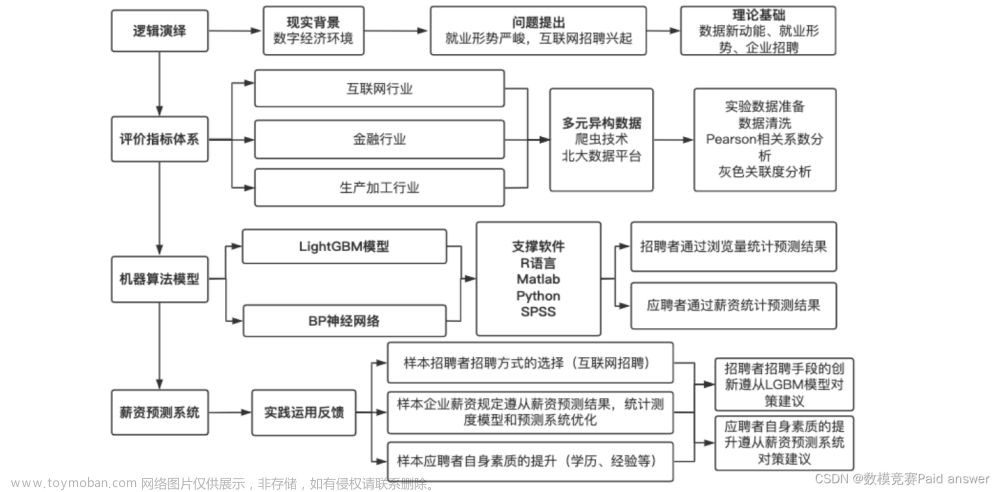
1、第一篇提出BP神经网络的论文是哪一篇?
最初是86年,Rumelhart和McCelland领导的科学家小组在《平行分布式处理》一书中,对具有非线性连续变换函数的多层感知器的误差反向传播BP算法进行了详尽的分析,实现了Minsky关于多层网络的设想。
一般引用的话,无需引用第一篇,只需引用介绍BP网络的文献即可。最开始的文献往往理论不完善。反而阅读意义不大。
谷歌人工智能写作项目:小发猫

2、BP神经网络的可行性分析
神经网络的是我的毕业论文的一部分
4.人工神经网络
人的思维有逻辑性和直观性两种不同的基本方式bp神经网络论文。逻辑性的思维是指根据逻辑规则进行推理的过程;它先将信息化成概念,并用符号表示,然后,根据符号运算按串行模式进行逻辑推理。这一过程可以写成串行的指令,让计算机执行。然而,直观性的思维是将分布式存储的信息综合起来,结果是忽然间产生想法或解决问题的办法。这种思维方式的根本之点在于以下两点:1.信息是通过神经元上的兴奋模式分布在网络上;2.信息处理是通过神经元之间同时相互作用的动态过程来完成的。
人工神经网络就是模拟人思维的第二种方式。这是一个非线性动力学系统,其特色在于信息的分布式存储和并行协同处理。虽然单个神经元的结构极其简单,功能有限,但大量神经元构成的网络系统所能实现的行为却是极其丰富多彩的。
4.1人工神经网络学习的原理
人工神经网络首先要以一定的学习准则进行学习,然后才能工作。现以人工神经网络对手写“A”、“B”两个字母的识别为例进行说明,规定当“A”输入网络时,应该输出“1”,而当输入为“B”时,输出为“0”。
所以网络学习的准则应该是:如果网络做出错误的判决,则通过网络的学习,应使得网络减少下次犯同样错误的可能性。首先,给网络的各连接权值赋予(0,1)区间内的随机值,将“A”所对应的图像模式输入给网络,网络将输入模式加权求和、与门限比较、再进行非线性运算,得到网络的输出。在此情况下,网络输出为“1”和“0”的概率各为50%,也就是说是完全随机的。这时如果输出为“1”(结果正确),则使连接权值增大,以便使网络再次遇到“A”模式输入时,仍然能做出正确的判断。
如果输出为“0”(即结果错误),则把网络连接权值朝着减小综合输入加权值的方向调整,其目的在于使网络下次再遇到“A”模式输入时,减小犯同样错误的可能性。如此操作调整,当给网络轮番输入若干个手写字母“A”、“B”后,经过网络按以上学习方法进行若干次学习后,网络判断的正确率将大大提高。这说明网络对这两个模式的学习已经获得了成功,它已将这两个模式分布地记忆在网络的各个连接权值上。当网络再次遇到其中任何一个模式时,能够做出迅速、准确的判断和识别。一般说来,网络中所含的神经元个数越多,则它能记忆、识别的模式也就越多。
4.2人工神经网络的优缺点
人工神经网络由于模拟了大脑神经元的组织方式而具有了人脑功能的一些基本特征,为人工智能的研究开辟了新的途径,神经网络具有的优点在于:
(1)并行分布性处理
因为人工神经网络中的神经元排列并不是杂乱无章的,往往是分层或以一种有规律的序列排列,信号可以同时到达一批神经元的输入端,这种结构非常适合并行计算。同时如果将每一个神经元看作是一个小的处理单元,则整个系统可以是一个分布式计算系统,这样就避免了以往的“匹配冲突”,“组合爆炸”和“无穷递归”等题,推理速度快。
(2)可学习性
一个相对很小的人工神经网络可存储大量的专家知识,并且能根据学习算法,或者利用样本指导系统来模拟现实环境(称为有教师学习),或者对输入进行自适应学习(称为无教师学习),不断地自动学习,完善知识的存储。
(3)鲁棒性和容错性
由于采用大量的神经元及其相互连接,具有联想记忆与联想映射能力,可以增强专家系统的容错能力,人工神经网络中少量的神经元发生失效或错误,不会对系统整体功能带来严重的影响。而且克服了传统专家系统中存在的“知识窄台阶”问题。
(4)泛化能力
人工神经网络是一类大规模的非线形系统,这就提供了系统自组织和协同的潜力。它能充分逼近复杂的非线形关系。当输入发生较小变化,其输出能够与原输入产生的输出保持相当小的差距。
(5)具有统一的内部知识表示形式,任何知识规则都可以通过对范例的学习存储于同一个神经网络的各连接权值中,便于知识库的组织管理,通用性强。
虽然人工神经网络有很多优点,但基于其固有的内在机理,人工神经网络也不可避免的存在自己的弱点:
(1)最严重的问题是没能力来解释自己的推理过程和推理依据。
(2)神经网络不能向用户提出必要的询问,而且当数据不充分的时候,神经网络就无法进行工作。
(3)神经网络把一切问题的特征都变为数字,把一切推理都变为数值计算,其结果势必是丢失信息。
(4)神经网络的理论和学习算法还有待于进一步完善和提高。
4.3神经网络的发展趋势及在柴油机故障诊断中的可行性
神经网络为现代复杂大系统的状态监测和故障诊断提供了全新的理论方法和技术实现手段。神经网络专家系统是一类新的知识表达体系,与传统专家系统的高层逻辑模型不同,它是一种低层数值模型,信息处理是通过大量的简单处理元件(结点) 之间的相互作用而进行的。由于它的分布式信息保持方式,为专家系统知识的获取与表达以及推理提供了全新的方式。它将逻辑推理与数值运算相结合,利用神经网络的学习功能、联想记忆功能、分布式并行信息处理功能,解决诊断系统中的不确定性知识表示、获取和并行推理等问题。通过对经验样本的学习,将专家知识以权值和阈值的形式存储在网络中,并且利用网络的信息保持性来完成不精确诊断推理,较好地模拟了专家凭经验、直觉而不是复杂的计算的推理过程。
