Stable Diffusion AI 绘画入门指南
市面上用的最多的AI绘画工具是 Stable-Diffusion(SD) 和 Midjourney(Mid),SD是在本地运行的服务,开源,门槛高,但自控性极高。而Mid作为在线的服务,门槛低,效果好,但可控性不够强。
Stable Diffusion(简称SD)是当今最流行的免费、开源的AI绘图模型,可以在电脑本地上离线运行,很多收费的AI绘图底层就使用了Stable Diffusion。而 Stable Diffusion WebUI(简称SDW)是基于Stable Diffusion制作的一个友好的 Web 图形化界面,解决了Stable Diffusion用命令行操作的麻烦。SD用户能够随心所欲地训练自己的模型和LORA,乃至引入ControlNet用各类工具来控制AI绘画出图的内容。甚至还可以指定区域重绘。
推荐极客时间课程:http://gk.link/a/1276o
在线体验
Stable Diffusion Demo,这是官方发布的一个简单的体验版,无需登录只需要提示词,然后点击生成按钮即可。
本机安装
要顺利运行 stable-diffusion-webui 和模型, 需要足够的显存,最低配置4GB显存,基本配置6GB显存,推荐配置12GB显存。 电脑内存也不能太小,最好大于16GB
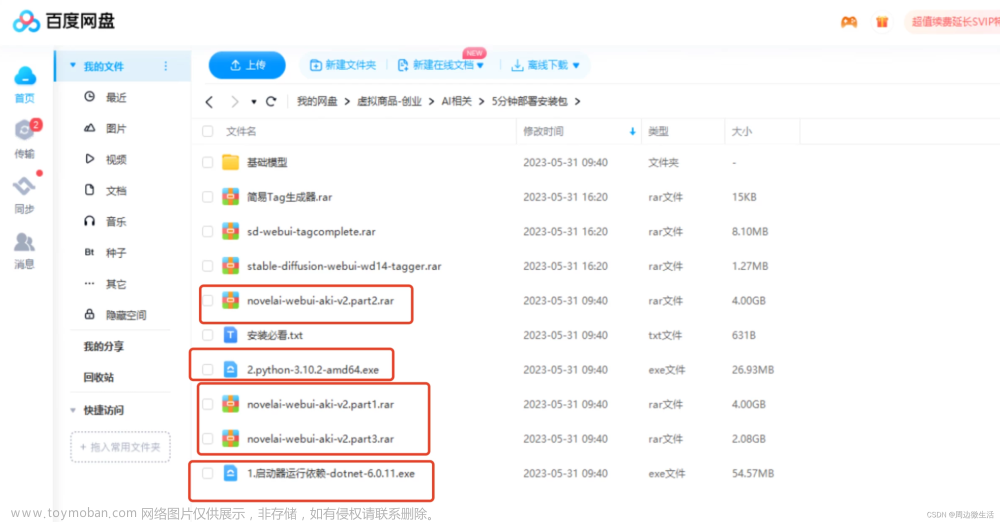
整合包
百度网盘下载地址
秋叶 Stable Diffusion整合包v4.2 教程
从源码安装
- 安装 Python 3.10.6
- 下载 WebUI 源码:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git - 在 webui-user.bat 中修改启动参数
set COMMANDLINE_ARGS= --xformers
- 拷贝相关主模型及微调模型到指定目录。
- 运行
webui-user.bat,会自动创建 Python 虚拟环境、下载安装依赖包,30分钟左右。失败可再次执行。
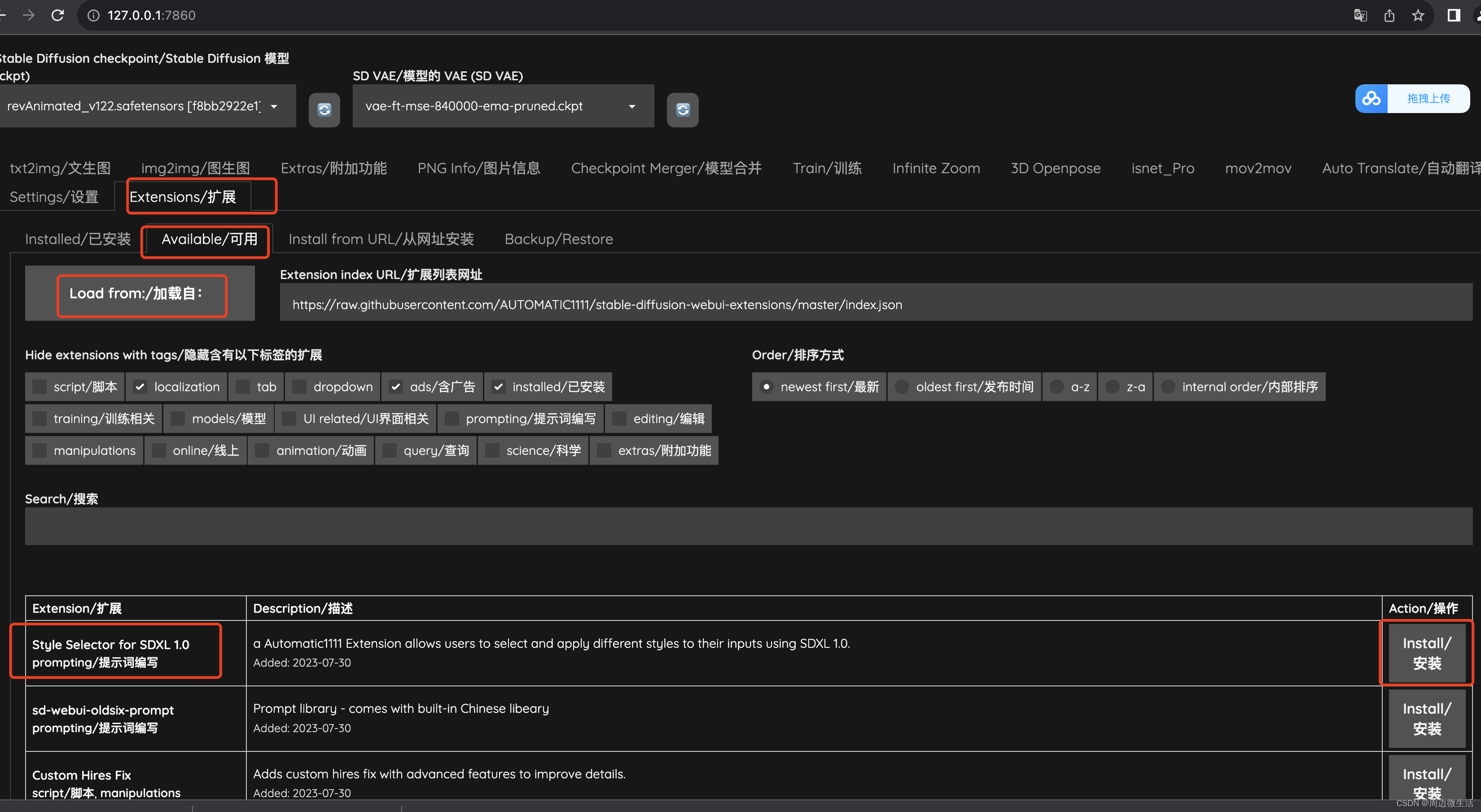
- 点击上图
http://127.0.0.1:8960, 打开后界面如下图,可选择基础模型及设置提示词等参数,点击生成(Generate)按钮:
文生图参数
| 参数 | 说明 |
|---|---|
| Prompt | 提示词(正向) |
| Negative prompt | 消极的提示词(反向) |
| Width & Height | 要生成的图片尺寸。尺寸越大,越耗性能,耗时越久。 |
| CFG scale | AI 对描绘参数(Prompt)的倾向程度。值越小生成的图片越违背你的描绘,但越契合逻辑;值越大则生成的图片越契合你的描绘,但或许不契合逻辑。 |
