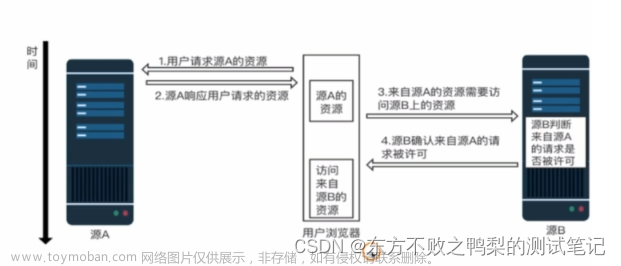
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助

前言
我们打开百度这个网站并刷新多次时时,注意到百度的logo是没有每次都加载一遍的。我们知道图片是img标签中的src属性加载出来的,这也需要浏览器去请求图片资源的,那么为什么刷新多次浏览器只请求了一次图片资源呢?这就涉及到了浏览器的缓存策略了,这张图片被浏览器缓存下来了!
正文
一、为什么要有浏览器的缓存策略?
- 提升用户体验,减少页面重复的http请求
二、为什么通过浏览器url地址栏访问的html页面不缓存?
- 当 强制刷新页面 或 浏览器url地址栏访问资源 时,浏览器
默认会在请求头中设置Cache-control: no-cache,如有设置该属性浏览器就会忽略响应头中的 Cache-control
如何优化网络资源请求的时间呢?有以下三种方式。
三、CDN网络分发
CDN:CDN会通过负载均衡技术,将用户的请求定向到最合适的缓存服务器上去获取内容。
比如说,北京的用户,我们让他访问北京的节点,深圳的用户,我们让他访问深圳的节点。通过就近访问,加速用户对网站的访问,进而解决Internet网络拥堵状况,提高用户访问网络的响应速度。
四、强缓存
强缓存是浏览器的缓存策略,后端设置响应头中的属性值就能设置文件资源在浏览器的缓存时间,过了缓存的有效期再次访问时,文件资源需再次加载。
强缓存有两种方式来控制资源被浏览器缓存的时长:
- 后端设置响应头中的 Cache-control: max-age=3600 来控制缓存时长(为一个小时)
- 后端设置响应头中的 Expires:xxx 来控制缓存的截止日期(截止日期为xxx)
我们直接上代码让你更好理解,我们需要实现一个页面,页面上需展现一个标题及一张图片:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <h1>Earth</h1> <img src="assets/image/earth.jpeg" alt=""> </body> </html>
文章来源:https://www.toymoban.com/news/detail-541645.html
const http = require('http');
const path = require('path');
const fs = require('fs');
const mime = require('mime'); //接收一个文件后缀,返回一个文件类型
const server = http.createServer((req, res) => {
const filePath = path.resolve(__dirname, `www/${req.url}`) //resolve合并地址
if (fs.existsSync(filePath)) { //判断路径是否有效
const stats = fs.statSync(filePath) //获取文件信息
const isDir = stats.isDirectory() //是否是文件夹
if (isDir) {
filePath = path.join(filePath, 'index.html')
}
//读取文件
if (!isDir || fs.existsSync(filePath)) {
//判断前端请求的路径的后缀名是图片还是文本
const { ext } = path.parse(filePath) //.html .jpeg
const time = new Date(Date.now() + 3600000).toUTCString() //定义时间 作为缓存时间的有效期
let status = 200
res.writeHead(status, {
'Content-Type': `${mime.getType(ext)};charset=utf-8`,
'Cache-control': 'max-age=3600', //缓存时长为一小时
// 'expires': time //截止日期 缓存一小时后过期
})
if (status === 200) {
const fileStream = fs.createReadStream(filePath) //将文件读成流类型
fileStream.pipe(res) //将文件流导入响应体
}else{
res.end();
}
}
}
})
server.listen(3000, () => {
console.log('listening on port 3000');
})
第一次运行:

刷新页面后,可以看到图片资源没有重新加载:

