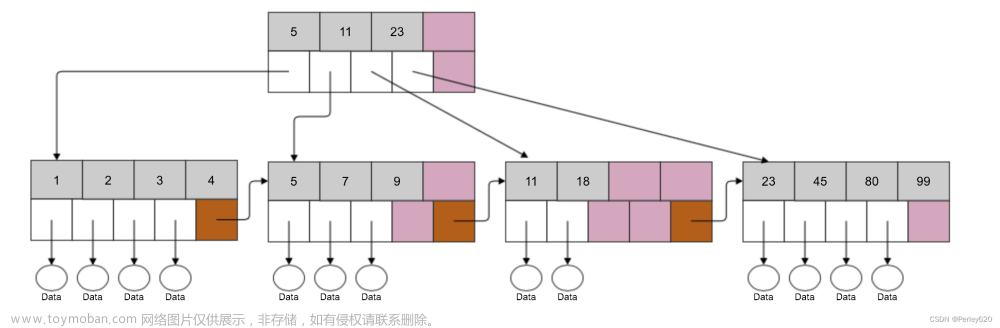
MySQL中提高性能的一个最有效的方式是对数据表设计合理的索引。索引提供了高效访问数据的方法,并且加快查询的速度, 因此索引对查询的速度有着至关重要的影响。
使用索引可以快速地定位表中的某条记录,从而提高数据库查询的速度,提高数据库的性能。如果查询时没有使用索引,查询语句就会扫描表中的所有记录。在数据量大的情况下,这样查询的速度会很慢。
我们一般创建的索引类型都是B+Tree结构,其实,用不用索引最终都是优化器说了算。
那么MySQL优化器是什么呢?
MySQL内部优化器是MySQL中很重要的一个部分,它主要用于在执行查询时获取最合适的执行计划,以使得查询能够以最短的时间内得到结果。
MySQL内部优化器的工作原理是在接收到一条查询语句之后,它会根据一系列的算法和规oSi则来确定哪个执行计划是最优的。
通常情况下,MySQL优化器会依赖于表的统计信息和索引信息来进行优化决策。例如,在执行select语句时,优化器会尝试使用索引来避免全表扫描。同时,优化器还会对各种查询操作的代价进行估算,以便找到最优的执行计划。

那么我们如何去查看这条sql的一个执行计划呢?很简单只需要在我们执行的sql前面加上explain关键字即可。
-- 创建数据库表格
CREATE TABLE `account` (
`id` bigint NOT NULL AUTO_INCREMENT,
`phone` varchar(64) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`pwd` varchar(128) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`province` varchar(80) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`city` varchar(60) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`status` int NOT NULL,
`gmt_create` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
-- 执行sql查看执行计划
explain SELECT * from account where id = '1'

