本方案已经开源到了 https://github.com/StarCompute/tftziku ,详细内容请访问Github.
本方案在esp32 下经过测试在tft屏幕上可以正常输出文字,也就是说经过了验证。
目录
说明
缘起
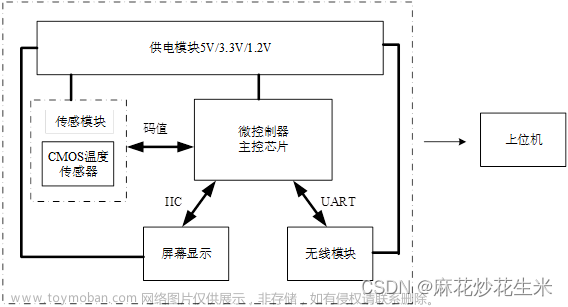
系统结构
软字库的创建
软字库包含的内容:
软字库的格式
字模的格式
软字库在单片机中的使用
在终端输出
通过单片机在tft屏幕显示
说明
本项目是为了在各种单片机使用中创建更方便易用的字库,配合使用了 ``TFT_eSPI`` 进行显示使用,实际上可以用于其他任何点阵屏。
缘起
我们都知道,要在单片机上使用汉字输出,都必须汉字点阵化,然后再集成到单片机中进行输出;然而这里有个弊病,就是你输出的汉字每次都必须使用类似于 PCtoLCD2018 这样的软件来处理,极其不方便;而如果单片机要同上位机进行文字通信的时候,上位机的文字其实不受限的,这个时候采取预处理文字的方式就不行了,虽然我自己采用过像素化进行通信,但是始终觉得非常不便。 事实上,文字的调整是个高频的事情,如果每次使用 PCtoLCD2018 来处理实在太繁琐了,因此就产生了一个基本问题:重复修改字体数据,这也同时提出了一个需求:使用软字库。 如果时光倒退无数年,会有专门卖 硬件字库 的,以及PC上类似于 UCDOS 这样软字库的东西。 单片机上各种中文的显示,大家常见的是U8G2这种东西,但是它的汉字非常不全面,基本用不起来。在使用 Tft_eSPI 的字库工具包 processing 过程中,网上有些教程误导我们先用 processing 创建vlw文件,再去转换成.h文件,最后编译进项目里面去。 这是一种完全的误导: - vlw 文件是可以被 tft_espi 项目直接使用的; - 无论是vlw还是.h格式的文件,如果是个别中文的处理毫无意义,而如果是完全的字符(类似于GB2312),这个vlw和.h文件都是非常巨大的,在我的esp32上是无法上传到flash空间中。
基于经验的积累和对于 tft_espi 的部分学习,尝试用自己的方式来创建包含 gb2312 字符集的字库,经过测试后发觉:自己创建的16号字体 GB2312 字符集整体只有507k,这个比vlw文件少了一半的空间占用。
并且, tft_espi 装载自己的vlw字库需要2秒,然后显示对应文字需要0.1x秒左右,而使用我自己创建字库利用tft_espi驱动显示同样的文字只需要0.28秒左右,整体性能提升已经达到了一个相对很高的程度。
从空间占用和显示速度上都b表现出了更优,为了方便大家更方便的进行单片机,所以把这个项目进行开源。
系统结构
软字库的创建
软字库包含的内容:
软字体用python进行创建,在本项目中是getunicode.py,它是把绝大部分能够显示出来的GB2312字符集包含进来了,然后包括进来了常见的大小写英文字母和字符(从chr(33)=chr(128)),由于GB18030的字库太大,所以是不可能使用GB18030,使用了GB2312,我们平常使用的文字基本都在这个字库中,例如“饕餮”这两个字都在GB2312中。
软字库的格式
- 软字体以x.font方式进行命名,采用纯文本进行存储。
- x.font文件被分成了4个部分:
- 前6位16进制表示总共存储了多少字符;
- 7-8位用10进制表示存储的是多少号字体,
- 9-xxxx*5位存储的是字符的unicode编码,为了节省存储空间,一个汉字采取的是u+4位unicode编码;例如"u3001u3002u30fbu02c9u02c7" 是“、。・ˉˇ”对应的存储;每个GB2312字符转化为5个字符进行存储。
- xxxx*5+1至xxxx*8存储的是每个字符对应的取字模数据的16进制编码
举例来说,假设我们的字库只有一个 “ 好 “ 字,用16号字体存储,那么它的整体内容如下:
00000116u597d100010fc10041008fc102420242025fe24204820282010202820442084a00040
如果用12好字体存储,那么存储内容如下::
00000112u597d200027c02040f880490049004fe091005100210051008b00
对比16号和12号字体::