但是,该技术是一个多学科知识交叉应用的领域,是一个不十分成熟的学科。一方面,装备的故障相当复杂;另一方面,人工神经网络本身尚有诸多不足之处:
(1)受限于脑科学的已有研究成果。由于生理实验的困难性,目前对于人脑思维与记忆机制的认识还很肤浅。
(2)尚未建立起完整成熟的理论体系。目前已提出了众多的人工神经网络模型,归纳起来,这些模型一般都是一个由结点及其互连构成的有向拓扑网,结点间互连强度所构成的矩阵,可通过某种学习策略建立起来。但仅这一共性,不足以构成一个完整的体系。这些学习策略大多是各行其是而无法统一于一个完整的框架之中。
(3)带有浓厚的策略色彩。这是在没有统一的基础理论支持下,为解决某些应用,而诱发出的自然结果。
(4)与传统计算技术的接口不成熟。人工神经网络技术决不能全面替代传统计算技术,而只能在某些方面与之互补,从而需要进一步解决与传统计算技术的接口问题,才能获得自身的发展。
虽然人工神经网络目前存在诸多不足,但是神经网络和传统专家系统相结合的智能故障诊断技术仍将是以后研究与应用的热点。它最大限度地发挥两者的优势。神经网络擅长数值计算,适合进行浅层次的经验推理;专家系统的特点是符号推理,适合进行深层次的逻辑推理。智能系统以并行工作方式运行,既扩大了状态监测和故障诊断的范围,又可满足状态监测和故障诊断的实时性要求。既强调符号推理,又注重数值计算,因此能适应当前故障诊断系统的基本特征和发展趋势。随着人工神经网络的不断发展与完善,它将在智能故障诊断中得到广泛的应用。
根据神经网络上述的各类优缺点,目前有将神经网络与传统的专家系统结合起来的研究倾向,建造所谓的神经网络专家系统。理论分析与使用实践表明,神经网络专家系统较好地结合了两者的优点而得到更广泛的研究和应用。
离心式制冷压缩机的构造和工作原理与离心式鼓风机极为相似。但它的工作原理与活塞式压缩机有根本的区别,它不是利用汽缸容积减小的方式来提高汽体的压力,而是依靠动能的变化来提高汽体压力。离心式压缩机具有带叶片的工作轮,当工作轮转动时,叶片就带动汽体运动或者使汽体得到动能,然后使部分动能转化为压力能从而提高汽体的压力。这种压缩机由于它工作时不断地将制冷剂蒸汽吸入,又不断地沿半径方向被甩出去,所以称这种型式的压缩机为离心式压缩机。其中根据压缩机中安装的工作轮数量的多少,分为单级式和多级式。如果只有一个工作轮,就称为单级离心式压缩机,如果是由几个工作轮串联而组成,就称为多级离心式压缩机。在空调中,由于压力增高较少,所以一般都是采用单级,其它方面所用的离心式制冷压缩机大都是多级的。单级离心式制冷压缩机的构造主要由工作轮、扩压器和蜗壳等所组成。 压缩机工作时制冷剂蒸汽由吸汽口轴向进入吸汽室,并在吸汽室的导流作用引导由蒸发器(或中间冷却器)来的制冷剂蒸汽均匀地进入高速旋转的工作轮3(工作轮也称叶轮,它是离心式制冷压缩机的重要部件,因为只有通过工作轮才能将能量传给汽体)。汽体在叶片作用下,一边跟着工作轮作高速旋转,一边由于受离心力的作用,在叶片槽道中作扩压流动,从而使汽体的压力和速度都得到提高。由工作轮出来的汽体再进入截面积逐渐扩大的扩压器4(因为汽体从工作轮流出时具有较高的流速,扩压器便把动能部分地转化为压力能,从而提高汽体的压力)。汽体流过扩压器时速度减小,而压力则进一步提高。经扩压器后汽体汇集到蜗壳中,再经排气口引导至中间冷却器或冷凝器中。
二、离心式制冷压缩机的特点与特性
离心式制冷压缩机与活塞式制冷压缩机相比较,具有下列优点:
(1)单机制冷量大,在制冷量相同时它的体积小,占地面积少,重量较活塞式轻5~8倍。
(2)由于它没有汽阀活塞环等易损部件,又没有曲柄连杆机构,因而工作可靠、运转平稳、噪音小、操作简单、维护费用低。
(3)工作轮和机壳之间没有摩擦,无需润滑。故制冷剂蒸汽与润滑油不接触,从而提高了蒸发器和冷凝器的传热性能。
(4)能经济方便的调节制冷量且调节的范围较大。
(5)对制冷剂的适应性差,一台结构一定的离心式制冷压缩机只能适应一种制冷剂。
(6)由于适宜采用分子量比较大的制冷剂,故只适用于大制冷量,一般都在25~30万大卡/时以上。如制冷量太少,则要求流量小,流道窄,从而使流动阻力大,效率低。但近年来经过不断改进,用于空调的离心式制冷压缩机,单机制冷量可以小到10万大卡/时左右。
制冷与冷凝温度、蒸发温度的关系。
由物理学可知,回转体的动量矩的变化等于外力矩,则
T=m(C2UR2-C1UR1)
两边都乘以角速度ω,得
Tω=m(C2UωR2-C1UωR1)
也就是说主轴上的外加功率N为:
N=m(U2C2U-U1C1U)
上式两边同除以m则得叶轮给予单位质量制冷剂蒸汽的功即叶轮的理论能量头。 U2 C2
ω2 C2U R1 R2 ω1 C1 U1 C2r β 离心式制冷压缩机的特性是指理论能量头与流量之间变化关系,也可以表示成制冷
W=U2C2U-U1C1U≈U2C2U
(因为进口C1U≈0)
又C2U=U2-C2rctgβ C2r=Vυ1/(A2υ2)
故有
W= U22(1-
Vυ1
ctgβ)
A2υ2U2
式中:V—叶轮吸入蒸汽的容积流量(m3/s)
υ1υ2 ——分别为叶轮入口和出口处的蒸汽比容(m3/kg)
A2、U2—叶轮外缘出口面积(m2)与圆周速度(m/s)
β—叶片安装角
由上式可见,理论能量头W与压缩机结构、转速、冷凝温度、蒸发温度及叶轮吸入蒸汽容积流量有关。对于结构一定、转速一定的压缩机来说,U2、A2、β皆为常量,则理论能量头W仅与流量V、蒸发温度、冷凝温度有关。
