目录
1、数据仓库概念
2、项目需求及架构设计
3、集群资源规划设计
4、车辆日志字段说明
1、数据仓库概念
数据仓库(Data Warehouse)是为企业提供数据支持,用以协助企业制定决策、改进业务流程和提高产品质量等方面的工具。它可以接收多种类型的输入数据,如业务数据、日志数据和爬虫数据等。然而,在本项目中,我们只对日志数据进行统计和分析。
具体而言,我们将主要关注汽车行驶过程中传感器数据这一特定类型的日志数据,它记录了汽车在运行过程中各个传感器的使用情况以及相关数据。这些数据对于我们改进汽车性能、诊断问题以及分析驾驶行为等都非常重要。

2、项目需求及架构设计
- 项目需求:

- 技术选型:

- 核心架构:

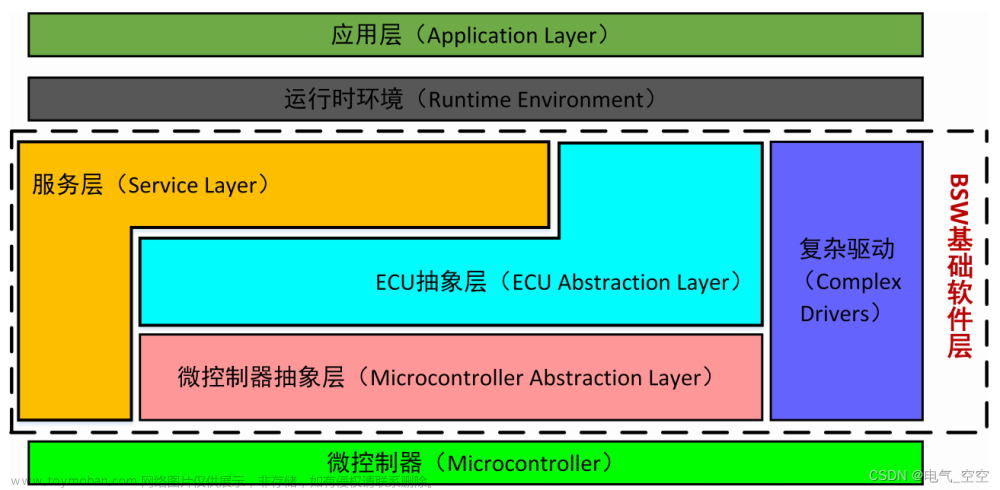
标记车辆的维度信息(定点DataX全量同步),先将数据上传到HFDS,用Hive创建表格映射;汽车行驶日志,用Flume上传至数仓,ODS对数据进行保存,在DWS中完成公共子查询,最后将ADS导出到Mysql,进行机器学习。
- 框架版本选型

本项目使用的Apache框架版本:

- 服务器选型

- 集群规模

3、集群资源规划设计
在企业中通常会搭建一套生产集群和一套测试集群。生产集群运行生产任务,测试集群用于上线前代码编写和测试。
- 生产集群
参考腾讯云EMR官方推荐部署

