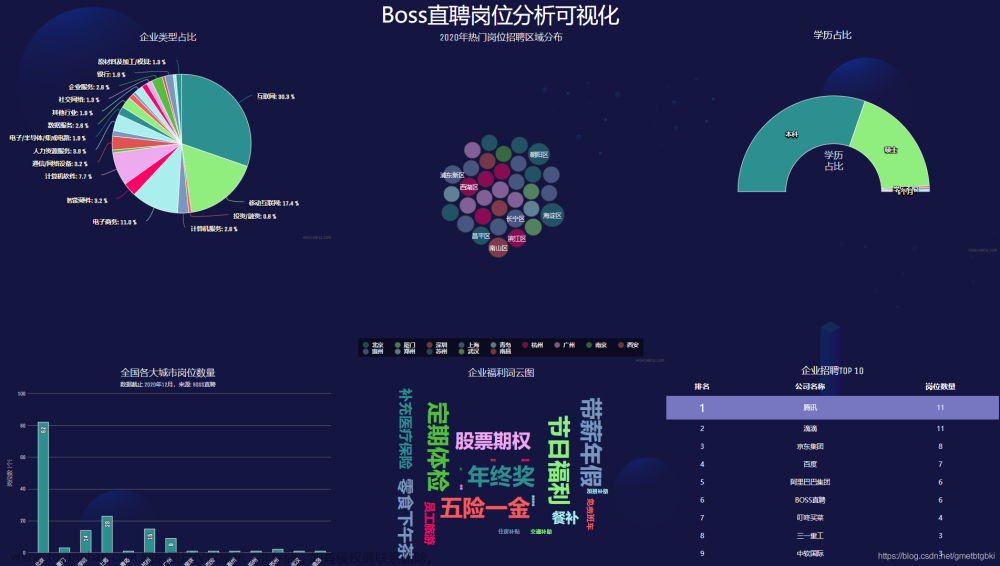
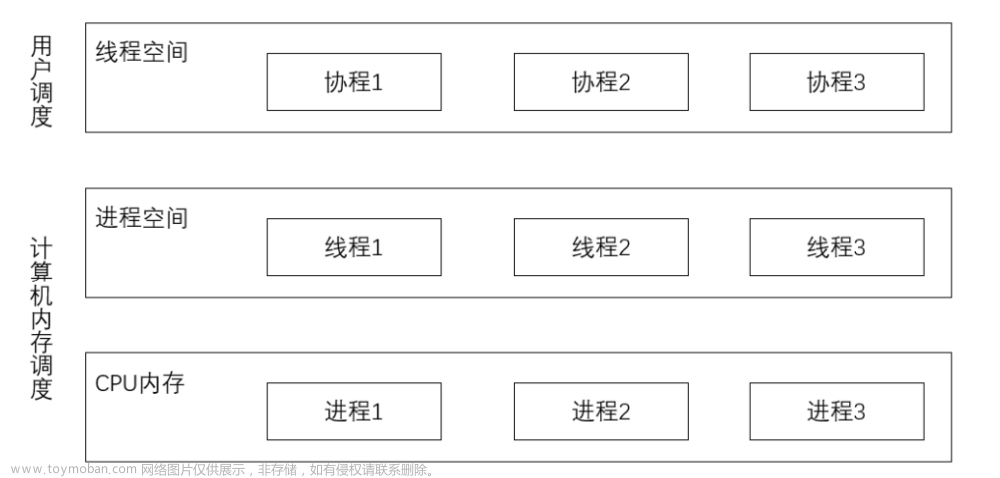
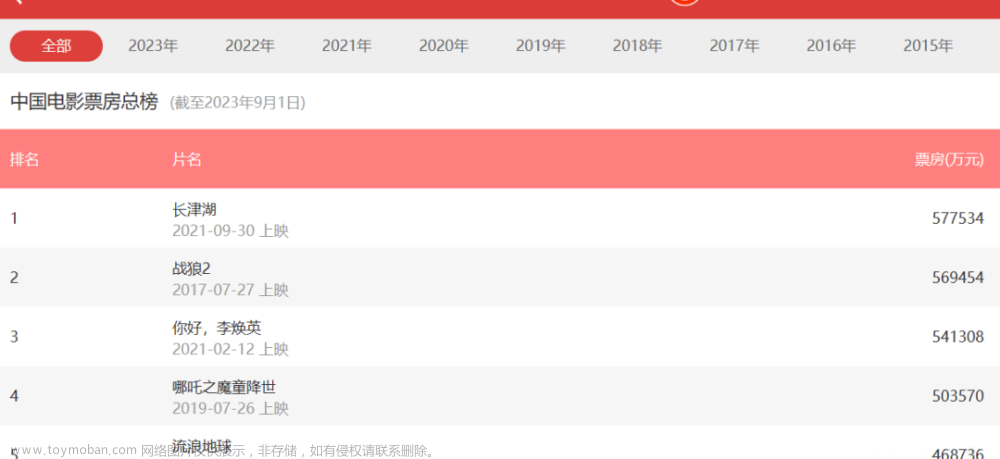
目录
一、模块化概述
二、time库
1. 时间获取
2. 时间格式化
3. 程序计时
三、datetime库
1. datetime.datetime类
2. datetime.timedelta类
四、random库
1. 基本随机函数
2. 扩展随机函数
3. 随机时间的生成
一、模块化概述