按照离心式制冷压缩机的特性,宜采用分子量比较大的制冷剂,目前离心式制冷机所用的制冷剂有F—11、F—12、F—22、F—113和F—114等。我国目前在空调用离心式压缩机中应用得最广泛的是F—11和F—12,且通常是在蒸发温度不太低和大制冷量的情况下,选用离心式制冷压缩机。此外,在石油化学工业中离心式的制冷压缩机则采用丙烯、乙烯作为制冷剂,只有制冷量特别大的离心式压缩机才用氨作为制冷剂。
三、离心式制冷压缩机的调节
离心式制冷压缩机和其它制冷设备共同构成一个能量供给与消耗的统一系统。制冷机组在运行时,只有当通过压缩机的制冷剂的流量与通过设备的流量相等时,以及压缩机所产生的能量头与制冷设备的阻力相适应时,制冷系统的工况才能保持稳定。但是制冷机的负荷总是随外界条件与用户对冷量的使用情况而变化的,因此为了适应用户对冷负荷变化的需要和安全经济运行,就需要根据外界的变化对制冷机组进行调节,离心式制冷机组制冷量的调节有:1°改变压缩机的转速;2°采用可转动的进口导叶;3°改变冷凝器的进水量;4°进汽节流等几种方式,其中最常用的是转动进口导叶调节和进汽节流两种调节方法。所谓转动进口导叶调节,就是转动压缩机进口处的导流叶片以使进入到叶轮去的汽体产生旋绕,从而使工作轮加给汽体的动能发生变化来调节制冷量。所谓进汽节流调节,就是在压缩机前的进汽管道上安装一个调节阀,如要改变压缩机的工况时,就调节阀门的大小,通过节流使压缩机进口的压力降低,从而实现调节制冷量。离心式压缩机制冷量的调节最经济有效的方法就是改变进口导叶角度,以改变蒸汽进入叶轮的速度方向(C1U)和流量V。但流量V必须控制在稳定工作范围内,以免效率下降。
3、天津大学撤销抄袭论文人学位了吗?
2018年6月21日,天津大学建筑工程学院发出通报,撤销抄袭论文的2008届建筑与土木工程专业在职研究生李瑞锋硕士学位。
通报称:
近期,学院接到电话举报,反映我院2008届在职研究生李瑞锋硕士学位论文涉嫌抄袭。学院对此事高度重视,成立了调查小组对情况进行核实认定,经调查李瑞锋硕士学位论文抄袭情况属实。
依据《天津大学研究生学术规范》,天津大学学位评定委员会第八分委会于2018年6月12日召开第103次会议,会上讨论了李瑞锋硕士学位论文抄袭情况和处理意见,一致通过撤销李瑞锋原授予学位、追回李瑞锋已授予工程硕士学位证书的决定,并已报请学校学位评定委员会批准。
近日,有网友称,天津大学一篇硕士学位论文涉嫌大面积抄袭内蒙古农业大学的一篇硕士学位论文。
这两篇论文分别是天津大学建筑工程学院建筑与土木工程2008届硕士毕业生李瑞锋的硕士学位论文《BP神经网络在现场混凝土强度预测中的应用研究》(以下简称“李瑞锋论文”)与内蒙古农业大学农业水土工程2005届硕士毕业生武欣慧的硕士学位论文《基于人工神经网络的普通混凝土强度预测的研究》(以下简称“武欣慧论文”)。
武欣慧论文完成于2005年5月,李瑞锋论文的完成时间是2008年5月,从时间上看,李瑞锋论文比武欣慧论文完成时间晚了3年。
澎湃新闻记者从中国知网上下载了上述两篇论文,仔细比对后发现,两篇论文从目录到正文内容都高度雷同,74条参考文献从书名、出版时间到引用的页码都毫无差别。
值得注意的是,李瑞锋论文在“致谢”部分还特别感谢了彼时已成为内蒙古农业大学副教授的武欣慧。
针对李瑞锋论文涉嫌抄袭武欣慧论文并致谢武欣慧一事,近日,澎湃新闻联系到武欣慧了解求证。目前在内蒙古农业大学林学院任教的武欣慧告诉澎湃新闻,她完全不认识李瑞锋,自己的硕士学位论文系原创,对是否被他人抄袭情况并不知情。
比对两篇论文后发现,两篇论文的题目虽然不完全相同,但都以神经网络对混凝土强度的预测应用为研究对象。
两篇论文的中文摘要部分极度相似。武欣慧论文的中文摘要分为两个自然段,具体内容为:
“抗压强度是混凝土最重要的性能之一,是混凝土质量控制的核心内容,同时也是结构设计和施工的重要依据。规范规定评定结构构件的混凝土强度需标准养护28天才能获得,不能满足现代化施工的时间要求,同时又可能留下隐患。因此,发展混凝土强度早期快速测定技术,提高预测精度具有重大意义。
“借鉴国内外有关混凝土强度预测的研究成果,结合人工神经网络基本原理,运用MATLAB神经网络工具箱,就网络的输入向量、网络结构、传递函数及其它参数的选择展开研究。在此基础上,选择内蒙古中西部地区三座野外变电站制作大量同条件养护标准试件,作为网络模型的训练样本和测试样本,分别运用基本BP算法、附加动量因子的自适应调整学习率算法和L—M算法三种方法训练网络,经大量试算和仿真结果比对,最终利用L—M算法建立网络结构合理、收敛速度快、精度高的满足工程要求的普通混凝土强度预测模型,与多元线性回归模型预测结果相比,BP网络模型有更高的精度,将预测误差控制在3%以内,可以极大程度上避免目前混凝土施工中存在的强度预测偏差较大的问题。”
的用电,同时能提高供电电压质量以及供电可靠性。乌拉特前旗气象局提供的30年(1971至2000)气象资料气温统计结果见表4。在本研究中,87组样本取自于本站1#、2#、3#主变压器基础及电缆沟。”
4、BP神经网络的发展历史
人工神经网络早期的研究工作应追溯至上世纪40年代。下面以时间顺序,以著名的人物或某一方面突出的研究成果为线索,简要介绍人工神经网络的发展历史。
1943年,心理学家W·Mcculloch和数理逻辑学家W·Pitts在分析、总结神经元基本特性的基础上首先提出神经元的数学模型。此模型沿用至今,并且直接影响着这一领域研究的进展。因而,他们两人可称为人工神经网络研究的先驱。
