目录
1、专栏大纲
🐋基础部分
🐋实战部分
🐋竞赛部分
2、代码附录
数据挖掘专栏,包含基本的数据挖掘算法分析和实战,数据挖掘竞赛干货分享等。数据挖掘是从大规模数据集中发现隐藏模式、关联和知识的过程。它结合了统计学、人工智能和数据库系统等领域的技术和方法,旨在通过分析大量数据来提取有用的信息,并用于预测、决策制定和问题解决等领域。
1、专栏大纲
🐋基础部分:
从基础的算法开始,
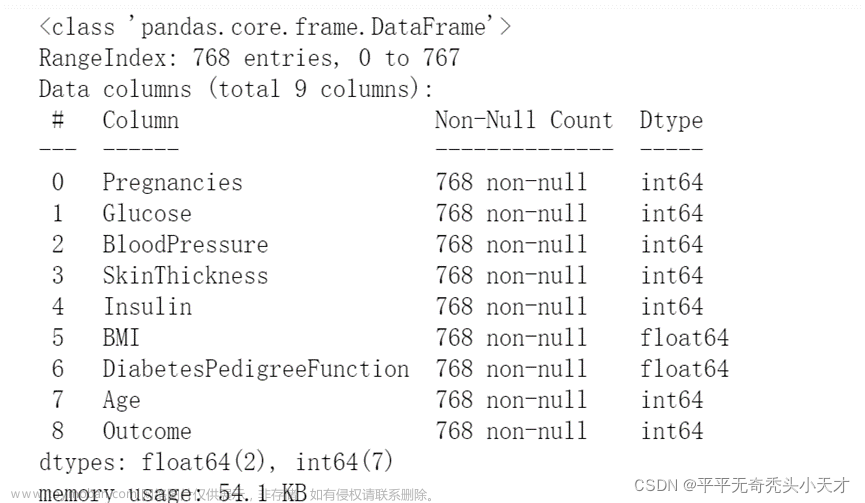
- 【数据挖掘基础】——数据挖掘能解决什么问题(1)
- 【数据挖掘基础】——理解业务和数据(2)
- 【数据挖掘基础】——数据的预处理(3)
- 【数据挖掘基础】——模型的评估(4)
- 【数据挖掘基础】——模型怎么解决业务需求(5)
- 【数据挖掘基础】——KNN算法+sklearn代码实现(6)
- 【数据挖掘基础】——决策树算法+代码实现(7)
- 【数据挖掘基础】——支持向量机(SVM)+代码实现(8)
- 【数据挖掘基础】——常见算法对比和选择(9)
文章中的常用的数据挖掘方法:
分类(Classification):分类是一种监督学习方法,通过训练数据集中已知类别的样本,建立一个分类模型,用于预测新样本所属的类别。常见的分类算法包括决策树、朴素贝叶斯、逻辑回归、支持向量机等。
聚类(Clustering):聚类是一种无监督学习方法,用于将数据集中的样本分成不同的组或聚类,使得组内的样本相似性较高,组间的相似性较低。常见的聚类算法包括K均值聚类、层次聚类、DBSCAN等。
关联规则挖掘(Association Rule Mining):关联规则挖掘用于发现数据中的频繁项集和关联规则。频繁项集表示经常同时出现的一组项,而关联规则表示项之间的关联关系。常见的关联规则挖掘算法包括Apriori算法、FP-Growth算法等。
异常检测(Anomaly Detection):异常检测用于识别与正常模式不符的异常数据点。这些异常数据可能表示潜在的异常行为、错误或欺诈。常见的异常检测方法包括基于统计的方法、基于聚类的方法、基于密度的方法等。
预测和回归(Prediction and Regression):预测和回归方法用于建立模型来预测数值型变量的值。常见的预测和回归算法包括线性回归、决策树回归、随机森林、梯度提升等。
文本挖掘(Text Mining):文本挖掘涉及从文本数据中提取有用的信息和知识。这包括文本分类、情感分析、主题建模、实体识别等技术。常见的文本挖掘方法包括词袋模型、TF-IDF、主题模型(如LDA)等。
推荐系统(Recommendation Systems):推荐系统用于根据用户的历史行为和偏好,推荐个性化的产品、服务或内容。推荐系统可以使用协同过滤、内容过滤、深度学习等方法来生成推荐结果。
文章中介绍一些数据挖掘技术,如决策树、随机森林、神经网络、支持向量机、主成分分析等。在不同的数据挖掘问题中选择不同的模型来解决实际的问题。
🐋实战部分:
- 【数据挖掘实战】——舆情分析:对微博文本进行情绪分类
- 【数据挖掘实战】——使用xgboost实现酒店信息消歧