EXPLAIN 是用于分析并优化查询语句性能的工具,执行计划会解析查询语句并生成执行计划,包括访问表和索引所需的策略、查询优化器的选择以及每个阶段的估计记录数等信息,深入SQL语句在执行过程中的各个细节。
OK,接下来我们来看一下各个字段的含义。
id:对于 SELECT 语句,每个查询都会被分配一个唯一的ID。表示查询的标识符,数字越大越先执行。
select_type:表示查询类型或者子查询类型,使用不同的 select_type 来帮助评估查询性能,并确定可以采取哪些优化方法。需要根据具体情况来进行相应的优化,例如尽量减少子查询的数量,避免使用不必要的 UNION 操作等等。
| 类型 | 概述 |
|---|---|
| SIMPLE | 表示简单的 SELECT 查询,不包含子查询或 UNION 操作。 |
| PRIMARY | 表示外层查询的第一个 SELECT |
| UNION | 表示 UNION 操作的第二个或后续的 SELECT 查询。 |
| SUBQUERY | 表示一个子查询,MySQL 会在子查询中先执行查询,比如where里面包括了子查询 |
| DEPENDENT SUBQUERY | 也表示一个子查询,但是外部 SQL 查询的结果会影响子查询的执行 |
| DERIVED | 表示派生表,MySQL 会在查询中创建一个新的临时表,这个临时表来自于 FROM 子句中的子查询 |
| UNION RESULT | 表示 UNION 操作的结果,MySQL 在创建结果集时使用临时表来存储数据 |
table:表示查询涉及到哪些表,对于子查询等复杂查询可能涉及多张表。
partitions:表示查询操作涉及到的分区表的分区情况。
type:表示 MySQL 在表中找到所需行的方式,常见的类型包括 ALL, index,range, ref, eq_ref, const, system, NULL。
| Type | 概述 |
|---|---|
| all | 全表扫描,MYSQL扫描全表来找到匹配的行 |
| index | 索引全扫描,MYSQL遍历整个索引来查找匹配的行;Extra 字段里面 出现 Using index,则是覆盖索引,不用二次回表查询 |
| range | 索引范围扫描,常见于<、<=、>、>=、between、in等操作符;相对于index的全索引扫描,它有范围限制,因此要优于index |
| ref | 使用非唯一性索引或者唯一索引的前缀扫描,返回匹配某个单独值的记录行; 虽使用了索引但该索引列的值并不唯一,进行目标值附近的小范围扫描,不扫描全表 |
| eq_ref | eq_ref 与 ref对比结果集只有一个,使用主键或者唯一索引进行查找,不用扫描更多行 |
| const | 最多只有一条匹配行,查询非常迅速,用到primary key 或者unique key,性能最高 |
| system | 表只有一行,基本不会出现,忽略 |
| null | 不访问数据库表,直接返回索引 |
possible_key:表示 MySQL 可以使用哪些索引来优化查询
key:表示 MySQL 实际使用的索引,如果没有使用任何索引,则该值为 NULL
key_len:表示 MySQL 实际使用的索引的长度,该值与索引定义的长度有关
ref:表示 MySQL 使用哪个列或常量与索引列进行比较。
rows:表示 MySQL 估计要扫描多少行才能找到所需记录,是一个估算值而不是确切值。
filtered:查询条件过滤的效率,百分比形式表示, Filtered 越高,表示查询结果集中过滤数据所需要的开销越小,查询性能就越好。
Extra:该字段包括一些额外的查询信息,包括使用何种排序方式、使用哪种 Join 操作等。
| 类型 | 概述 |
|---|---|
| Using index | 选择使用了覆盖索引的特性,通过索引直接获取查询结果,而无需回表查询,提高了查询效率。 |
| Using filesort | 需要额外进行 一个文件排序操作来实现 ORDER BY 操作,可能会严重影响查询性能。 |
| Using temporary | 在执行查询时需要借助临时表来保存中间结果集,这常发生在排序、分组、子查询和 UNION 查询之中。 |
| Using where | 条件查询,在查询过程中需要进行表级别的条件过滤,即使共享了某些索引,也需要进行全表扫描查找符合条件的行。不是仅仅通过索引就可以获取所有需要的数据,则会出现 Using where |
| Range checked for each record | 通过索引比较操作来过滤部分行,直到找到符合条件的行,这种操作常出现在使用 INDEX 和 ORDER BY 操作时。 |
| Using join buffer (Block Nested Loop) | 在执行连接操作时需要额外申请 join buffer 来存储中间结果,这种操作常发生在连接操作中。 |
| Using index condition | 利用了查找索引数据的过程中额外发现的过滤条件进行了优化,无需回表查询或查表,可以直接通过索引结果来返回查询的结果 |
Using sort_union()和 Using union() |
通过 UNION ALL 或 UNION DISTINCT 操作来合并查询结果集,使用了一些优化策略来提高查询效率。 |
OK,介绍了这么多,下面我们就开始进入正题,来说一说索引失效的场景都有哪些。
1.隐式转换导致不走索引,索引失效
当采用索引查询时列的类型不一样,就会导致索引失效。我们当前account表中id是varchar类型,我们现在查询用数字类型查,这会就会导致索引失效。
explain SELECT * from account where id = 1

改用字符串查询
explain SELECT * from account where id = '1'

2.当索引列配合不是索引列进行or查询时,索引失效
当我们查询时索引列配合不是索引列进行查询的时候,会导致索引失效,比如说id是索引,gmt_create不是索引,当**id = ‘1’ or gmt_create = ‘2024-01-01’**时,这就会导致索引失效。
explain SELECT * from account where id='1' or gmt_create = '2024-01-01'

要想让其走索引查询,可以给gmt_create加上索引,or两边字段都是索引字段才会走索引。
CREATE INDEX gmt_create on account(gmt_create)

这里也可以我们规定强制走哪一个索引,不过一般不建议,因为sql优化器已经帮我们计算好最优的查询方式。
explain SELECT * from account force index(PRIMARY) where id='1' or gmt_create = '2024-01-01'

虽然强制地使用了索引,但是经过分析,这次查询还是没有使用索引,所以强制使用索引并不一定是生效的。
3.业务表的数据量太少,索引失效
MySQL索引是为了加速查询而存在的,如果数据量太小,MySQL查询速度本来就很快,这时候使用索引反而会拖慢查询速度。因此,当数据量很小的时候,MySQL索引可能会失效。
explain SELECT * from account where id = '1'

4.当索引字段采用函数查询时,索引失效
当索引字段采用函数查询时,会导致索引失效,比如gmt_create本身是一个索引字段,我们采用YEAR函数进行查询,就会导致索引的失效。
explain SELECT * from account where YEAR(gmt_create) = '2023'

5.like查询索引字段左边模糊查询,索引失效
当索引列使用LIKE操作符时,左边模糊查询会导致索引失效。比如我们给province加上索引,我们用province like “%天津%” 或者 province like “%天津” 都会导致索引的失效,只有province like "天津%"索引才不会失效。
添加索引:CREATE INDEX province on account(province)
explain SELECT * from account where province like '%天津'

explain SELECT * from account where province like '天津%'