1945年冯·诺依曼领导的设计小组试制成功存储程序式电子计算机,标志着电子计算机时代的开始。1948年,他在研究工作中比较了人脑结构与存储程序式计算机的根本区别,提出了以简单神经元构成的再生自动机网络结构。但是,由于指令存储式计算机技术的发展非常迅速,迫使他放弃了神经网络研究的新途径,继续投身于指令存储式计算机技术的研究,并在此领域作出了巨大贡献。虽然,冯·诺依曼的名字是与普通计算机联系在一起的,但他也是人工神经网络研究的先驱之一。
50年代末,F·Rosenblatt设计制作了“感知机”,它是一种多层的神经网络。这项工作首次把人工神经网络的研究从理论探讨付诸工程实践。当时,世界上许多实验室仿效制作感知机,分别应用于文字识别、声音识别、声纳信号识别以及学习记忆问题的研究。然而,这次人工神经网络的研究高潮未能持续很久,许多人陆续放弃了这方面的研究工作,这是因为当时数字计算机的发展处于全盛时期,许多人误以为数字计算机可以解决人工智能、模式识别、专家系统等方面的一切问题,使感知机的工作得不到重视;其次,当时的电子技术工艺水平比较落后,主要的元件是电子管或晶体管,利用它们制作的神经网络体积庞大,价格昂贵,要制作在规模上与真实的神经网络相似是完全不可能的;另外,在1968年一本名为《感知机》的著作中指出线性感知机功能是有限的,它不能解决如异或这样的基本问题,而且多层网络还不能找到有效的计算方法,这些论点促使大批研究人员对于人工神经网络的前景失去信心。60年代末期,人工神经网络的研究进入了低潮。
另外,在60年代初期,Widrow提出了自适应线性元件网络,这是一种连续取值的线性加权求和阈值网络。后来,在此基础上发展了非线性多层自适应网络。当时,这些工作虽未标出神经网络的名称,而实际上就是一种人工神经网络模型。
随着人们对感知机兴趣的衰退,神经网络的研究沉寂了相当长的时间。80年代初期,模拟与数字混合的超大规模集成电路制作技术提高到新的水平,完全付诸实用化,此外,数字计算机的发展在若干应用领域遇到困难。这一背景预示,向人工神经网络寻求出路的时机已经成熟。美国的物理学家Hopfield于1982年和1984年在美国科学院院刊上发表了两篇关于人工神经网络研究的论文,引起了巨大的反响。人们重新认识到神经网络的威力以及付诸应用的现实性。随即,一大批学者和研究人员围绕着 Hopfield提出的方法展开了进一步的工作,形成了80年代中期以来人工神经网络的研究热潮。
5、计算机网络技术毕业论文 5000字
计算机论文
计算机网络在电子商务中的应用
摘要:随着计算机网络技术的飞进发展,电子商务正得到越来越广泛的应用。由于电子商务中的交易行为大多数都是在网上完成的, 因此电子商务的安全性是影响趸易双方成败的一个关键因素。本文从电子商务系统对计算机网络安全,商务交易安全性出发,介绍利用网络安全枝术解决安全问题的方法。
关键词:计算机网络,电子商务安全技术
一. 引言
近几年来.电子商务的发展十分迅速 电子商务可以降低成本.增加贸易机会,简化贸易流通过程,提高生产力,改善物流和金流、商品流.信息流的环境与系统 虽然电子商务发展势头很强,但其贸易额所占整个贸易额的比例仍然很低。影响其发展的首要因素是安全问题.网上的交易是一种非面对面交易,因此“交易安全“在电子商务的发展中十分重要。可以说.没有安全就没有电子商务。电子商务的安全从整体上可分为两大部分.计算机网络安全和商务交易安全。计算机网络安全包括计算机网络设备安全、计算机网络系统安全、数据库安全等。其特征是针对计算机网络本身可能存在的安全问题,实施网络安全增强方案.以保证计算机网络自身的安全性为目标。商务安全则紧紧围绕传统商务在Interne'(上应用时产生的各种安全问题.在计算机网络安全的基础上.如何保障电子商务过程的顺利进行。即实现电子商务的保密性.完整性.可鉴别性.不可伪造性和不可依赖性。
二、电子商务网络的安全隐患
1窃取信息:由于未采用加密措施.数据信息在网络上以明文形式传送.入侵者在数据包经过的网关或路由器上可以截获传送的信息。通过多次窃取和分析,可以找到信息的规律和格式,进而得到传输信息的内容.造成网上传输信息泄密
2.篡改信息:当入侵者掌握了信息的格式和规律后.通过各种技术手段和方法.将网络上传送的信息数据在中途修改 然后再发向目的地。这种方法并不新鲜.在路由器或者网关上都可以做此类工作。
3假冒由于掌握了数据的格式,并可以篡改通过的信息,攻击者可以冒充合法用户发送假冒的信息或者主动获取信息,而远端用户通常很难分辨。
4恶意破坏:由于攻击者可以接入网络.则可能对网络中的信息进行修改.掌握网上的机要信息.甚至可以潜入网络内部.其后果是非常严重的。
三、电子商务交易中应用的网络安全技术
为了提高电子商务的安全性.可以采用多种网络安全技术和协议.这些技术和协议各自有一定的使用范围,可以给电子商务交易活动提供不同程度的安全保障。
