所谓的应用层钩子(Application-level hooks)是一种编程技术,它允许应用程序通过在特定事件发生时执行特定代码来自定义或扩展其行为。这些事件可以是用户交互,系统事件,或者其他应用程序内部的事件。应用层钩子是在应用程序中添加自定义代码的一种灵活的方式。它们可以用于许多不同的用途,如安全审计、性能监视、访问控制和行为修改等。应用层钩子通常在应用程序的运行时被调用,可以执行一些预定义的操作或触发一些自定义代码。
通常情况下,第三方应用在需要扩展一个程序功能是都会采用挂钩子的方式实现,而由于内存数据被修改后磁盘数据依然是原始数据,这就给扫描这些钩子提供了便利,具体来说钩子扫描的原理是通过读取磁盘中的PE文件中的反汇编代码,并与内存中的代码作比较,当两者发生差异是则可以证明此处被挂了钩子。
本节内容中,笔者将通过一个案例并配合Capstone引擎来实现这个功能,之所以选用该引擎是因为该引擎支持Python包,可以非常容易的与LyScript插件互动,此外Capstone引擎在逆向工程、漏洞分析、恶意代码分析等领域有广泛的应用,著名反汇编调试器IDA则是使用了该引擎工作的。
-
Capstone引擎的主要特点包括:
-
支持多种指令集:支持x86、ARM、MIPS、PowerPC等多种指令集,且能够在不同的平台上运行。
-
轻量级高效:采用C语言编写,代码简洁高效,反汇编速度快。
-
易于使用:提供了易于使用的API和文档,支持Python、Ruby、Java等多种编程语言。
-
可定制性:提供了多种可配置选项,能够满足不同用户的需求。
Capstone的安装非常容易,只需要执行pip install capstone即可完成,使用Capstone反汇编时读者只需要传入一个PE文件路径,并通过md.disasm(HexCode, 0)即可实现反汇编任务;
代码首先使用pefile库读取PE文件,获取文件的ImageBase,以及名为".text"的节表的VirtualAddress、Misc_VirtualSize和PointerToRawData等信息。接下来,代码计算了".text"节表的起始地址StartVA和结束地址StopVA,然后使用文件指针读取文件中".text"节表的原始数据,并使用capstone库进行反汇编。反汇编结果以字典形式存储,包括反汇编地址和反汇编指令。最后,函数返回了包含所有反汇编指令的opcode_list列表。
from capstone import *
import pefile
def Disassembly(FilePath):
opcode_list = []
pe = pefile.PE(FilePath)
ImageBase = pe.OPTIONAL_HEADER.ImageBase
for item in pe.sections:
if str(item.Name.decode('UTF-8').strip(b'\x00'.decode())) == ".text":
# print("虚拟地址: 0x%.8X 虚拟大小: 0x%.8X" %(item.VirtualAddress,item.Misc_VirtualSize))
VirtualAddress = item.VirtualAddress
VirtualSize = item.Misc_VirtualSize
ActualOffset = item.PointerToRawData
StartVA = ImageBase + VirtualAddress
StopVA = ImageBase + VirtualAddress + VirtualSize
with open(FilePath,"rb") as fp:
fp.seek(ActualOffset)
HexCode = fp.read(VirtualSize)
md = Cs(CS_ARCH_X86, CS_MODE_32)
for item in md.disasm(HexCode, 0):
addr = hex(int(StartVA) + item.address)
dic = {"Addr": str(addr) , "OpCode": item.mnemonic + " " + item.op_str}
print("[+] 反汇编地址: {} 参数: {}".format(addr,dic))
opcode_list.append(dic)
return opcode_list
if __name__ == "__main__":
Disassembly("d://lyshark.exe")
当读者运行上方代码片段时,则可输出lyshark.exe程序内text节所有反汇编代码片段,输出效果如下图所示;

接着我们需要读入内存中的PE文件机器码并通过Capstone引擎反汇编为汇编指令集,如下get_memory_disassembly函数则是实现内存反汇编的具体实现细节。
此案例中通过read_memory_byte读入内存完整数据,并使用md.disasm依次反汇编,并最终将结果存储到dasm_memory_dict字典中保存。
import binascii,os,sys
import pefile
from capstone import *
from LyScript32 import MyDebug
# 得到内存反汇编代码
def get_memory_disassembly(address,offset,len):
# 反汇编列表
dasm_memory_dict = []
# 内存列表
ref_memory_list = bytearray()
# 读取数据
for index in range(offset,len):
char = dbg.read_memory_byte(address + index)
ref_memory_list.append(char)
# 执行反汇编
md = Cs(CS_ARCH_X86,CS_MODE_32)
for item in md.disasm(ref_memory_list,0x1):
addr = int(pe_base) + item.address
dasm_memory_dict.append({"address": str(addr), "opcode": item.mnemonic + " " + item.op_str})
return dasm_memory_dict
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
