引言: MySQL的视图(View)是由一个或多个查询语句生成的虚拟表,它基于存储在数据库中的表数据,并且具有与实际表相似的结构。
视图在数据库中作为一个独立的对象存在,可以被视为存储了查询结果的虚拟表。创建视图后,您可以像使用表一样查询视图,无需重复编写复杂的查询语句。
1.视图的主要作用包括:
1.简化查询:
通过使用视图,您可以封装和重用常见的查询逻辑,简化复杂查询操作,减少代码的重复编写,提高开发效率。
2.数据安全性:
视图可以限制用户对数据的访问权限,只显示特定的列或行,保护敏感数据的安全性。
3.数据抽象:
通过视图,您可以隐藏数据的真实结构,使用户能够以更简单、更直观的方式进行数据操作,提供数据的逻辑上的抽象。
性能优化:在某些情况下,视图可以通过预先计算和储存结果,提高查询性能。
总之,视图提供了一种便捷的方式来处理和操作数据库中的数据,提升了数据库的灵活性、安全性和性能。
2.索引简介
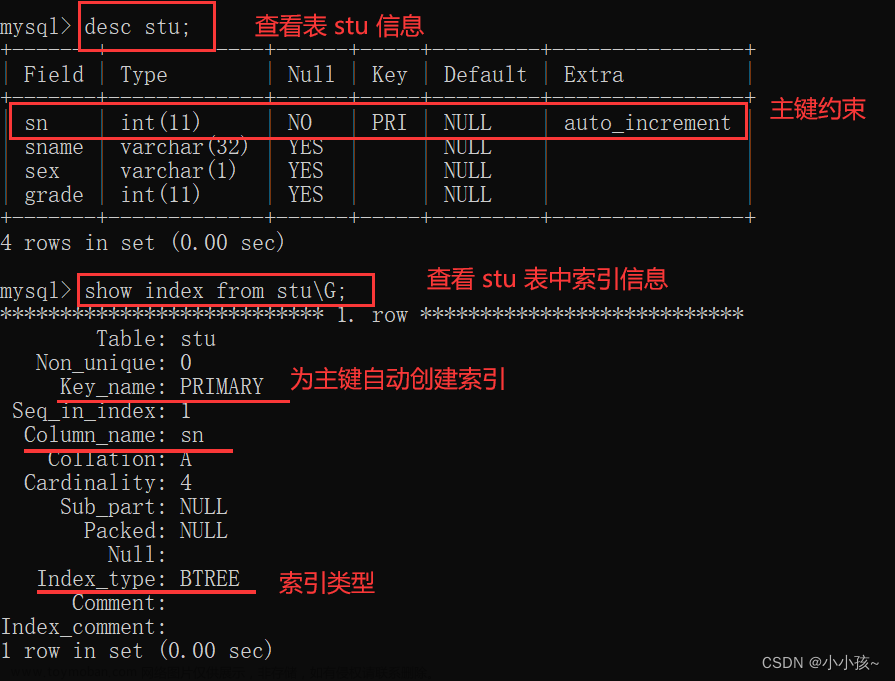
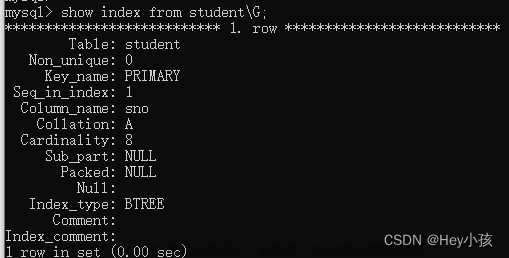
索引是数据库中一种用于提高数据检索速度的数据结构。它是在表上创建的特殊数据结构,通过将索引值与实际数据的位置建立映射关系,可以加快对表中数据的查找和查询操作。
1.索引的作用主要有以下几个方面:
1.快速定位数:
索引可以帮助数据库系统快速定位到满足特定条件的数据行,避免了逐行扫描整个表的时间消耗。通过利用索引,数据库可以直接跳过大量不符合条件的数据,提高查询效率。
2. 提高查询性能
当执行查询语句时,数据库会首先尝试使用索引来定位目标数据,这样可以减少磁盘I/O操作和CPU资源的消耗,从而提高查询速度和响应时间。
3.加速排序和连接操作
索引的存在可以加快排序和连接操作的执行速度。例如,在进行ORDER BY子句排序或者进行JOIN操作时,索引可以避免对整个表进行排序或者全表扫描,而是优先利用索引的有序性和映射关系,提升排序和连接操作的效率。
4.维护数据完整性
通过设置唯一索引或主键索引,可以确保表中的数据在相应列上具有唯一性,防止出现重复或缺失的数据。
需要注意的是,索引并非无代价的,它会占用额外的存储空间,并在插入、更新和删除操作时对性能产生一定的影响。过多或不合理地创建索引可能会导致索引冗余和性能下降。因此,在设计数据库时,需要根据实际需求和查询模式来选择合适的列进行索引,并避免过度索引。
综上所述,索引是用于加速数据检索和提高查询性能的关键
3.索引的优缺点
索引在数据库中具有以下优点:
1.提高查询性能:
索引可以大幅提高数据库的查询速度。通过使用索引,数据库可以快速定位到符合查询条件的数据行,而不需要逐行扫描整个表。这样可以减少查询所需的时间和资源消耗。
2.加速排序和连接操作
对于排序和连接操作,索引可以显着提高性能。通过使用索引,数据库可以按照索引列的顺序进行排序,或者直接利用索引列进行连接操作,从而避免了全表扫描和多次磁盘访问的开销。
3.保证数据完整性
唯一索引和主键索引可以确保索引列的值具有唯一性,防止出现重复记录。这对于保证数据的完整性和一致性非常重要。
4.支持快速查找
索引使得数据库可以以快速的方式定位到目标数据,无论是基于全值匹配还是范围查询。通过遵循索引的树形结构,数据库可以迅速确定查询满足条件的数据行,提高了查找操作的效率。
然而,索引也存在一些缺点和注意事项:
5.占用存储空间
索引需要占用额外的存储空间,因为它们存储了索引列的值和对应的数据行位置。对于大型表和多个索引的情况,索引可能会显著增加存储需求。
6.增加写操作的开销
在执行插入、更新和删除操作时,索引需要进行维护,以保持与实际数据的一致性。这些维护操作会带来额外的开销,并可能降低写操作的性能。
不适用于所有查询:并非所有的查询都能从索引中获益。某些查询条件可能无法有效利用索引,导致查询仍需要进行全表扫描。此外,过多或不合理的索引可能会降低整体性能。
索引选择和设计需要慎重考虑:选择合适的索引列和索引类型是非常重要的。错误的索引选择可能导致索引失效或影响性能。此外,随着数据的变化和业务需求的演变,索引也需要进行定期的优化和调整。