1.防火墙技术。防火墙是目前主要的网络安全设备。防火墙通常使用的安全控制手段主要有包过滤、状态检测、代理服务 由于它假设了网络的边界和服务,对内部的非法访问难以有效地控制。因此.最适合于相对独立的与外部网络互连途径有限、网络服务种类相对集中的单一网络(如常见的企业专用网) 防火墙的隔离技术决定了它在电子商务安全交易中的重要作用。目前.防火墙产品主要分为两大类基于代理服务方式的和基于状态检测方式的。例如Check Poim Fi rewalI-1 4 0是基于Unix、WinNT平台上的软件防火墙.属状态检测型 Cisco PIX是硬件防火墙.也属状态检测型。由于它采用了专用的操作系统.因此减少了黑客利用操作系统G)H攻击的可能性:Raptor完全是基于代理技术的软件防火墙 由于互联网的开放性和复杂性.防火墙也有其固有的缺点(1)防火墙不能防范不经由防火墙的攻击。例如.如果允许从受保护网内部不受限制地向外拨号.一些用户可以形成与Interne'(的直接连接.从而绕过防火墙:造成一个潜在的后门攻击渠道,所以应该保证内部网与外部网之间通道的唯一性。(2)防火墙不能防止感染了病毒的软件或文件的传输.这只能在每台主机上装反病毒的实时监控软件。(3)防火墙不能防止数据驱动式攻击。当有些表面看来无害的数据被邮寄或复制到Interne'(主机上并被执行而发起攻击时.就会发生数据驱动攻击.所以对于来历不明的数据要先进行杀毒或者程序编码辨证,以防止带有后门程序。
2.数据加密技术。防火墙技术是一种被动的防卫技术.它难以对电子商务活动中不安全的因素进行有效的防卫。因此.要保障电子商务的交易安全.就应当用当代密码技术来助阵。加密技术是电子商务中采取的主要安全措施, 贸易方可根据需要在信息交换的阶段使用。目前.加密技术分为两类.即对称加密/对称密钥加密/专用密钥加密和非对称加密/公开密钥加密。现在许多机构运用PKI(punickey nfrastructur)的缩写.即 公开密钥体系”)技术实施构建完整的加密/签名体系.更有效地解决上述难题.在充分利用互联网实现资源共享的前提下从真正意义上确保了网上交易与信息传递的安全。在PKI中.密钥被分解为一对(即一把公开密钥或加密密钥和一把专用密钥或解密密钥)。这对密钥中的任何一把都可作为公开密钥(加密密钥)通过非保密方式向他人公开.而另一把则作为专用密钥{解密密钥)加以保存。公开密钥用于对机密�6�11生息的加密.专用密钥则用于对加信息的解密。专用密钥只能由生成密钥对的贸易方掌握.公开密钥可广泛发布.但它只对应用于生成该密钥的贸易方。贸易方利用该方案实现机密信息交换的基本过程是 贸易方甲生成一对密钥并将其中的一把作为公开密钥向其他贸易方公开:得到该公开密钥的贸易方乙使用该密钥对机密信息进行加密后再发送给贸易方甲 贸易方甲再用自己保存的另一把专用密钥对加密后的信息进行解密。贸易方甲只能用其专用密钥解密由其公开密钥加密后的任何信息。
3.身份认证技术。身份认证又称为鉴别或确认,它通过验证被认证对象的一个或多个参数的真实性与有效性 来证实被认证对象是否符合或是否有效的一种过程,用来确保数据的真实性。防止攻击者假冒 篡改等。一般来说。用人的生理特征参数f如指纹识别、虹膜识别)进行认证的安全性很高。但目前这种技术存在实现困难、成本很高的缺点。目前,计算机通信中采用的参数有口令、标识符 密钥、随机数等。而且一般使用基于证书的公钥密码体制(PK I)身份认证技术。要实现基于公钥密码算法的身份认证需求。就必须建立一种信任及信任验证机制。即每个网络上的实体必须有一个可以被验证的数字标识 这就是 数字证书(Certifi2cate)”。数字证书是各实体在网上信息交流及商务交易活动中的身份证明。具有唯一性。证书基于公钥密码体制.它将用户的公开密钥同用户本身的属性(例如姓名,单位等)联系在一起。这就意味着应有一个网上各方都信任的机构 专门负责对各个实体的身份进行审核,并签发和管理数字证书,这个机构就是证书中心(certificate authorities.简称CA}。CA用自己的私钥对所有的用户属性、证书属性和用户的公钥进行数字签名,产生用户的数字证书。在基于证书的安全通信中.证书是证明用户合法身份和提供用户合法公钥的凭证.是建立保密通信的基础。因此,作为网络可信机构的证书管理设施 CA主要职能就是管理和维护它所签发的证书 提供各种证书服务,包括:证书的签发、更新 回收、归档等。
4.数字签名技术。数字签名也称电子签名 在信息安全包括身份认证,数据完整性、不可否认性以及匿名性等方面有重要应用。数字签名是非对称加密和数字摘要技术的联合应用。其主要方式为:报文发送方从报文文本中生成一个1 28b it的散列值(或报文摘要),并用自己的专用密钥对这个散列值进行加密 形成发送方的数字签名:然后 这个数字签名将作为报文的附件和报文一起发送给报文的接收方 报文接收方首先从接收到的原始报文中计算出1 28bit位的散列值(或报文摘要).接着再用发送方的公开密钥来对报文附加的数字签名进行解密 如果两个散列值相同 那么接收方就能确认该数字签名是发送方的.通过数字签名能够实现对原始报文的鉴别和不可抵赖性。
四、结束语
电子商务安全对计算机网络安全与商务安全提出了双重要求.其复杂程度比大多数计算机网络都高。在电子商务的建设过程中涉及到许多安全技术问题 制定安全技术规则和实施安全技术手段不仅可以推动安全技术的发展,同时也促进安全的电子商务体系的形成。当然,任何一个安全技术都不会提供永远和绝对的安全,因为网络在变化.应用在变化,入侵和破坏的手段也在变化,只有技术的不断进步才是真正的安全保障。
参考文献:
[1]肖满梅 罗兰娥:电子商务及其安全技术问题.湖南科技学院学报,2006,27
[2]丰洪才 管华 陈珂:电子商务的关键技术及其安全性分析.武汉工业学院学报 2004,2
[3]阎慧 王伟:宁宇鹏等编著.防火墙原理与技术[M]北京:机械工业出版杜 2004
6、神经网络BP模型
一、BP模型概述
误差逆传播(Error Back-Propagation)神经网络模型简称为BP(Back-Propagation)网络模型。