- Master节点:管理节点,保证集群的调度正常进行;主要部署NameNode、ResourceManager、HMaster等进程;非HA模式下数量为1,HA模式下数量为2。
- Core节点:为计算及存储节点,您在HDFS中的数据全部存储于core节点中,因此为了保证数据安全,扩容core节点后不允许缩容;主要部署DataNode、NodeManager、RegionServer等进程。非HA模式下数量≥2,HA模式下数量≥3。
- Common节点:为HA集群Master节点提供数据共享同步以及高可用容错服务;主要部署分布式协调器组件,如ZooKeeper、JournalNode等节点。非HA模式数量为0,HA模式下数量≥3。
消耗内存的分开部署。
数据传输数据比较紧密的放在一起(Kafka、clickhouse)。
客户端尽量放在一到两台服务器上,方便外部访问。
有依赖关系的尽量放到同一台服务器(例如:Ds-worker和hive/spark)。
| Master |
Master |
core |
core |
core |
common |
common |
common |
| nn |
nn |
dn |
dn |
dn |
JournalNode |
JournalNode |
JournalNode |
| rm |
rm |
nm |
nm |
nm |
|||
| zk |
zk |
zk |
|||||
| hive |
hive |
hive |
hive |
hive |
|||
| kafka |
kafka |
kafka |
|||||
| spark |
spark |
spark |
spark |
spark |
|||
| datax |
datax |
datax |
datax |
datax |
|||
| Ds-master |
Ds-master |
Ds-worker |
Ds-worker |
Ds-worker |
|||
| mysql |
mysql |
||||||
| flume |
flume |
flume |
测试集群服务器规划
| 服务名称 |
子服务 |
服务器 hadoop102 |
服务器 hadoop103 |
服务器 hadoop104 |
| HDFS |
NameNode |
√ |
||
| DataNode |
√ |
√ |
√ |
|
| SecondaryNameNode |
√ |
|||
| Yarn |
NodeManager |
√ |
√ |
√ |
| Resourcemanager |
√ |
|||
| Zookeeper |
Zookeeper Server |
√ |
√ |
√ |
| Flume(采集日志) |
Flume |
√ |
√ |
|
| Kafka |
Kafka |
√ |
√ |
√ |
| Flume (消费Kafka日志) |
Flume |
√ |
||
| Hive |
√ |
√ |
√ |
|
| MySQL |
MySQL |
√ |
||
| DataX |
√ |
√ |
√ |
|
| Spark |
√ |
√ |
√ |
|
| DolphinScheduler |
ApiApplicationServer |
√ |
||
| AlertServer |
√ |
|||
| MasterServer |
√ |
|||
| WorkerServer |
√ |
√ |
√ |
|
| LoggerServer |
√ |
√ |
√ |
|
| 服务数总计 |
15 |
11 |
11 |
4、车辆日志字段说明
本次处理的数据全部为车辆日志数据,即车辆在行驶过程中每30秒发送的车辆自身状态的记录。除了日志数据之外,我们还需要处理车辆维度数据,这些数据存储在数据库中。
车辆日志数据对于我们分析和预测车辆性能、维护需求和问题诊断等方面至关重要。而车辆维度数据则提供了有关车辆的其他信息,如生产日期、品牌和型号等,这些信息可以帮助我们更好地理解车辆的性能和特性。在本次数据处理中,我们将同时处理这两类数据。
车辆日志数据
车辆日志数据为Json格式的文本文件。每行为一个完整的Json串,其中字段含义如下:
| 字段名 |
字段类型 |
| vin |
车辆唯一编码 |
| timestamp |
日志采集时间 |
| car_status |
车辆状态 |
| charg_status |
充电状态 |
| execution_mode |
运行模式 |
| velocity |
车速 |
| mileage |
里程 |
| voltage |
总电压 |
| electric_current |
总电流 |
| soc |
SOC |
| dc_status |
DC-DC状态 |
| gear |
挡位 |
| insulation_resistance |
绝缘电阻 |
| motor_count |
驱动电机个数 |
| motor_list |
驱动电机列表 |
| fuel_cell_voltage |
燃料电池电压 |
| fuel_cell_current |
燃料电池电流 |
| fuel_cell_consume_rate |
燃料消耗率 |
| fuel_cell_temperature_probe_count |
燃料电池温度探针总数 |
| fuel_cell_temperature |
燃料电池温度值 |
| fuel_cell_max_temperature |
氢系统中最高温度 |
| fuel_cell_max_temperature_probe_id |
氢系统中最高温度探针号 |
| fuel_cell_max_hydrogen_consistency |
氢气最高浓度 |
| fuel_cell_max_hydrogen_consistency_probe_id |
氢气最高浓度传感器代号 |
| fuel_cell_max_hydrogen_pressure |
氢气最高压力 |
| fuel_cell_max_hydrogen_pressure_probe_id |
氢气最高压力传感器代号 |
| fuel_cell_dc_status |
高压DC-DC状态 |
| engine_status |
发动机状态 |
| crankshaft_speed |
曲轴转速 |
| fuel_consume_rate |
燃料消耗率 |
| max_voltage_battery_pack_id |
最高电压电池子系统号 |
| max_voltage_battery_id |
最高电压电池单体代号 |
| max_voltage |
电池单体电压最高值 |
| min_temperature_subsystem_id |
最低电压电池子系统号 |
| min_voltage_battery_id |
最低电压电池单体代号 |
| min_voltage |
电池单体电压最低值 |
| max_temperature_subsystem_id |
最高温度子系统号 |
| max_temperature_probe_id |
最高温度探针号 |
| max_temperature |
最高温度值 |
| min_voltage_battery_pack_id |
最低温度子系统号 |
| min_temperature_probe_id |
最低温度探针号 |
| min_temperature |
最低温度值 |
| alarm_level |
最高报警等级 |
| alarm_sign |
通用报警标志 |
| custom_battery_alarm_count |
可充电储能装置故障总数N1 |
| custom_battery_alarm_list |
可充电储能装置故障代码列表 |
| custom_motor_alarm_count |
驱动电机故障总数N2 |
| custom_motor_alarm_list |
驱动电机故障代码列表 |
| custom_engine_alarm_count |
发动机故障总数N3 |
| custom_engine_alarm_list |
发动机故障代码列表 |
| other_alarm_count |
其他故障总数N4 |
| other_alarm_list |
其他故障代码列表 |
| battery_count |
单体电池总数 |
| battery_pack_count |
单体电池包总数 |
| battery_voltages |
单体电池电压值列表 |
| battery_temperature_probe_count |
单体电池温度探针总数 |
| battery_pack_temperature_count |
单体电池包总数 |
| battery_temperatures |
单体电池温度值列表 |
其中电机列表为嵌套字段,其含义如下:
| 字段名 |
字段说明 |
| id |
驱动电机序号 |
| status |
驱动电机状态 |
| controller_temperature |
驱动电机控制器温度 |
| rev |
驱动电机转速 |
| torque |
驱动电机转矩 |
| temperature |
驱动电机温度 |
| voltage |
电机控制器输入电压 |
| electric_current |
电机控制器直流母线电流 |
车辆维度数据
| 字段名 |
字段说明 |
| id |
车辆唯一编码 |
| type_id |
车型ID |
| type |
车型 |
| sale_type |
销售车型 |
| trademark |
品牌 |
| company |
厂商 |
| seating_capacity |
准载人数 |
| power_type |
车辆动力类型 |
| charge_type |
车辆支持充电类型 |
| category |
车辆分类 |
| weight_kg |
总质量(kg) |
| warranty |
整车质保期(年/万公里) |
本项目参考尚硅谷课程:
【尚硅谷大数据项目之新能源汽车数仓,离线数据仓库项目实战】 https://www.bilibili.com/video/BV1uF411o74x/?p=7&share_source=copy_web&vd_source=2d7beee727c4b0510439779fd78c22f7
附录: 基于Stable Diffusion生成的新能源Tesla。文章来源:https://www.toymoban.com/news/detail-540059.html
 文章来源地址https://www.toymoban.com/news/detail-540059.html
文章来源地址https://www.toymoban.com/news/detail-540059.html
到了这里,关于【从0开始离线数仓项目】——新能源汽车数仓项目介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!