电影票房之数据分析(Hive)
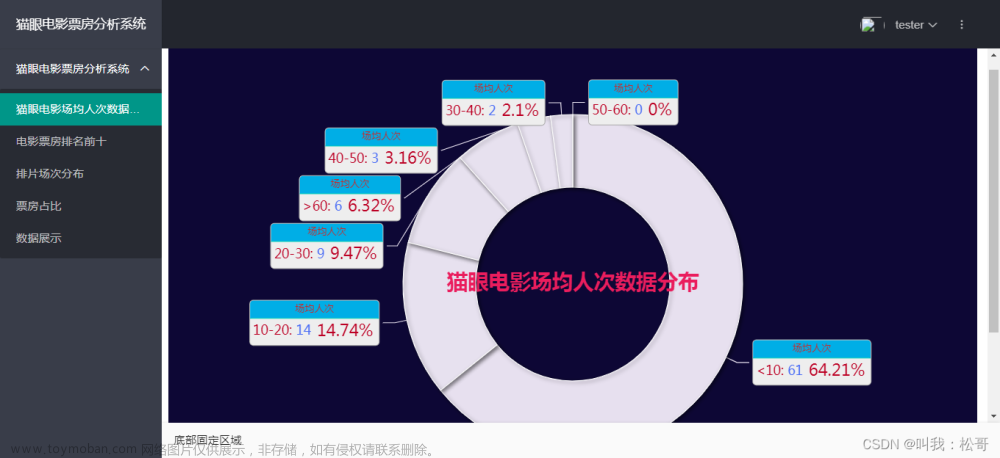
第1关:统计2020年上映的电影中,当前总票房最高的10部电影
#进入hive
hive
#在hive中创建数据库 mydb
create database mydb;
#使用数据库 mydb
use mydb;
#创建表moviecleaned并使用"/t"分割字段
create table moviecleaned(movie_name string,boxoffice string, box_rate string, sessions string, show_count_rate string, avg_number string, attendance string, total_boxoffice string, movie_days string,current_time string,releaseDate string)
row format delimited fields terminated by '\t'
stored as textfile;
#将本地清洗后的数据导入moviecleaned表中
load data local inpath '/data/workspace/myshixun/data/movies.txt' into table moviecleaned;
#创建top10_boxoffice表,用来存放数据查询的结果
create table top10_boxoffice(movie_name string, boxoffice float) row format delimited fields terminated by '\t' stored as textfile;
#查询,并将结果导入top10_boxoffice表中
insert overwrite table top10_boxoffice
select movie_name,max(round(total_boxoffice,1)) m
from moviecleaned
WHERE releaseDate like '2020%'
group by movie_name
ORDER BY m DESC
limit 10;
第2关: 统计2020年国庆假期中电影票房增长最多的三部电影及其每日的票房数据
#创建boxoffice_national_day表,用来存放数据查询的结果
create table boxoffice_national_day(movie_name string, boxoffice float,dates string) row format delimited fields terminated by '\t' stored as textfile;
#查询,并将结果导入boxoffice_national_day表中
insert overwrite table boxoffice_national_day
select movie_name,boxoffice,current_time
from moviecleaned
WHERE movie_name in
(select t.movie_name from(select movie_name,sum(boxoffice) as n from moviecleaned WHERE current_time between '2020-10-01' and '2020-10-07' GROUP BY movie_name order by n desc LIMIT 3) as t)
and current_time between '2020-10-01' and '2020-10-07';
第3关:统计2020年中当日综合总票房最多的10天
#创建day_max_boxoffice表,用来存放数据查询的结果
create table day_max_boxoffice(dates string, boxoffice float)
row format delimited fields terminated by '\t' stored as textfile;
#查询,并将结果导入day_max_boxoffice表中
insert overwrite table day_max_boxoffice
select current_time,round(sum(boxoffice),2) as n
from moviecleaned
WHERE releaseDate like '2020%'
group by current_time
ORDER BY n DESC limit 10;
第4关:统计2020年首映的电影上映后7天的电影票房信息
#创建movie_boxoffice表,用来存放数据查询的结果
create table movie_boxoffice(movie_name string,dates string, boxoffice float)
row format delimited fields terminated by '\t' stored as textfile;
#查询,并将结果导入movie_boxoffice表中
insert overwrite table movie_boxoffice
select t.movie_name,moviecleaned.current_time,boxoffice
from moviecleaned left join
(select movie_name,current_time from moviecleaned WHERE movie_days="上映首日" and releaseDate like "2020%" GROUP BY movie_name,current_time) t
on moviecleaned.movie_name=t.movie_name
WHERE moviecleaned.current_time between t.current_time and DATE_ADD(t.current_time,+6)
ORDER BY t.movie_name,moviecleaned.current_time;
第5关:统计2020年元旦节与国庆节放假后7天的观影人数
#创建movie_boxoffice表,用来存放数据查询的结果文章来源:https://www.toymoban.com/news/detail-540839.html
create table festival_boxoffice(dates string,festival string, num int) row format delimited fields terminated by '\t' stored as textfile;
#查询,并将结果导入movie_boxoffice表中文章来源地址https://www.toymoban.com/news/detail-540839.html
insert overwrite table festival_boxoffice
select split(current_time,'-')[2],case
when t.current_time between '2020-10-01' and '2020-10-07' then 'national_day'
when t.current_time between '2020-01-01' and '2020-01-07' then 'new_year_day'
else 'other' END as festival ,
cast(sum(num) as bigint)
from (select current_time,avg_number*sessions as num from moviecleaned
WHERE current_time between '2020-10-01' and '2020-10-07' or current_time between '2020-01-01' and '2020-01-07') t
GROUP BY current_time;
到了这里,关于电影票房之数据分析(Hive)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!