pe_base = dbg.get_local_base()
pe_size = dbg.get_local_size()
print("模块基地址: {}".format(hex(pe_base)))
print("模块大小: {}".format(hex(pe_size)))
# 得到内存反汇编代码
dasm_memory_list = get_memory_disassembly(pe_base,0,pe_size)
print(dasm_memory_list)
dbg.close()
执行如上所示代码,则可输出当前程序内存中的反汇编指令集,并以字典的方式输出,效果图如下所示;

这两项功能实现之后,那么实现内存与磁盘之间的比对工作将变得很容易实现,如下代码中首先通过get_memory_disassembly获取到内存反汇编指令,然后通过get_file_disassembly获取磁盘反汇编指令,并将两者dasm_memory_list[index] != dasm_file_list[index]最比较,以此来判断特定内存是否被挂钩;
import binascii,os,sys
import pefile
from capstone import *
from LyScript32 import MyDebug
# 得到内存反汇编代码
def get_memory_disassembly(address,offset,len):
# 反汇编列表
dasm_memory_dict = []
# 内存列表
ref_memory_list = bytearray()
# 读取数据
for index in range(offset,len):
char = dbg.read_memory_byte(address + index)
ref_memory_list.append(char)
# 执行反汇编
md = Cs(CS_ARCH_X86,CS_MODE_32)
for item in md.disasm(ref_memory_list,0x1):
addr = int(pe_base) + item.address
dic = {"address": str(addr), "opcode": item.mnemonic + " " + item.op_str}
dasm_memory_dict.append(dic)
return dasm_memory_dict
# 反汇编文件中的机器码
def get_file_disassembly(path):
opcode_list = []
pe = pefile.PE(path)
ImageBase = pe.OPTIONAL_HEADER.ImageBase
for item in pe.sections:
if str(item.Name.decode('UTF-8').strip(b'\x00'.decode())) == ".text":
# print("虚拟地址: 0x%.8X 虚拟大小: 0x%.8X" %(item.VirtualAddress,item.Misc_VirtualSize))
VirtualAddress = item.VirtualAddress
VirtualSize = item.Misc_VirtualSize
ActualOffset = item.PointerToRawData
StartVA = ImageBase + VirtualAddress
StopVA = ImageBase + VirtualAddress + VirtualSize
with open(path,"rb") as fp:
fp.seek(ActualOffset)
HexCode = fp.read(VirtualSize)
md = Cs(CS_ARCH_X86, CS_MODE_32)
for item in md.disasm(HexCode, 0):
addr = hex(int(StartVA) + item.address)
dic = {"address": str(addr) , "opcode": item.mnemonic + " " + item.op_str}
# print("{}".format(dic))
opcode_list.append(dic)
return opcode_list
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
pe_base = dbg.get_local_base()
pe_size = dbg.get_local_size()
print("模块基地址: {}".format(hex(pe_base)))
print("模块大小: {}".format(hex(pe_size)))
# 得到内存反汇编代码
dasm_memory_list = get_memory_disassembly(pe_base,0,pe_size)
dasm_file_list = get_file_disassembly("d://lyshark.exe")
# 循环对比内存与文件中的机器码
for index in range(0,len(dasm_file_list)):
if dasm_memory_list[index] != dasm_file_list[index]:
print("地址: {:8} --> 内存反汇编: {:32} --> 磁盘反汇编: {:32}".
format(dasm_memory_list[index].get("address"),dasm_memory_list[index].get("opcode"),dasm_file_list[index].get("opcode")))
dbg.close()
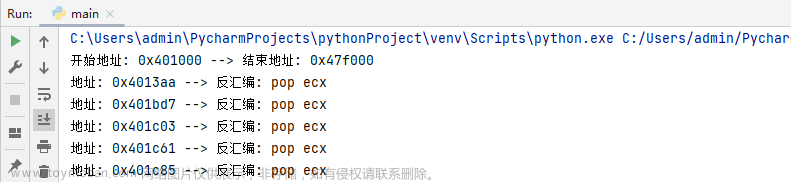
运行上方代码片段,耐性等待一段时间,则可输出内存与磁盘反汇编指令集列表,输出效果图如下所示;文章来源:https://www.toymoban.com/news/detail-540188.html
 文章来源地址https://www.toymoban.com/news/detail-540188.html
文章来源地址https://www.toymoban.com/news/detail-540188.html
到了这里,关于4.7 x64dbg 应用层的钩子扫描的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!