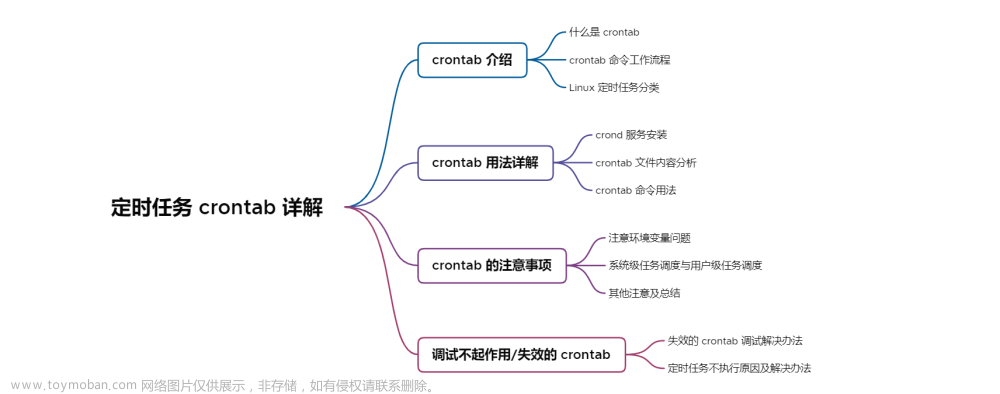
作为linux中最为常用的三大文本(awk,sed,grep)处理工具之一,掌握好其用法是很有必要的。
首先谈一下grep命令的常用格式为:grep [选项] ”模式“ [文件]
grep家族总共有三个:grep,egrep,fgrep。
命令用法如下:

查看grep命令的帮助信息:
grep --help
Regexp selection and interpretation:
-E, --extended-regexp PATTERN is an extended regular expression (ERE)
-F, --fixed-strings PATTERN is a set of newline-separated fixed strings
-G, --basic-regexp PATTERN is a basic regular expression (BRE)
-P, --perl-regexp PATTERN is a Perl regular expression
-e, --regexp=PATTERN use PATTERN for matching
-f, --file=FILE obtain PATTERN from FILE
-i, --ignore-case ignore case distinctions
-w, --word-regexp force PATTERN to match only whole words
-x, --line-regexp force PATTERN to match only whole lines
-z, --null-data a data line ends in 0 byte, not newline
Miscellaneous:
-s, --no-messages suppress error messages
-v, --invert-match select non-matching lines
-V, --version display version information and exit
--help display this help text and exit
Output control:
-m, --max-count=NUM stop after NUM matches
-b, --byte-offset print the byte offset with output lines
-n, --line-number print line number with output lines
--line-buffered flush output on every line
-H, --with-filename print the file name for each match
-h, --no-filename suppress the file name prefix on output
--label=LABEL use LABEL as the standard input file name prefix
-o, --only-matching show only the part of a line matching PATTERN
-q, --quiet, --silent suppress all normal output
--binary-files=TYPE assume that binary files are TYPE;
TYPE is 'binary', 'text', or 'without-match'
-a, --text equivalent to --binary-files=text
-I equivalent to --binary-files=without-match
-d, --directories=ACTION how to handle directories;
ACTION is 'read', 'recurse', or 'skip'
-D, --devices=ACTION how to handle devices, FIFOs and sockets;
ACTION is 'read' or 'skip'
-r, --recursive like --directories=recurse
-R, --dereference-recursive
likewise, but follow all symlinks
--include=FILE_PATTERN
search only files that match FILE_PATTERN
--exclude=FILE_PATTERN
skip files and directories matching FILE_PATTERN
--exclude-from=FILE skip files matching any file pattern from FILE
--exclude-dir=PATTERN directories that match PATTERN will be skipped.