Pall Werbas博士于1974年在他的博士论文中提出了误差逆传播学习算法。完整提出并被广泛接受误差逆传播学习算法的是以Rumelhart和McCelland为首的科学家小组。他们在1986年出版“Parallel Distributed Processing,Explorations in the Microstructure of Cognition”(《并行分布信息处理》)一书中,对误差逆传播学习算法进行了详尽的分析与介绍,并对这一算法的潜在能力进行了深入探讨。
BP网络是一种具有3层或3层以上的阶层型神经网络。上、下层之间各神经元实现全连接,即下层的每一个神经元与上层的每一个神经元都实现权连接,而每一层各神经元之间无连接。网络按有教师示教的方式进行学习,当一对学习模式提供给网络后,神经元的激活值从输入层经各隐含层向输出层传播,在输出层的各神经元获得网络的输入响应。在这之后,按减小期望输出与实际输出的误差的方向,从输入层经各隐含层逐层修正各连接权,最后回到输入层,故得名“误差逆传播学习算法”。随着这种误差逆传播修正的不断进行,网络对输入模式响应的正确率也不断提高。
BP网络主要应用于以下几个方面:
1)函数逼近:用输入模式与相应的期望输出模式学习一个网络逼近一个函数;
2)模式识别:用一个特定的期望输出模式将它与输入模式联系起来;
3)分类:把输入模式以所定义的合适方式进行分类;
4)数据压缩:减少输出矢量的维数以便于传输或存储。
在人工神经网络的实际应用中,80%~90%的人工神经网络模型采用BP网络或它的变化形式,它也是前向网络的核心部分,体现了人工神经网络最精华的部分。
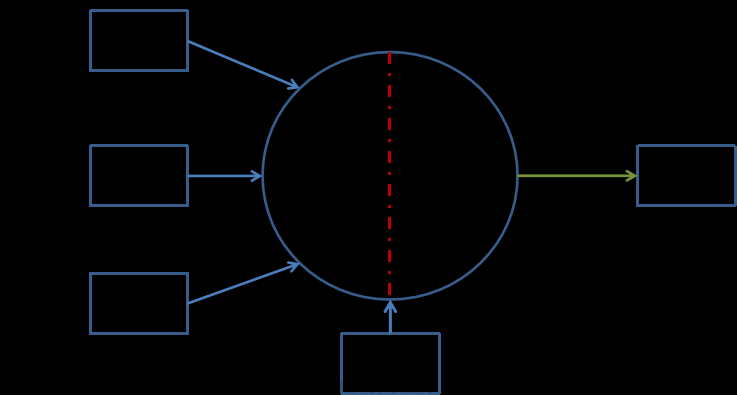
二、BP模型原理
下面以三层BP网络为例,说明学习和应用的原理。
1.数据定义
P对学习模式(xp,dp),p=1,2,…,P;
输入模式矩阵X[N][P]=(x1,x2,…,xP);
目标模式矩阵d[M][P]=(d1,d2,…,dP)。
三层BP网络结构
输入层神经元节点数S0=N,i=1,2,…,S0;
隐含层神经元节点数S1,j=1,2,…,S1;
神经元激活函数f1[S1];
权值矩阵W1[S1][S0];
偏差向量b1[S1]。
输出层神经元节点数S2=M,k=1,2,…,S2;
神经元激活函数f2[S2];
权值矩阵W2[S2][S1];
偏差向量b2[S2]。
学习参数
目标误差ϵ;
初始权更新值Δ0;
最大权更新值Δmax;
权更新值增大倍数η+;
权更新值减小倍数η-。
2.误差函数定义
对第p个输入模式的误差的计算公式为
中国矿产资源评价新技术与评价新模型
y2kp为BP网的计算输出。
3.BP网络学习公式推导
BP网络学习公式推导的指导思想是,对网络的权值W、偏差b修正,使误差函数沿负梯度方向下降,直到网络输出误差精度达到目标精度要求,学习结束。
各层输出计算公式
输入层
y0i=xi,i=1,2,…,S0;
隐含层
中国矿产资源评价新技术与评价新模型
y1j=f1(z1j),
j=1,2,…,S1;
输出层
中国矿产资源评价新技术与评价新模型
y2k=f2(z2k),
k=1,2,…,S2。
输出节点的误差公式
中国矿产资源评价新技术与评价新模型
对输出层节点的梯度公式推导
中国矿产资源评价新技术与评价新模型
E是多个y2m的函数,但只有一个y2k与wkj有关,各y2m间相互独立。
其中
中国矿产资源评价新技术与评价新模型
则
中国矿产资源评价新技术与评价新模型
设输出层节点误差为
δ2k=(dk-y2k)·f2′(z2k),
则
中国矿产资源评价新技术与评价新模型
同理可得
中国矿产资源评价新技术与评价新模型
对隐含层节点的梯度公式推导
中国矿产资源评价新技术与评价新模型
E是多个y2k的函数,针对某一个w1ji,对应一个y1j,它与所有的y2k有关。因此,上式只存在对k的求和,其中
中国矿产资源评价新技术与评价新模型
则
中国矿产资源评价新技术与评价新模型
设隐含层节点误差为
中国矿产资源评价新技术与评价新模型
则
中国矿产资源评价新技术与评价新模型
同理可得
中国矿产资源评价新技术与评价新模型
4.采用弹性BP算法(RPROP)计算权值W、偏差b的修正值ΔW,Δb
1993年德国 Martin Riedmiller和Heinrich Braun 在他们的论文“A Direct Adaptive Method for Faster Backpropagation Learning:The RPROP Algorithm”中,提出Resilient Backpropagation算法——弹性BP算法(RPROP)。这种方法试图消除梯度的大小对权步的有害影响,因此,只有梯度的符号被认为表示权更新的方向。
权改变的大小仅仅由权专门的“更新值”
确定
中国矿产资源评价新技术与评价新模型
其中
表示在模式集的所有模式(批学习)上求和的梯度信息,(t)表示t时刻或第t次学习。
权更新遵循规则:如果导数是正(增加误差),这个权由它的更新值减少。如果导数是负,更新值增加。
中国矿产资源评价新技术与评价新模型
RPROP算法是根据局部梯度信息实现权步的直接修改。对于每个权,我们引入它的
各自的更新值
,它独自确定权更新值的大小。这是基于符号相关的自适应过程,它基
于在误差函数E上的局部梯度信息,按照以下的学习规则更新
中国矿产资源评价新技术与评价新模型
其中0<η-<1<η+。
在每个时刻,如果目标函数的梯度改变它的符号,它表示最后的更新太大,更新值