三、协商缓存
我们想象这样的场景:当我们偷偷把图片偷偷换成另一张图片,图片名依然和之前那张一样,会是什么结果呢?
操作后,刷新页面发现图片还是之前那张图片,并没有换成新的!那这就出事儿了,后端图片换了,用户看到的还是老图片,有一种方案是改变图片资源的名字,直接请求最新图片资源,但这并不是最优方案,终极方案是需要协商缓存的帮忙。
协商缓存也是浏览器的缓存策略,它也有两种方式辅助强缓存,来判断文件资源是否被修改:
1. 后端设置响应头中的 last-modified: xxxx
- 辅助强缓存,让URL地址栏请求的资源也能被缓存
- 辅助强缓存,借助请求头中的if-modified-since来判断资源文件是否被修改,如果被修改则返回新的资源,否则返回304状态码,让前端读取本地缓存
代码如下:
const http = require('http');
const path = require('path');
const fs = require('fs');
const mime = require('mime'); //接收一个文件后缀,返回一个文件类型
const server = http.createServer((req, res) => {
const filePath = path.resolve(__dirname, `www/${req.url}`) //resolve合并地址
if (fs.existsSync(filePath)) { //判断路径是否有效
const stats = fs.statSync(filePath) //获取文件信息
const isDir = stats.isDirectory() //是否是文件夹
if (isDir) {
filePath = path.join(filePath, 'index.html')
}
//读取文件
if (!isDir || fs.existsSync(filePath)) {
//判断前端请求的路径的后缀名是图片还是文本
const { ext } = path.parse(filePath) //.html .jpeg
const time = new Date(Date.now() + 3600000).toUTCString() //定义时间 作为缓存时间的有效期
const timeStamp = req.headers['if-modified-since'] //请求头的if-modified-since字段
let status = 200
//判断文件是否修改过
if (timeStamp && Number(timeStamp) === stats.mtimeMs) { //timeStamp为字符串 转换为number类型判断
status = 304
}
res.writeHead(status, {
'Content-Type': `${mime.getType(ext)};charset=utf-8`,
'Cache-control': 'max-age=3600', //缓存时长为一小时 //max-age=0或no-cache不需要缓存
// 'expires': time //截止日期 缓存一小时后过期
'last-modified': stats.mtimeMs //文件最后一次修改时间
})
if (status === 200) {
const fileStream = fs.createReadStream(filePath) //将文件读成流类型
fileStream.pipe(res) //将文件流导入响应体
}else{
res.end();
}
}
}
})
server.listen(3000, () => {
console.log('listening on port 3000');
})

2. Etag:文件的标签
- 请求头中会被携带If-None-Match
- Etag保证了每一个资源是唯一的,资源变化都会导致Etag变化。服务器根据If-None-Match值来判断是否命中缓存。 当服务器返回304的响应时,由于ETag重新生成过,response header中还会把这个ETag返回,即使这个ETag跟之前的没有变化。

代码如下:
const http = require('http');
const path = require('path');
const fs = require('fs');
const mime = require('mime'); //接收一个文件后缀,返回一个文件类型
const md5 = require('crypto-js/md5');
const server = http.createServer((req, res) => {
const filePath = path.resolve(__dirname, `www/${req.url}`) //resolve合并地址
if (fs.existsSync(filePath)) { //判断路径是否有效
const stats = fs.statSync(filePath) //获取文件信息
const isDir = stats.isDirectory() //是否是文件夹
if (isDir) {
filePath = path.join(filePath, 'index.html')
}
//读取文件
if (!isDir || fs.existsSync(filePath)) {
//判断前端请求的路径的后缀名是图片还是文本
const { ext } = path.parse(filePath) //.html .jpeg
const content = fs.readFileSync(filePath);
let status = 200
//判断文件是否被修改过
if (req.headers['if-none-match'] == md5(content)) {
status=304
}
res.writeHead(status, {
'Content-Type': `${mime.getType(ext)};charset=utf-8`,
'Cache-control': 'max-age=3600', //缓存时长为一小时 //max-age=0或no-cache不需要缓存
'Etag': md5(content) //文件资源的md5值
})
if (status === 200) {
const fileStream = fs.createReadStream(filePath) //将文件读成流类型
fileStream.pipe(res) //将文件流导入响应体
} else {
res.end();
}
}
}
})
server.listen(3000, () => {
console.log('listening on port 3000');
})
结
最后附上一张图便于更好理解浏览器的缓存策略:

本文转载于:
https://juejin.cn/post/7253675120010199101
如果对您有所帮助,欢迎您点个关注,我会定时更新技术文档,大家一起讨论学习,一起进步。
 文章来源地址https://www.toymoban.com/news/detail-541645.html
文章来源地址https://www.toymoban.com/news/detail-541645.html
到了这里,关于记录--关于浏览器缓存策略这件事儿的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!