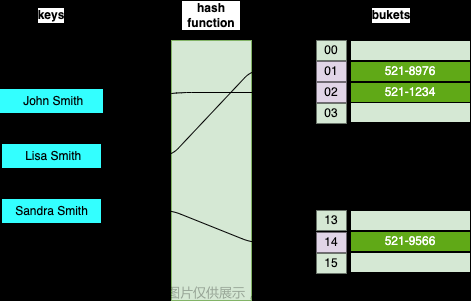
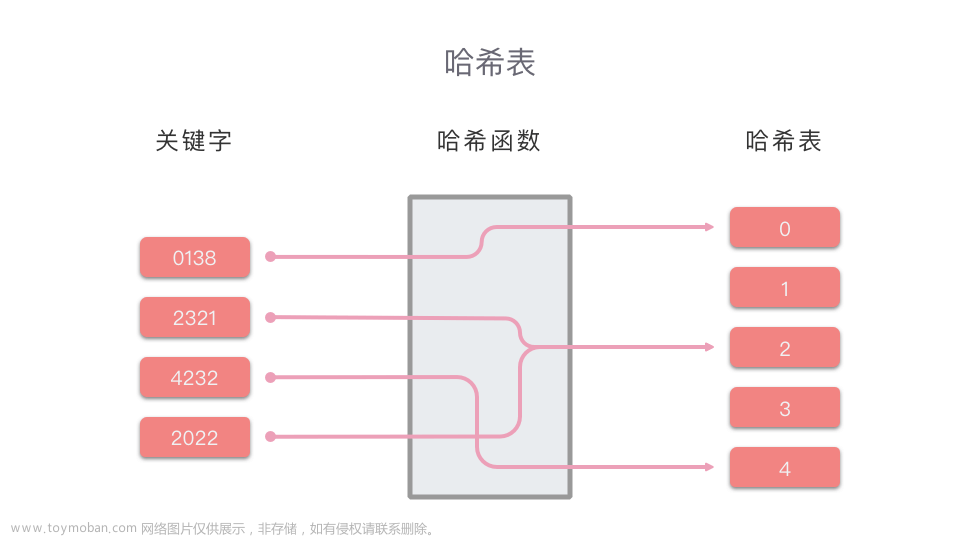
哈希表(Hash Table),它通过使用一个哈希函数将键 (key) 映射到存储实际数据(键值对)的地方来实现对值 (value) 的查找。
这是它的工作原理:
1. 当你想要存储一个键值对时,哈希表首先会使用哈希函数对键进行哈希计算,得到一个哈希值。
键值对(Key-Value Pair)是一种常用的数据结构,用来存储两个相关联的元素。在这个对应关系中,"键"(Key)是唯一的,用于标识和查找与之关联的"值"(Value)。
举个例子,假设我们有一个学生名单的数据库,我们可能会用学生的ID作为键,学生的详细信息(如名字、年龄、班级等)作为值。这样,当我们需要查找一个学生的信息时,我们只需要知道他的ID,就可以快速找到他的所有信息。在这个例子中,学生的ID和他的信息就形成了一个键值对。
2. 然后,哈希表会使用这个哈希值(经过某种处理)作为索引,将值存储在一个特定的桶或槽中(存储实际数据(键值对)的地方)。
3. 当你想要获取某个键对应的值时,哈希表会再次使用哈希函数对键进行哈希计算,找到对应的桶或槽(存储实际数据(键值对)的地方),然后返回其中的值。
哈希表的优点是查找、插入和删除的平均时间复杂度可以接近 O(1),非常高效。但是,哈希表的一个挑战是如何处理哈希冲突,也就是两个不同的键经过哈希函数计算得到了相同的哈希值的情况。常见的处理哈希冲突的方法有开放定址法、链地址法等。
此外,哈希表需要占用一定的内存空间,以存储键值对和处理哈希冲突,这是它的一个可能的缺点。
具体例子如下:
哈希表用的是数组支持按照下标随机访问数据的特性,所以哈希表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。

哈希表存储的是由键(key)和值(value)组成的数据。 例如,我们将每个人的性别作为数据进行存储,键为人名,值为对应的性别,其中 M 表示性别为男,F 表示性别为女。

为了和哈希表进行对比,我们先将这些数据存储在数组中。

文章来源地址https://www.toymoban.com/news/detail-542995.html
此处准备了6个箱子(即长度为6的数组)来存储数据,假设我们需要查询 Ally 的性别,由于不知道 Ally 的数据存储在哪个箱子里,所以只能从头开始查询,这个操作便叫作线性查找。一般来说,我们可以把键当成数据的标识符,把值当成数据的内容。

从 0 号箱子开始查找,发现 0 号箱子中存储的键是 Joe 而不是 Ally,因此接着查找 1 号箱子。

哦豁,1 号箱子中的也不是 Ally,没办法,只能接着往下找。

有点小糟糕,2 号、3 号箱子中的也都不是 Ally。

文章来源:https://www.toymoban.com/news/detail-542995.html
功夫不负有心人,当我们查找到 4 号箱子的时候,发现其中数据的键为 Ally,把键对应的值取出,我们就知道 Ally 的性别为女(F)。
通过上面的查找过程,我们发现数据量越多,线性查找耗费的时间就越长。由此可知:由于数据的查询较为耗时,所以此处并不适合使用数组来存储数据。

