mongodb集群
MongoDB集群有好几种方式:,主从模式,副本集模式和分片的模式
其中主从模式基本不再使用,大多是后面两种
副本集模式
副本集模式主要是用于实现服务的高可用性,类型Redis的哨兵模式.
它主要是的特点:
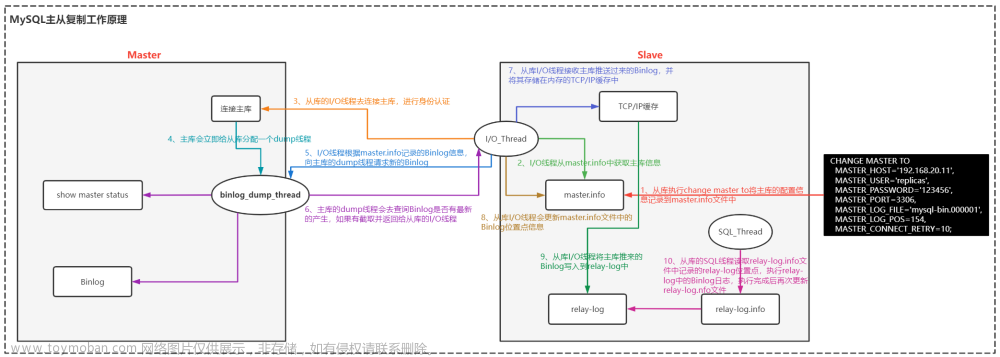
创建集群后会有主节点(primary)和从节点(secondary). 但从节点可以进行相应设置具有不同的功能.
主有有两方面功能:
- 主节点写入数据后从节点会进行数据同步/
- 在主节点故障时会发生新的选举进行替换.
同时实现了以下功能:
读写分离,主节点主要负责写操作,secondary负责读请求.
数据备份,在secondary上会有主节点对应的全量数据备份.
典型架构图:
其中有几种特殊的secondary节点类型:
- priority 0 将节点设置为这种类型,则是该节点不能升级为主节点也就是优先级最低/,用于多数据中心的情况.
- arbiter 该节点只参与投票,不能被选为主节点,且不会和主节点进行数据同步,主要是为了参与选举过程保证选票数是n/2+1
- Vote0 Mongodb 3.0里,复制集成员最多50个,参与Primary选举投票的成员最多7个,其他成员(Vote0)的vote属性必须设置为0,即不参与投票。
- Hidden Hidden节点不能被选为主(Priority为0),并且对Driver不可见。
- Delayed 该节点必须是hidden节点,并且他的数据要落后于primary一段时间,时间可以设置,主要是作为数据恢复备用。
primary与Scondary之间的数据同步:
两个节点之间的数据同步采用的是通过oplog方式进行,当然在集群初始化或者新加入的结点时,采用的全量复制方式。
在全量复制成功之后,当再有新数据写入后。
primary会向特殊的local.oplog.rs集合中写入oplog,就是执行的操作记录.然后secondary就会从主节点上读取到oplog,然后执行更新.
因oplog的数据会不断增加,local.oplog.rs被设置成为一个capped集合,当容量达到配置上限时,会将最旧的数据删除掉。另外考虑到oplog在Secondary上可能重复应用,oplog必须具有幂等性,即重复应用也会得到相同的结果。
Secondary初次同步数据时,会先进行init sync,从Primary(或其他数据更新的Secondary)同步全量数据,然后不断通过tailable cursor从Primary的local.oplog.rs集合里查询最新的oplog并应用到自身。
t sync过程包含如下步骤
T1时间,从Primary同步所有数据库的数据(local除外),通过listDatabases + listCollections + cloneCollection敏命令组合完成,假设T2时间完成所有操作。
从Primary应用[T1-T2]时间段内的所有oplog,可能部分操作已经包含在步骤1,但由于oplog的幂等性,可重复应用。
根据Primary各集合的index设置,在Secondary上为相应集合创建index。(每个集合_id的index已在步骤1中完成)。
oplog集合的大小应根据DB规模及应用写入需求合理配置,配置得太大,会造成存储空间的浪费;配置得太小,可能造成Secondary的init sync一直无法成功。比如在步骤1里由于DB数据太多、并且oplog配置太小,导致oplog不足以存储[T1, T2]时间内的所有oplog,这就Secondary无法从Primary上同步完整的数据集。
Primary选举:
复制集被reconfig
Secondary节点检测到Primary宕机时,会触发新Primary的选举
当有Primary节点主动stepDown(主动降级为Secondary)时,也会触发新的Primary选举.
复制集成员间默认每2s会发送一次心跳信息,如果10s未收到某个节点的心跳,则认为该节点已宕机;如果宕机的节点为Primary,Secondary(前提是可被选为Primary)会发起新的Primary选举。
节点优先级:
- 每个节点都倾向于投票给优先级最高的节点
- 优先级为0的节点不会主动发起Primary选举
- 当Primary发现有优先级更高Secondary,并且该Secondary的数据落后在10s内,则Primary会主动降级,让优先级更高的Secondary有成为Primary的机会。
只有更大多数投票节点间保持网络连通,才有机会被选Primary;如果Primary与大多数的节点断开连接,Primary会主动降级为Secondary。当发生网络分区时,可能在短时间内出现多个Primary,故Driver在写入时,最好设置『大多数成功』的策略,这样即使出现多个Primary,也只有一个Primary能成功写入大多数。
复制集的读写设置
默认情况下,复制集的所有请求都发到primary中,driver可以通过设置read perference来讲读请求路由到其他节点.
primary: 默认规则,所有读请求发到Primary
primaryPreferred: Primary优先,如果Primary不可达,请求Secondary
secondary: 所有的读请求都发到secondary
secondaryPreferred:Secondary优先,当所有Secondary不可达时,请求Primary
nearst: 所有读请求发送到最近的可达节点上,通过ping探测最近节点.
Write Concern:
默认情况下,Primary完成写操作即返回,Driver可通过设置[Write Concern(https://docs.mongodb.org/manual/core/write-concern/)来设置写成功的规则。
如下的write concern规则设置写必须在大多数节点上成功,超时时间为5s。
db.products.insert(
{ item: “envelopes”, qty : 100, type: “Clasp” },
{ writeConcern: { w: majority, wtimeout: 5000 } }
)
上面的设置方式是针对单个请求的,也可以修改副本集默认的write concern,这样就不用每个请求单独设置。
cfg = rs.conf()
cfg.settings = {}
cfg.settings.getLastErrorDefaults = { w: “majority”, wtimeout: 5000 }
rs.reconfig(cfg)
异常处理:
当主节点宕机,如果有数据未同步到secondary上,当之前的primary重新加入集群中的时候,如果新的primary上已经发生了写操作,那么旧的primary就要发生回滚操作,以保证数据集与新的primary的一致.
旧Primary将回滚的数据写到单独的rollback目录下,数据库管理员可根据需要使用mongorestore进行恢复。文章来源:https://www.toymoban.com/news/detail-539820.html
未完待续~文章来源地址https://www.toymoban.com/news/detail-539820.html
到了这里,关于mongodb集群工作原理学习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!