综上所述,索引在提高数据库查询性能和数据完整性方面发挥了重要作用。然而,使用索引需要权衡其优缺点,并根据具体情况进行合理的设计和管理。
4.索引可能会在以下情况下失效:
1.不使用索引列进行匹配
如果查询条件中没有包含索引列或者对索引列进行了函数操作、类型转换等,数据库可能无法有效地利用索引,导致索引失效。
2.使用范围查询或排序操作
对于范围查询(例如使用大于、小于等操作符)或排序操作,索引可以提供一定的效率提升。然而,如果查询结果需要返回大部分数据或者进行复杂的排序操作,相比全表扫描,索引可能无法提供显著的性能优势。
3.数据分布不均匀
如果索引列的数据分布不均匀,即某些值出现频率很高,而其他值出现频率很低,那么索引的选择性就会变差。在这种情况下,数据库可能会放弃使用索引进行查询,直接进行全表扫描。
4.更新频繁
当对包含索引列的数据进行频繁的插入、更新和删除操作时,索引需要维护和更新以保持与实际数据的一致性。这些维护操作会带来额外的开销,并可能导致索引性能下降。
5.索引列数据类型选择不合理
选择错误的数据类型或字段长度可能导致索引失效。比如选择了过长的数据类型或者过短的数据类型,在索引中会造成空间浪费或者无法正确存储索引列的值。
6.索引统计信息不准确
数据库通过统计信息来评估查询计划和选择合适的索引。如果统计信息不准确或过时,数据库可能会做出错误的优化选择,导致索引失效。
7.索引碎片化
当数据进行频繁的插入、更新和删除时,索引可能会发生碎片化,即索引数据节点的物理存储位置不连续。这可能导致索引扫描和访问开销增加,性能下降。
为了避免索引失效,需要根据具体情况进行合理的索引设计,包括选择适当的索引列、数据类型和长度,保持索引统计信息的准确性,定期进行索引维护和优化。
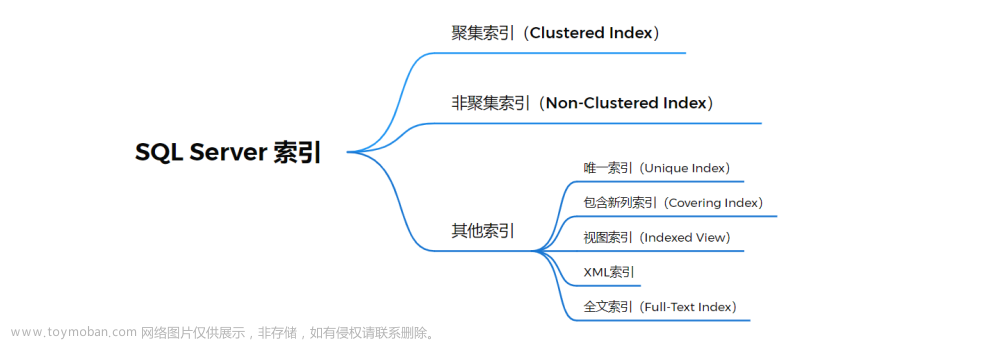
5.索引分类
MySQL索引可以根据其不同的特点进行分类。以下是几种常见的MySQL索引分类:
主键索引(Primary Key Index):主键索引用于标识表中的唯一记录。每个表只能有一个主键,通常使用自增长整数作为主键。下面是创建主键索引的示例代码:
sql
CREATE TABLE mytable (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
age INT
);
唯一索引(Unique Index):唯一索引确保列中的值是唯一的,但允许NULL值存在。表中可以有多个唯一索引。下面是创建唯一索引的示例代码:
sql
CREATE TABLE mytable (
id INT,
email VARCHAR(50) UNIQUE,
name VARCHAR(50)
);
普通索引(Normal Index):普通索引是最基本的索引类型,没有任何限制。它可以加快查询速度,但不强制值的唯一性或空值的检查。下面是创建普通索引的示例代码:
sql
CREATE TABLE mytable (
id INT,
name VARCHAR(50),
INDEX idx_name (name)
);
全文索引(Full-Text Index):全文索引用于对文本列进行全文搜索。它可以处理大型的文本数据,并提供更高效的搜索功能。下面是创建全文索引的示例代码:
sql
CREATE TABLE mytable (
id INT,
content TEXT,
FULLTEXT INDEX idx_content (content)
);
组合索引(Composite Index):组合索引是由多个列组成的索引。它可以提高多列条件查询的性能,但要注意避免创建过多的组合索引。下面是创建组合索引的示例代码:
sql
CREATE TABLE mytable (
id INT,
name VARCHAR(50),
age INT
6.数据库的备份与恢复
1.使用mysqldump导入导出
D导出命令
:\SoftwareInstallPath\mysql-8.0.13-winx64\bin>mysqldump -uroot
-p123456 mybatis_ssm > 1234567.sql
导入
注意:首先建立空数据库
– mysql>create database abc;
– 2.2.1 方法一