000001 16 u597d 100010fc10041008fc102420242025fe24204820282010202820442084a00040 000001 12 u597d 200027c02040f880490049004fe091005100210051008b00
000001 表示 总共有1个字符 16和12表示存储的字号 u597d 是"好”字的unicode编码 再后面分别对应着
100010fc10041008fc102420242025fe24204820282010202820442084a00040
对应
{0x10,0x00,0x10,0xFC,0x10,0x04,0x10,0x08,0xFC,0x10,0x24,0x20,0x24,0x20,0x25,0xFE},
{0x24,0x20,0x48,0x20,0x28,0x20,0x10,0x20,0x28,0x20,0x44,0x20,0x84,0xA0,0x00,0x40},/*"好",0*/
而
200027c02040f880490049004fe091005100210051008b00
对应
{0x20,0x00,0x27,0xC0,0x20,0x40,0xF8,0x80,0x49,0x00,0x49,0x00,0x4F,0xE0,0x91,0x00},
{0x51,0x00,0x21,0x00,0x51,0x00,0x8B,0x00},/*"好",0*/
为了压缩存储内容,把0x10,0x00, 这种直接转化成了1000,这样的化,存储的内容就只有标志16进制格式的五分之二。
如果,这个字库存储的字符是 “你真好看啊!” ,它的整体内容如下::
00000612u4f60u771fu597du770bu554au00211400140027e024206940a10025402520252029202100230004007fc004003f8020803f8020803f802080ffe011002080200027c02040f880490049004fe091005100210051008b0003c07c0004007fc00800ffe020407fc0a0403fc020403fc00000eee0aa40abc0ad40ad40ab40abc0ea40ac40084008c0000000002000200020002000200000000000200000000000
经过整理后如下::
000006 12 u4f60 u771f u597d u770b u554a u0021 1400140027e024206940a10025402520252029202100230004007fc004003f8020803f8020803f802080ffe011002080200027c02040f880490049004fe091005100210051008b0003c07c0004007fc00800ffe020407fc0a0403fc020403fc00000eee0aa40abc0ad40ad40ab40abc0ea40ac40084008c0000000002000200020002000200000000000200000000000
掌握了这种格式的存储,就知道了如何获取到对应的内容,值得特别说明的是,为了方便计算,字模的16进制数据采取的是8位一个存储,12号字体其实可以认为是12*12个像素,但是存储的时候为了某种方便采取了16*12这种方式;所以一定程度来讲,这个字库还有压缩和提升性能的潜力可以挖掘;
在创建字库的时候,如果字符集里面有英文字母,将对英文字母补00进行操作,例如上面的"!" 它的unicode编码系统生产的是"u21",把它补0转换后就是"u0021". 字库中,字符的存储使用 ``u `` 一方面表示这是unicode 编码,另外一方面这个u也骑着分割符的重要作用,它能保证,这段编码被检索的时候不会重复,因为unicode编码不会一样,而如果没有使用 ``u `` ,只是存储 编码数字的话肯定会出现某个编码互相组合出现重复这种情况。
字模的格式
经过学习发现 TFT_eSPI 使用的vlw格式字库文件,其实是一种组合式的图片文件,而TFT_eSPI对于每个字符的显示其实就是动态取模。 本字库是提前对于字符取模,它采取把对应的字符画到图片上,然后获取每个位置的像素,每8个模 编码为16进制。取模顺序是从左到右,从上到下
软字库在单片机中的使用
字体文件在单片机中的使用,其实是一个逆向过程:
- 上传生成的字库到单片机中
- 输入要显示的汉字
