责消费不同的分区数据,一个分区只能由由一个组内消费者消费。
消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
1)如果消费组中添加更多的消费者,超过主题分区数量,则有一部分消费者就会闲置,不会接收任何消息
2)消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
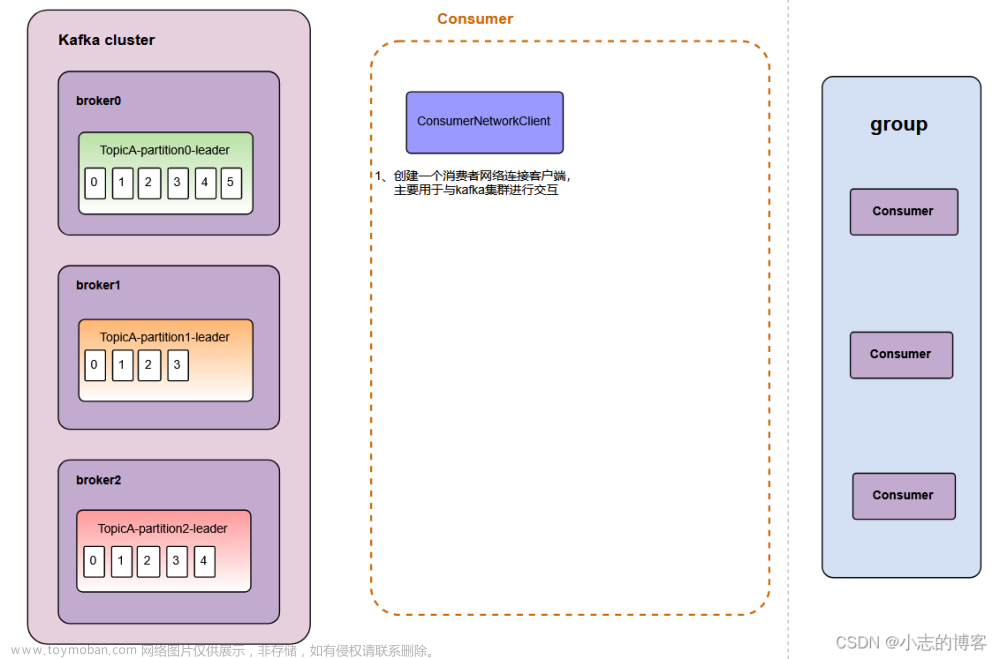
消费者初始化流程

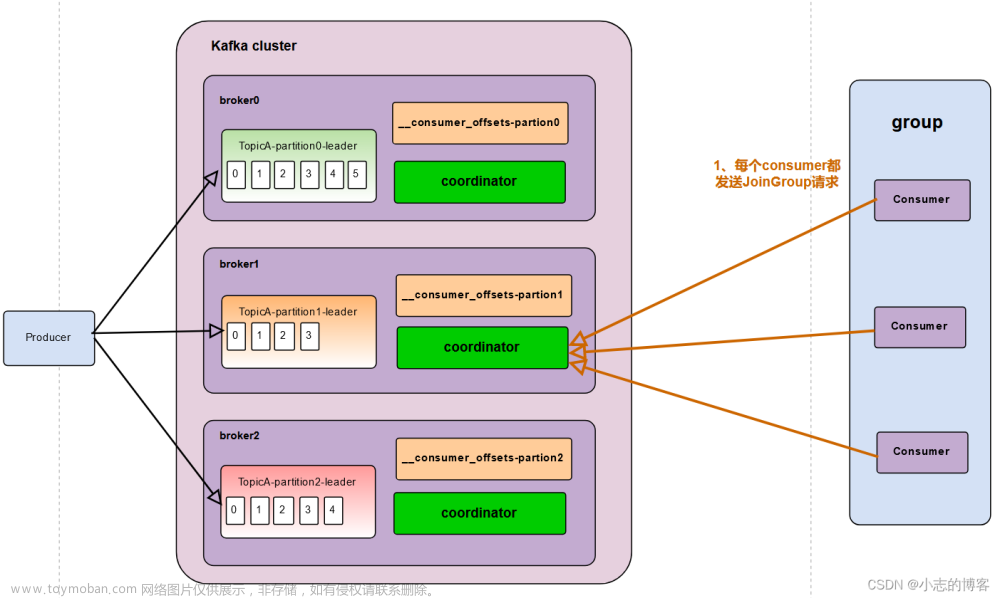
coordinator:辅组实现消费者组的初始化和分区的分配
coordinator节点选择=groupid的hashcode值%50(_consumer_offsets的分区数组)
例如:groupid的hashcode值=1,1%50=1,那么_consumer_offsets主题的1号分区,在哪个broker上,就选择这个节点的coordinator作为这个消费者组的老大,消费者组下的所有消费者提交offset的时候就往这个分区去提交offset
1)每个consumer都发送joinGroup请求
2)选出一个consumer作为leader
3)要把消费的topic情况发送给leader消费者
4)leader会负责指定消费方案
5)把消费方案分给coordinator
6)coordinator就把消费方案下发给各个consumer
7)每个消费者都会和coordinator保存心跳(默认3s),一旦超时(session.timeout.ms=45s),该消费者就会被一处,并触发再平衡,或者消费者处理消息的时间过长(max.poll.interval.ms5分钟),也会触发再平衡
Fetch.min.bytes每批次最小抓取大小,默认1字节
fetch.max.wait.ms一批数据最小值未达到的超时间,默认500ms
fetch.max.bytes每批次最大抓取大小,默认50m
max.poll.records一次拉取数据返回消息的最大条数,默认500条
 文章来源:https://www.toymoban.com/news/detail-539388.html
文章来源:https://www.toymoban.com/news/detail-539388.html
 文章来源地址https://www.toymoban.com/news/detail-539388.html
文章来源地址https://www.toymoban.com/news/detail-539388.html
到了这里,关于Kafka入门, 消费者工作流程(十八)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!