应由权更新值减小倍数因子η-得到减少;如果目标函数的梯度保持它的符号,更新值应由权更新值增大倍数因子η+得到增大。
为了减少自由地可调参数的数目,增大倍数因子η+和减小倍数因子η–被设置到固定值
η+=1.2,
η-=0.5,
这两个值在大量的实践中得到了很好的效果。
RPROP算法采用了两个参数:初始权更新值Δ0和最大权更新值Δmax
当学习开始时,所有的更新值被设置为初始值Δ0,因为它直接确定了前面权步的大小,它应该按照权自身的初值进行选择,例如,Δ0=0.1(默认设置)。
为了使权不至于变得太大,设置最大权更新值限制Δmax,默认上界设置为
Δmax=50.0。
在很多实验中,发现通过设置最大权更新值Δmax到相当小的值,例如
Δmax=1.0。
我们可能达到误差减小的平滑性能。
5.计算修正权值W、偏差b
第t次学习,权值W、偏差b的的修正公式
W(t)=W(t-1)+ΔW(t),
b(t)=b(t-1)+Δb(t),
其中,t为学习次数。
6.BP网络学习成功结束条件每次学习累积误差平方和
中国矿产资源评价新技术与评价新模型
每次学习平均误差
中国矿产资源评价新技术与评价新模型
当平均误差MSE<ε,BP网络学习成功结束。
7.BP网络应用预测
在应用BP网络时,提供网络输入给输入层,应用给定的BP网络及BP网络学习得到的权值W、偏差b,网络输入经过从输入层经各隐含层向输出层的“顺传播”过程,计算出BP网的预测输出。
8.神经元激活函数f
线性函数
f(x)=x,
f′(x)=1,
f(x)的输入范围(-∞,+∞),输出范围(-∞,+∞)。
一般用于输出层,可使网络输出任何值。
S型函数S(x)
中国矿产资源评价新技术与评价新模型
f(x)的输入范围(-∞,+∞),输出范围(0,1)。
f′(x)=f(x)[1-f(x)],
f′(x)的输入范围(-∞,+∞),输出范围(0,
]。
一般用于隐含层,可使范围(-∞,+∞)的输入,变成(0,1)的网络输出,对较大的输入,放大系数较小;而对较小的输入,放大系数较大,所以可用来处理和逼近非线性的输入/输出关系。
在用于模式识别时,可用于输出层,产生逼近于0或1的二值输出。
双曲正切S型函数
中国矿产资源评价新技术与评价新模型
f(x)的输入范围(-∞,+∞),输出范围(-1,1)。
f′(x)=1-f(x)·f(x),
f′(x)的输入范围(-∞,+∞),输出范围(0,1]。
一般用于隐含层,可使范围(-∞,+∞)的输入,变成(-1,1)的网络输出,对较大的输入,放大系数较小;而对较小的输入,放大系数较大,所以可用来处理和逼近非线性的输入/输出关系。
阶梯函数
类型1
中国矿产资源评价新技术与评价新模型
f(x)的输入范围(-∞,+∞),输出范围{0,1}。
f′(x)=0。
类型2
中国矿产资源评价新技术与评价新模型
f(x)的输入范围(-∞,+∞),输出范围{-1,1}。
f′(x)=0。
斜坡函数
类型1
中国矿产资源评价新技术与评价新模型
f(x)的输入范围(-∞,+∞),输出范围[0,1]。
中国矿产资源评价新技术与评价新模型
f′(x)的输入范围(-∞,+∞),输出范围{0,1}。
类型2
中国矿产资源评价新技术与评价新模型
f(x)的输入范围(-∞,+∞),输出范围[-1,1]。
中国矿产资源评价新技术与评价新模型
f′(x)的输入范围(-∞,+∞),输出范围{0,1}。
三、总体算法
1.三层BP网络(含输入层,隐含层,输出层)权值W、偏差b初始化总体算法
(1)输入参数X[N][P],S0,S1,f1[S1],S2,f2[S2];
(2)计算输入模式X[N][P]各个变量的最大值,最小值矩阵 Xmax[N],Xmin[N];
(3)隐含层的权值W1,偏差b1初始化。
情形1:隐含层激活函数f( )都是双曲正切S型函数
1)计算输入模式X[N][P]的每个变量的范围向量Xrng[N];
2)计算输入模式X的每个变量的范围均值向量Xmid[N];
3)计算W,b的幅度因子Wmag;
4)产生[-1,1]之间均匀分布的S0×1维随机数矩阵Rand[S1];
5)产生均值为0,方差为1的正态分布的S1×S0维随机数矩阵Randnr[S1][S0],随机数范围大致在[-1,1];
6)计算W[S1][S0],b[S1];
7)计算隐含层的初始化权值W1[S1][S0];
8)计算隐含层的初始化偏差b1[S1];
9))输出W1[S1][S0],b1[S1]。
情形2:隐含层激活函数f( )都是S型函数
1)计算输入模式X[N][P]的每个变量的范围向量Xrng[N];
2)计算输入模式X的每个变量的范围均值向量Xmid[N];
3)计算W,b的幅度因子Wmag;
4)产生[-1,1]之间均匀分布的S0×1维随机数矩阵Rand[S1];
5)产生均值为0,方差为1的正态分布的S1×S0维随机数矩阵Randnr[S1][S0],随机数范围大致在[-1,1];
6)计算W[S1][S0],b[S1];
7)计算隐含层的初始化权值W1[S1][S0];
8)计算隐含层的初始化偏差b1[S1];
9)输出W1[S1][S0],b1[S1]。
情形3:隐含层激活函数f( )为其他函数的情形
1)计算输入模式X[N][P]的每个变量的范围向量Xrng[N];
2)计算输入模式X的每个变量的范围均值向量Xmid[N];
3)计算W,b的幅度因子Wmag;
4)产生[-1,1]之间均匀分布的S0×1维随机数矩阵Rand[S1];