- 读取x.font文件,读取前6位,获得总共有多少个字符;
- 再读取2位,确定字体对应的字号;
- 读取unicode字符集,判断是否同输入汉字的unicode匹配
- 利用匹配到的顺序,计算出字模的位置,依照字号获取对应长度的数据
- 把字模的16进制编码重新编码为二进制
- 利用TFT_eSPI 的 drawpix 方法把汉字输出到屏幕上(这里会有个方法计算能够显示多少汉字)
- 字库调用完成
.. 注意:: 英文字符的特殊性暂未处理。
由于英文基本都是半角符号,中文是全角符号,理论上英文的输出只有中文的一半,但是本字库暂时未处理英文的半角输出问题,全部是全角输出,后续再进行整理。
在终端输出
String strBinDisplay = getPixBinStrFromString("这是一个软字体的显示你看看再多如何显示出来啊!你说你项羽突然的自我伍佰向天再借五百年");
// 下面代码在终端输出文字点阵。
Serial.println(strBinDisplay.length());
for (int i = 0; i < strBinDisplay.length(); i++)
{
if (i % 16 == 0)
Serial.print("\r\n");
if (strBinDisplay[i] == '0')
Serial.print(' ');
if (strBinDisplay[i] == '1')
Serial.print(strBinDisplay[i]);
}
终端显示如下:::
1
1 111111
1 1
1 1
111111 1
1 1 1
1 1 1
1 1 11111111
1 1 1
1 1 1
1 1 1
1 1
1 1 1
1 1 1
1 1 1 1
1
1 1
1 1
1 1
1111111 11111
1 1 1
1 1 1 1
1 1 1 1
111111 1
1 1
1 1 1
111 1 1
11111 1 1
1 1 1 1
1 1 1
1 1 1
1 1 1
通过单片机在tft屏幕显示
// 下面代码在TFT屏幕输出文字
int pX = 16;
int pY = 0;
int fontsize=16; //字号
int amountDisplay=10; //每行显示多少汉字
int singleStrPixsAmount=fontsize*fontsize;
for (int i = 0; i < strBinDisplay.length(); i++)
{
// 这里必须有特别的说明,每个字符的像素点总数是singleStrPixsAmount=fontsize*fontsize,如果是16号字体就是256个;
// 每行显示10个字,那么他们到一点阶段就必须换行,x坐标归0,y坐标必须加上字体对应的像素
// 对于pX,每显示fontsize个像素后就必须字体归到起始点,注意每显示n字符后,这个起始点就必须加上fontsize*n这个起始值
// 同时对于换行也必须处理。
pX=int(i%fontsize)+int(i/(singleStrPixsAmount))*fontsize-int(i/(singleStrPixsAmount*amountDisplay))*fontsize*amountDisplay;
// 对于pY,每fontsize个像素后+1,每singleStrPixsAmount个像素后归0,同时每换一行,pY要加上fontsize个像素;
pY =int((i-int(i/singleStrPixsAmount)*singleStrPixsAmount)/fontsize)+int(i/(singleStrPixsAmount*amountDisplay))*fontsize;
if (strBinDisplay[i] == '1')
{
tft.drawPixel(pX, pY, TFT_GREEN);
}
}
文章来源:https://www.toymoban.com/news/detail-539908.html
 文章来源地址https://www.toymoban.com/news/detail-539908.html
文章来源地址https://www.toymoban.com/news/detail-539908.html
到了这里,关于在esp32(esp8266) 提供软字库显示中文的解决方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!