但使用哈希表便可以解决这个问题,首先准备好数组,这次我们用 5 个箱子的数组来存储数据。

尝试把 Joe 存进去,使用哈希函数(Hash)计算 Joe 的键,也就是字符串 Joe 的哈希值,比如得到的结果为4928。

将得到的哈希值除以数组的长度 5,求得其余数,这样的求余运算叫作mod运算,此处mod运算的结果为3。

因此,我们将 Joe 的数据存进数组的 3 号箱子中,重复前面的操作,将其他数据也存进数组中。

Sue 键的哈希值为 7291, mod 5 的结果为 1,将 Sue 的数据存进 1 号箱中。

Dan 键的哈希值为 1539, mod 5 的结果为 4,将 Dan 的数据存进 4 号箱中。

Nell 键的哈希值为 6276, mod 5 的结果为 1,本应将其存进数组的 1 号箱中,但此时 1 号箱中已经存储了 Sue 的数据,这种存储位置重复了的情况便叫作冲突。

遇到这种情况,可使用链表在已有数据的后面继续存储新的数据(链表法)。

Ally 键的哈希值为 9143, mod 5 的结果为 3,本应将其存储在数组的 3 号箱中,但 3 号箱中已经有了 Joe 的数据,所以使用链表,在其后面存储 Ally 的数据。

Bob 键的哈希值为 5278, mod 5 的结果为 3,本应将其存储在数组的 3 号箱中,但 3 号箱中已经有了 Joe 和 Ally 的数据,所以使用链表,在 Ally 的后面继续存储 Bob 的数据。

像这样存储完所有数据,哈希表也就制作完成了。

接下来讲解数据的查询方法,假设我们要查询 Dan 的性别。

为了知道 Dan 存储在哪个箱子里,首先需要算出 Dan 键的哈希值,然后对其进行 mod 运算,最后得到的结果为 4,于是我们知道了它存储在 4 号箱中。

查看 4 号箱可知,其中的数据的键与 Dan 一致,于是取出对应的值,由此我们便知道了 Dan 的性别为男(M)。

那么,想要查询 Ally 的性别时该怎么做呢?为了找到它的存储位置,先要算出 Ally 键的哈希值,再对其进行 mod 运算,最终得到的结果为 3。

然而 3 号箱中数据的键是 Joe 而不是 Ally,此时便需要对 Joe 所在的链表进行线性查找。

于是我们找到了键为 Ally 的数据,取出其对应的值,便知道了 Ally 的性别为女(F)。
哈希冲突
在哈希表中,我们可以利用哈希函数快速访问到数组中的目标数据。如果发生哈希冲突,就使用链表进行存储,这样一来,不管数据量为多少,我们都能够灵活应对。
如果数组的空间太小,使用哈希表的时候就容易发生冲突,线性查找的使用频率也会更高;反过来,如果数组的空间太大,就会出现很多空箱子,造成内存的浪费。因此,给数组设定合适的空间非常重要。
在存储数据的过程中,如果发生冲突,可以利用链表在已有数据的后面插入新数据来解决冲突,这种方法被称为链表法,也被称为链地址法。
除了链地址法以外,还有几种解决冲突的方法。其中,应用较为广泛的是开放地址法,或称为开放寻址法。这种方法是指当冲突发生时,立刻计算出一个候补地址(数组上的位置)并将数据存进去。如果仍然有冲突,便继续计算下一个候补地址,直到有空地址为止,可以通过多次使用哈希函数或线性探测法等方法计算候补地址。
哈希函数设计的好坏决定了哈希冲突的概率,也就决定哈希表的性能。
总结
这篇文章主要讲了一些比较基础的哈希表知识,包括哈希表的由来、哈希冲突的解决方法。哈希表也叫散列表,来源于数组,它借助哈希函数对数组这种数据结构进行扩展,利用的是数组支持按照下标随机访问元素的特性,是存储 Key-Value 映射的集合。
哈希表两个核心问题是哈希函数设计和哈希冲突解决。对于某一个 Key,哈希表可以在接近 O(1) 的时间内进行读写操作。哈希表通过哈希函数实现 Key 和数组下标的转换,通过开放寻址法和链表法来解决哈希冲突。哈希函数设计的好坏决定了哈希冲突的概率,也就决定哈希表的性能。
有兴趣的可以在 JDK 中阅读 HashMap 的源码,在 JDK 8 和之前的版本的实现还有许多不多,比如在 JDK 8 中,引入红黑树,当链表长度太长(默认超过 8)时,链表就转换为红黑树,就可以利用红黑树快速增删改查的特点,提高 HashMap 的性能。
到了这里,关于数据结构——哈希表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!