源代码+4千字报告



需要源代码+数据库+可视化+数据+4千字报告加我qq
文章来源地址https://www.toymoban.com/news/detail-542333.html文章来源:https://www.toymoban.com/news/detail-542333.html
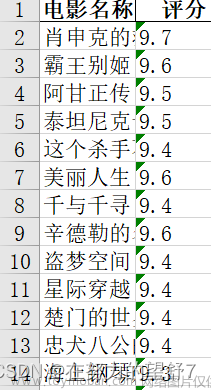
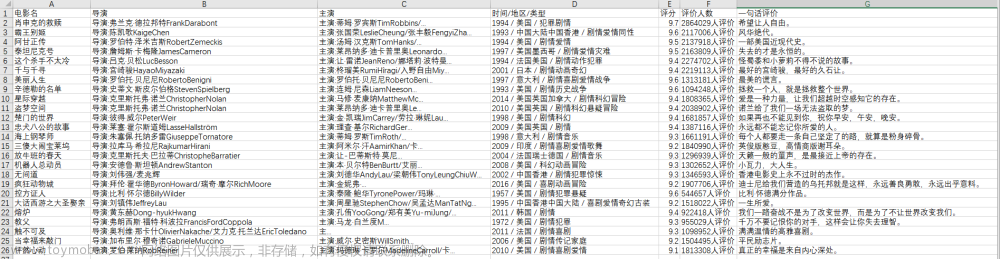
到了这里,关于python爬虫爬取top250中排名、评分、导演等展示可视化界面的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[Python练习]使用Python爬虫爬取豆瓣top250的电影的页面源码](https://imgs.yssmx.com/Uploads/2024/02/797225-1.png)