-L, --files-without-match print only names of FILEs containing no match
-l, --files-with-matches print only names of FILEs containing matches
-c, --count print only a count of matching lines per FILE
-T, --initial-tab make tabs line up (if needed)
-Z, --null print 0 byte after FILE name
Context control:
-B, --before-context=NUM print NUM lines of leading context
-A, --after-context=NUM print NUM lines of trailing context
-C, --context=NUM print NUM lines of output context
-NUM same as --context=NUM
--group-separator=SEP use SEP as a group separator
--no-group-separator use empty string as a group separator
--color[=WHEN],
--colour[=WHEN] use markers to highlight the matching strings;
WHEN is 'always', 'never', or 'auto'
-U, --binary do not strip CR characters at EOL (MSDOS/Windows)
-u, --unix-byte-offsets report offsets as if CRs were not there
(MSDOS/Windows)
'egrep' means 'grep -E'. 'fgrep' means 'grep -F'.
Direct invocation as either 'egrep' or 'fgrep' is deprecated.
When FILE is -, read standard input. With no FILE, read . if a command-line
-r is given, - otherwise. If fewer than two FILEs are given, assume -h.
Exit status is 0 if any line is selected, 1 otherwise;
if any error occurs and -q is not given, the exit status is 2.
常用选项:
-E :开启扩展(Extend)的正则表达式。
-i :忽略大小写(ignore case)。
-v :反过来(invert),只打印没有匹配的,而匹配的反而不打印。
-n :显示行号
-w :被匹配的文本只能是单词,而不能是单词中的某一部分,如文本中有liker,而我搜寻的只是like,就可以使用-w选项来避免匹配liker
-c :显示总共有多少行被匹配到了,而不是显示被匹配到的内容,注意如果同时使用-cv选项是显示有多少行没有被匹配到。
-o :只显示被模式匹配到的字符串。
--color :将匹配到的内容以颜色高亮显示。
-A n:显示匹配到的字符串所在的行及其后n行,after
-B n:显示匹配到的字符串所在的行及其前n行,before
-C n:显示匹配到的字符串所在的行及其前后各n行,context
模式部分:
1、直接输入要匹配的字符串,这个可以用fgrep(fast grep)代替来提高查找速度,比如我要匹配一下hello.c文件中printf的个数:fgrep -c "printf" hello.c
2、使用基本正则表达式,下面谈关于基本正则表达式的使用:
匹配字符:
. :任意一个字符。
[abc] :表示匹配一个字符,这个字符必须是abc中的一个。
[a-zA-Z] :表示匹配一个字符,这个字符必须是a-z或A-Z这52个字母中的一个。
[^123] :匹配一个字符,这个字符是除了1、2、3以外的所有字符。
对于一些常用的字符集,系统做了定义:
[A-Za-z] 等价于 [[:alpha:]]
[0-9] 等价于 [[:digit:]]
[A-Za-z0-9] 等价于 [[:alnum:]]
tab,space 等空白字符 [[:space:]]
[A-Z] 等价于 [[:upper:]]
[a-z] 等价于 [[:lower:]]
标点符号 [[:punct:]]
匹配次数:
\{m,n\} :匹配其前面出现的字符至少m次,至多n次。
\? :匹配其前面出现的内容0次或1次,等价于\{0,1\}。
* :匹配其前面出现的内容任意次,等价于\{0,\},所以 ".*" 表述任意字符任意次,即无论什么内容全部匹配。
位置锚定:
^ :锚定行首
$ :锚定行尾。技巧:"^$"用于匹配空白行。
\b或\<:锚定单词的词首。如"\blike"不会匹配alike,但是会匹配liker
\b或\>:锚定单词的词尾。如"\blike\b"不会匹配alike和liker,只会匹配like
\B :与\b作用相反。

分组及引用:
\(string\) :将string作为一个整体方便后面引用
\1 :引用第1个左括号及其对应的右括号所匹配的内容。
\2 :引用第2个左括号及其对应的右括号所匹配的内容。
\n :引用第n个左括号及其对应的右括号所匹配的内容。
扩展的(Extend)正则表达式(注意要使用扩展的正则表达式要加-E选项,或者直接使用egrep):文章来源:https://www.toymoban.com/news/detail-542593.html
文章来源地址https://www.toymoban.com/news/detail-542593.html
到了这里,关于linux中grep命令的常见用法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!