Python程序由模块组成,一个模块对应一个 .py 源文件。
模块分为标准库模块和自定义模块(第三方库),函数也分标准库函数和自定义函数。
Python标准库提供了操作系统、网络通信、文件处理、数学运算等基本功能。如:random(随机数)、math(数学运算)、time(时间处理)、file(文件处理)、os(和操作系统交互)、sys(和解释器交互)等。
模块化编程将一个任务分解成多个模块,简化开发过程、实现代码复用、增强可维护性。
我们可以通过help(模块名)查看模块的API。一般使用时先导入模块然后通过help函数查看。
【示例】导入math 模块,并通过help()查看math 模块的API:
import math
help(math)二、time库
time库是Python中处理时间的标准库。
time库常用函数
- 时间获取:time()、ctime()、gmtime()
- 时间格式化:strftime()、strptime()
- 程序计时:sleep()、perf_counter()
1. 时间获取
- time():获取当前的时间戳,返回浮点型
- ctime():获取当前时间,返回字符串
- gmtime():获取当前时间,返回struct_time结构体

2. 时间格式化
时间格式化将时间以特定的字符串格式展示出来,展示模板由特定的格式化控制符组成。
- %Y:年份
- %m:月份,%B:月份名称,%b:月份名称缩写
- %d:日期
- %A:星期,%a:星期简写
- %H:24h制小时,%I:12h制小时
- %M:分钟
- %S:秒钟
strftime(tpl, ts):tpl是格式化模板字符串,用来定义输出效果。ts是tuple类型的计算机内部时间变量,即gmtime()输出的struct_time结构体。tpl是template的缩写。
strptime(timeStr, tpl):将一个时间字符串变成计算机内部可以操作的struct_time()。

3. 程序计时
sleep(s):休眠时间函数,参数s是浮点型的秒数,可以是小数。
perf_counter():返回一个精确的CPU级别的精确时间计数值,单位是秒。通过连续调用计算差值表示程序运行时间。

三、datetime库
datetime库用于处理日期和时间的功能。可以进行日期时间的转换、格式化输出、计算等操作。该库包含了多个类,如datetime、timedelta等,可以根据不同的需求进行选择。
- datetime.datetime:日期和时间的表示
- datetime.timedelta:计算时间间隔
1. datetime.datetime类
datetime.datetime类的使用方式:先创建一个时间对象,再通过对象的方法和属性显示时间。
- datetime.datetime.now():获得当前的日期和时间对象
- datetime.datetime.utcnow():获得当前的日期和时间对象对应的UTC(世界标准)时间对象
- datetime.datetime(year, month, day, hour=0, minute=0, second=0, microsecond=0):通过参数构造一个时间对象
- dt_object.isoformat():按照 ISO 8601 标准显示时间
- dt_object.strftime(tpl):按照格式化字符串控制显示时间
- datetime.datetime.strptime(dt_str, tpl):按照标准格式将字符串转换为时间结构体变量

2. datetime.timedelta类

四、random库
random库是使用随机数的Python标准库。
1. 基本随机函数
- send():初始化随机种子,使得随机数可复用
- random():生成一个[0.0, 1.0]之间的随机小数

2. 扩展随机函数
- randint(a, b):生成一个[a, b]之间的随机整数
- getrandbits(k):生成一个k比特位长的随机整数
- uniform(a, b):生成一个[a, b]之间的随机小数
- choice(seq):从序列seq中随机选择一个元素
- shuffle(seq):将序列seq的元素打乱随机排序
 文章来源:https://www.toymoban.com/news/detail-541001.html
文章来源:https://www.toymoban.com/news/detail-541001.html
3. 随机时间的生成
 文章来源地址https://www.toymoban.com/news/detail-541001.html
文章来源地址https://www.toymoban.com/news/detail-541001.html
到了这里,关于【Python爬虫与数据分析】时间、日期、随机数标准库的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!