系统:Win10
环境:Pycharm/Vscode Python3.7
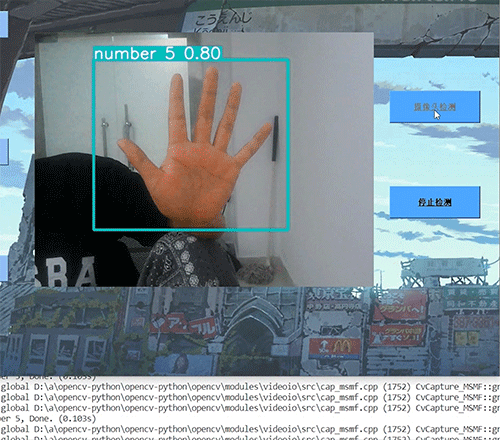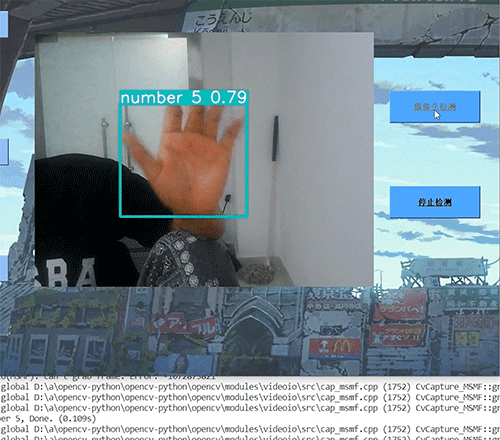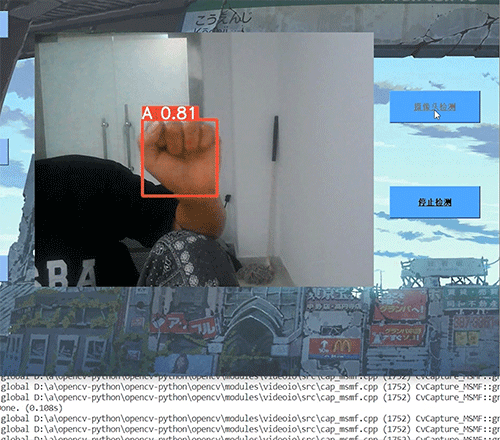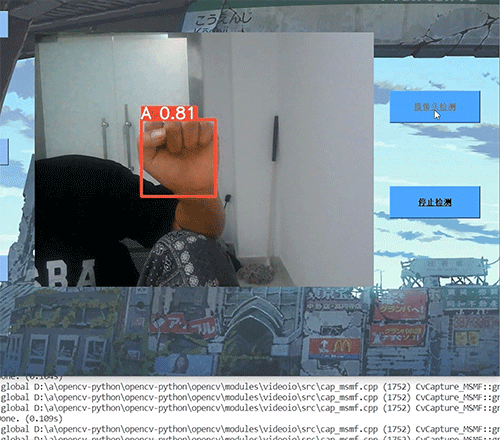
效果图:

部分代码如下:文章来源:https://www.toymoban.com/news/detail-539586.html
文章来源地址https://www.toymoban.com/news/detail-539586.html
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
#定义超参数
BATCH_SIZE = 16 # 每批处理的数据
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 是否用GPU还是CPU训练
import torch
# 检查是否有CUDA支持
if torch.cuda.is_available():
# 加载模型时将存储映射到CPU
saved_model_weights = torch.load('trained_model.pth', map_location=torch.device('cpu'))
else:
# 正常加载模型
saved_model_weights = torch.load('trained_model.pth')
EPOCHS = 20# 训练数据集的轮次
# 构建pipeline,对图像做处理
pipeline = transforms.Compose([
transforms.ToTensor(),# 将图片转换成tensor
transforms.Normalize((0.1307,),(0.3081,)) # 正则化降低模型复杂度
])
#下载、加载数据
from torch.utils.data import DataLoader
# 下载数据集
pipeline = transforms.Compose([
transforms.Grayscale(num_output_channels=1),
transforms.Resize((28, 28)), # 将图像大小调整为 28x28
transforms.ToTensor(),# 将图片转换成tensor
transforms.Normalize((0.1307,),(0.3081,)) # 正则化降低模型复杂度
])
# 加载完整的训练集
train_dataset = datasets.ImageFolder('mnist+', transform=pipeline)
# 定义训练集和测试集的比例
train_ratio = 0.8 # 训练集占总体的80%
test_ratio = 0.2 # 测试集占总体的20%
# 计算划分的大小
train_size = int(train_ratio * len(train_dataset))
test_size = len(train_dataset) - train_size
# 使用random_split函数进行划分
train_dataset, test_dataset = torch.utils.data.random_split(train_dataset, [train_size, test_size]) 到了这里,关于Python+CNN 手写公式识别计算系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!