- 【数据挖掘实战】——使用 word2vec 和 k-mean 聚类寻找相似城市_k-means 城市
- 【数据挖掘实战】——电力窃漏电用户自动识别(LM神经网络和决策树)
- 【数据挖掘实战】——航空公司客户价值分析(K-Means聚类案例)
- 【数据挖掘实战】——基于水色图像的水质评价(LM神经网络和决策树)
- 【数据挖掘实战】——家用电器用户行为分析及事件识别(BP神经网络)
数据挖掘可以解决许多问题,包括但不限于以下几个方面:
预测和分类:数据挖掘可以用于构建预测模型和分类器,通过分析历史数据,预测未来事件的可能结果。例如,可以使用数据挖掘来预测销售趋势、股票价格、客户流失率等。
聚类和分割:数据挖掘可以帮助将数据集分成不同的组或聚类,使得具有相似特征的数据点归为一类。这在市场细分、社交网络分析、图像分析等领域中非常有用。
关联规则发现:数据挖掘可以揭示数据之间的关联关系,找出经常同时出现的项集。例如,在购物篮分析中,可以通过挖掘购物记录中的关联规则,了解哪些商品经常一起购买。
异常检测:数据挖掘可以帮助识别与正常模式不符的异常数据点。这在金融欺诈检测、网络入侵检测等领域中具有重要意义。
文本挖掘:数据挖掘可以从大量的文本数据中提取有用的信息和知识。例如,可以通过文本挖掘来分析社交媒体上的用户情感、主题识别、信息提取等。
推荐系统:数据挖掘可以根据用户的历史行为和偏好,推荐个性化的产品、服务或内容。这在电子商务、社交媒体和音乐/电影推荐等领域中得到广泛应用。
部分的流程图:
 部分文章目录:
部分文章目录:

🐋竞赛部分:
持续更新中:
- 【数据挖掘实战】——科大讯飞:跨境广告ROI预测(Baseline)
- 【数据挖掘竞赛】——比赛的流程干货分享
- 【数据挖掘竞赛】——糖尿病遗传风险检测挑战赛(科大讯飞)
- 【数据挖掘竞赛】——汽车领域多语种迁移学习挑战赛(科大讯飞)
竞赛网站推荐:
Kaggle(https://www.kaggle.com):Kaggle 是最著名和最受欢迎的数据科学和机器学习竞赛平台。它提供了大量的竞赛项目,包括各种数据集和挑战,还有丰富的讨论和资源供学习和交流。
DataHack(https://datahack.analyticsvidhya.com):Analytics Vidhya 的 DataHack 是一个面向数据科学和机器学习的竞赛平台。它举办了各种竞赛,涵盖了广泛的主题,提供了丰富的数据集和挑战。
DrivenData(https://www.drivendata.org):DrivenData 是一个致力于利用数据科学和机器学习解决社会问题的竞赛平台。它的竞赛项目通常与社会公益相关,如医疗保健、环境保护等领域。
2、代码附录

大部分代码在文中。
订阅链接:文章来源:https://www.toymoban.com/news/detail-539622.html
数据挖掘从入门到实战文章来源地址https://www.toymoban.com/news/detail-539622.html
到了这里,关于【数据挖掘从入门到实战】——专栏导读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!