6.字段重复性高导致索引失效
比如有一些字段他的重复性的值确实特别的高,那么这种字段就不适合加索引。

explain SELECT * from account where province = '宝地区'

7.IS NULL操作时,索引失效
IS NULL不走索引,IS NOT NULL走索引,设计字段的时候,如果没有要求必须为NULL,那最好给个默认值空字符串。
explain SELECT id from account where province is NULL

explain SELECT id from account where province is not NULL

还有一种情况,单键值的B树索引列上存在null值,导致COUNT(*)不能走索引。
-- status状态加上索引
CREATE INDEX status on account(status)

explain SELECT count(status) from account
我们来看一下status加上索引,没有为空的数据时,执行计划是啥样的。

8.联合索引没有遵循最左匹配原则,索引失效
如果使用了联合索引,但查询时未使用索引的第一列,索引也会失效。
原因:比如我们根据字段(t1,t2,t3)建立了联合索引,则排序规则是先按t1字段进行排序,t1字段相同再按t2字段排序,当t1、t2字段都相同时再按t3字段进行排序。如果我们的查询条件中没有使用到第一列,那么该索引也就没有办法使用。
-- 创建联合索引
CREATE INDEX idx_phone_provice_status on account(phone,province,status)
我们删除之前加的province和status的单独的索引。
explain select * from account where province = '宝地区' and status = 1

只要我们把联合索引的第一列放在前面,就可以生效。
explain select * from account where phone = '12384374374' and province = '宝地区' and status = 1

explain select * from account where phone = '12384374374' and status = 1

9.不等于操作符(<>、!=)会导致索引失效
这种查询语句无法使用索引,因为需要扫描整个表来查找不等于’value’的记录。
explain select * from account where phone != '12384374374'

10.IN语句引起的索引失效
使用IN语句进行查询时,如果查询的值列表比较大或者是一个子查询,则会引起索引失效。
我们可以通过以下sql来模拟这种情况,这块就不做真实的演示啦,大家在工作中遇到IN查询的时候可以看一下执行计划,然后做出对应的调整。
SELECT * FROM table_name WHERE column_name IN (SELECT column_name FROM another_table);
这样的查询语句会导致数据库无法使用索引来查找匹配的记录,因为索引只能查找单个值,而不能匹配多个值。
为了避免IN语句导致的索引失效,我们可以使用以下替代方案:
使用EXISTS语句来代替IN语句,例如:
SELECT * FROM table_name1 t1 WHERE EXISTS (SELECT * FROM table_name2 t2 WHERE t2.column_name = t1.column_name);
或者是使用JOIN来代替IN语句,例如:
SELECT * FROM table_name1 t1 JOIN table_name2 t2 ON(t1.column_name = t2.column_name);
11.数据库与表还有表与表的编码不兼容,索引失效
在sql中做表关联时,需要注意两边字段的编码要保持一致。
Ok,以上就是我们在工作中常见的一些索引失效的案例。
接下来我们来说一下,索引的一些设计规则。
- 高频次查询且数据量大的表建立索引
- 经常需要排序、分组和联合操作的字段建立索引
- 短索引可以提升访问的IO效率,对于BLOB、TEXT或很长的varchar列使用前缀索引
- 删除无用索引,同列上创建多个索引,越多索引维护成本越高,优化器在优化查询时也需要逐个考虑,会影响性能
- 根据业务需求,设计好联合索引,业务使用的时候尽量用到联合索引,避免回表查询
- 尽量选择区分度高的列作为索引,区分度越高性能越好,比如唯一索引
- 索引列不参与计算,带函数的查询不建议做为索引列
- 尽量扩展利用现有索引,联合索引的查询效率比多个独立索引高
- 尽量避免NULL,应该指定列为NOT NULL,含有空值的列很难进行查询优化,可以用0或一个空串代替NULL
- 唯一索引与普通索引
- 唯一索引和普通索引在性能上没有本质的区别,但在数据的唯一性方面
- 唯一索引在数据插入和更新时需要更多计算,因此略微慢一些。
- 聚簇索引与非聚簇索引
- 聚簇索引在性能上优于非聚簇索引,因为聚簇索引是将数据存储在一起的
- 这样检索数据时可以最大程度地减少磁盘 IO 操作。但如果经常更新表中的数据,则聚簇索引的维护成本相对较高。
- 覆盖索引与非覆盖索引
- 覆盖索引可以直接从索引中获取数据,无需回表查询,因此执行速度更快
- 但是如果查询需要取出的数据列不在索引中,则无法使用覆盖索引,需要进行回表查询,效率较低。
好啦,至此本文就到这啦,记得三连➕关注哦!文章来源:https://www.toymoban.com/news/detail-540118.html
 文章来源地址https://www.toymoban.com/news/detail-540118.html
文章来源地址https://www.toymoban.com/news/detail-540118.html
到了这里,关于【MySQL】SQL索引失效的几种场景及优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!