5)产生均值为0,方差为1的正态分布的S1×S0维随机数矩阵Randnr[S1][S0],随机数范围大致在[-1,1];
6)计算W[S1][S0],b[S1];
7)计算隐含层的初始化权值W1[S1][S0];
8)计算隐含层的初始化偏差b1[S1];
9)输出W1[S1][S0],b1[S1]。
(4)输出层的权值W2,偏差b2初始化
1)产生[-1,1]之间均匀分布的S2×S1维随机数矩阵W2[S2][S1];
2)产生[-1,1]之间均匀分布的S2×1维随机数矩阵b2[S2];
3)输出W2[S2][S1],b2[S2]。
2.应用弹性BP算法(RPROP)学习三层BP网络(含输入层,隐含层,输出层)权值W、偏差b总体算法
函数:Train3BP_RPROP(S0,X,P,S1,W1,b1,f1,S2,W2,b2,f2,d,TP)
(1)输入参数
P对模式(xp,dp),p=1,2,…,P;
三层BP网络结构;
学习参数。
(2)学习初始化
1)
;
2)各层W,b的梯度值
,
初始化为零矩阵。
(3)由输入模式X求第一次学习各层输出y0,y1,y2及第一次学习平均误差MSE
(4)进入学习循环
epoch=1
(5)判断每次学习误差是否达到目标误差要求
如果MSE<ϵ,
则,跳出epoch循环,
转到(12)。
(6)保存第epoch-1次学习产生的各层W,b的梯度值
,
(7)求第epoch次学习各层W,b的梯度值
,
1)求各层误差反向传播值δ;
2)求第p次各层W,b的梯度值
,
;
3)求p=1,2,…,P次模式产生的W,b的梯度值
,
的累加。
(8)如果epoch=1,则将第epoch-1次学习的各层W,b的梯度值
,
设为第epoch次学习产生的各层W,b的梯度值
,
。
(9)求各层W,b的更新
1)求权更新值Δij更新;
2)求W,b的权更新值
,
;
3)求第epoch次学习修正后的各层W,b。
(10)用修正后各层W、b,由X求第epoch次学习各层输出y0,y1,y2及第epoch次学习误差MSE
(11)epoch=epoch+1,
如果epoch≤MAX_EPOCH,转到(5);
否则,转到(12)。
(12)输出处理
1)如果MSE<ε,
则学习达到目标误差要求,输出W1,b1,W2,b2。
2)如果MSE≥ε,
则学习没有达到目标误差要求,再次学习。
(13)结束
3.三层BP网络(含输入层,隐含层,输出层)预测总体算法
首先应用Train3lBP_RPROP( )学习三层BP网络(含输入层,隐含层,输出层)权值W、偏差b,然后应用三层BP网络(含输入层,隐含层,输出层)预测。
函数:Simu3lBP( )。
1)输入参数:
P个需预测的输入数据向量xp,p=1,2,…,P;
三层BP网络结构;
学习得到的各层权值W、偏差b。
2)计算P个需预测的输入数据向量xp(p=1,2,…,P)的网络输出 y2[S2][P],输出预测结果y2[S2][P]。
四、总体算法流程图
BP网络总体算法流程图见附图2。
五、数据流图
BP网数据流图见附图1。
六、实例
实例一 全国铜矿化探异常数据BP 模型分类
1.全国铜矿化探异常数据准备
在全国铜矿化探数据上用稳健统计学方法选取铜异常下限值33.1,生成全国铜矿化探异常数据。
2.模型数据准备
根据全国铜矿化探异常数据,选取7类33个矿点的化探数据作为模型数据。这7类分别是岩浆岩型铜矿、斑岩型铜矿、矽卡岩型、海相火山型铜矿、陆相火山型铜矿、受变质型铜矿、海相沉积型铜矿,另添加了一类没有铜异常的模型(表8-1)。
3.测试数据准备
全国化探数据作为测试数据集。
4.BP网络结构
隐层数2,输入层到输出层向量维数分别为14,9、5、1。学习率设置为0.9,系统误差1e-5。没有动量项。
表8-1 模型数据表
续表文章来源:https://www.toymoban.com/news/detail-540110.html
5.计算结果图
如图8-2、图8-3。
图8-2
图8-3 全国铜矿矿床类型BP模型分类示意图
实例二 全国金矿矿石量品位数据BP 模型分类
1.模型数据准备
根据全国金矿储量品位数据,选取4类34个矿床数据作为模型数据,这4类分别是绿岩型金矿、与中酸性浸入岩有关的热液型金矿、微细浸染型型金矿、火山热液型金矿(表8-2)。
2.测试数据准备
模型样本点和部分金矿点金属量、矿石量、品位数据作为测试数据集。
3.BP网络结构
输入层为三维,隐层1层,隐层为三维,输出层为四维,学习率设置为0.8,系统误差1e-4,迭代次数5000。
表8-2 模型数据
4.计算结果
结果见表8-3、8-4。
表8-3 训练学习结果
表8-4 预测结果(部分)
续表
7、求计算机毕业论文2万字左右的
大学生最需要的中文免费论文网站:
无忧论文网
(老牌子论文网)
中国论文网
(免费论文下载,大量免费资源)
论文宝
(爆多论文,百万论文库全免费,找论文的好去处)
轻松论文网
(论文网站,
免费论文下载)
中华论文网
(
论文下载,论文写作,论文发表等,不错的地方)
中国论文网
专业英文论文网站
我要写论文网
国内唯一论文写作平台,要写论文的、会写论文的都别错过了。文章来源地址https://www.toymoban.com/news/detail-540110.html
到了这里,关于bp神经网络数学建模论文,关于bp神经网络的论文的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!