– mysql>use abc; #选择数据库
– mysql>set names utf8; #设置数据库编码
– mysql>source /D:/SoftwareInstallPath/mysql-8.0.13-winx64/bin/1234567.sql; #导入数据

6.LOAD DATA INFILE
是MySQL中用于将数据从文本文件导入到数据库表中的语句。它允许快速导入大量数据,并且比逐行插入数据更高效。
以下是LOAD DATA INFILE语句的基本语法:
LOAD DATA INFILE 'file_name'
[REPLACE | IGNORE]
INTO TABLE table_name
[CHARACTER SET charset_name]
[FIELDS
[TERMINATED BY 'field_terminator']
[ENCLOSED BY 'enclosure_character']
[ESCAPED BY 'escape_character']
]
[LINES
[STARTING BY 'line_prefix']
[TERMINATED BY 'line_terminator']
]
[IGNORE number LINES]
(column1, column2, column3, ...)
接下来,我将逐个解释这些参数的作用:
file_name:指定要导入的文本文件路径和文件名。
REPLACE和IGNORE:可选参数,在导入过程中控制处理重复数据行的方式。REPLACE会替换已存在的行,而IGNORE会跳过已存在的行,默认情况下是追加数据。
table_name:指定要导入数据的目标表名。
CHARACTER SET charset_name:可选参数,指定文本文件的字符集。
FIELDS子句:用来指定字段的分隔符、引用符和转义符等。
TERMINATED BY ‘field_terminator’:指定字段之间的分隔符,默认为制表符\t。
ENCLOSED BY ‘enclosure_character’:可选参数,指定字段的引用符,默认为空字符串。
ESCAPED BY ‘escape_character’:可选参数,指定转义符,默认为反斜杠\。
LINES子句:用来指定行的前缀和分隔符等。
STARTING BY ‘line_prefix’:可选参数,指定行的前缀,默认为空字符串。
TERMINATED BY ‘line_terminator’:指定行的分隔符,默认为换行符\n。
IGNORE number LINES:可选参数,指定忽略文件开始部分的行数。
(column1, column2, column3, …):可选参数,指定导入数据时要插入的列。如果省略,则默认导入所有列。
下面是一个示例,展示如何使用LOAD DATA INFILE导入数据:
sql
CREATE TABLE students (
id INT,
name VARCHAR(50),
age INT
);
LOAD DATA INFILE '/path/to/file.csv'
INTO TABLE students
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(id, name, age);
在这个示例中,我们创建了一个名为students的表,包含id、name和age三个列。然后,我们使用LOAD DATA INFILE语句将位于/path/to/file.csv的CSV文件中的数据导入到该表中。CSV文件中的字段由逗号分隔,并用双引号括起来,行则由换行符分隔。在导入过程中,我们忽略了第一行标题行,并只插入了id、name和age三个列的数据。文章来源:https://www.toymoban.com/news/detail-542054.html
希望这个例子能够帮助你理解LOAD DATA INFILE的用法。文章来源地址https://www.toymoban.com/news/detail-542054.html
到了这里,关于视图与索引的详细用法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!