| Sampling method | 采样方法。有许多种,但仅仅采样算法上有不同,没有好坏之分,选用合适的即可。 |
| Sampling steps | 采样步长。太小的话采样的随机性会很高,太大的话采样的功率会很低,拒绝概率高(能够理解为没有采样到,采样的结果被放弃了)。 |
| Seed | 随机数种子。生成每张图片时的随机种子,这个种子是用来作为确认分散初始状况的基础。不明白的话,用随机的即可。 |
模型
不同的模型会带来不同的画风、认识不同的概念(人物/物体/动作 … …),这是模型众多的原因。常见的模型可以分为两大类:主模型,用于微调主模型的小型模型。常见模型后缀名有如下几种:1. ckpt ,2. pt ,3. pth,4. safetensors,这几种后缀名都是标准的模型,从后缀名是无法判断具体是哪一种类的模型。
由于想要炼制、微调(finetune)主模型十分困难,需要好显卡、算力,所以更多的人选择去炼制小型模型,这些小型模型通过作用在大模型的不同部分,来简单的修改大模型,从而达到定制目的。常见的用于微调的小型模型又分为以下几种:Textual inversion (常说的 Embedding 模型)、Hypernetwork 模型、LoRA 模型。
主模型
主模型对于AI绘画的影响是最大的,SD系列,比如sd-v1-4、sd-v1-5、sd-v2(简写成SD1.5、SD2.0)之类的大模型,这些是 Stable-Diffusion 自带的大模型。基本没有人会用自带的大模型,因为效果很差。如果想自己练大模型的话,SD系列是不错的基础模型,因为他们比较庞杂,什么风格都有,属于中性模型。
目前比较流行和常见的 checkpoint 模型有 Anything 系列、ChilloutMix、Deliberate、国风系列等等。这些 checkpoint 模型是从 Stable Diffusion 基本模型训练而来的。目前,大多数模型都是从 v1.4 或 v1.5 训练的。它们使用其他数据进行训练,以生成特定风格或对象的图像。
模型文件名含 pruned 是指完整版,emaonly 是剪枝版。剪枝版比完整版通常小很多,方便下载。如果只是使用的话,两者差别不大,如果是想要自己练模型的话,需要下载完整版。
- Anything 系列是一个以二次元漫画为主打的模型。
- Cetus-Mix 是一个二次元的混合模型。
- Chilloutmix 是大名鼎鼎的亚洲美女模型,你看到的大量的AI美女,基本上都是这个模型生成的。
- Deliberate 系列,目前最新版本是 deliberate_v2,这个模型是一个万能模型,可以画能任何你想要的东西。风格上偏油画和数绘风格。值得注意的是,这个模型的提示词必须非常详细地填写。
- Realistic Vision 系列是写实风格的模型,比较适合人物和动物,不过相对也比较万金油。
- PerfectWorld 欧美版的 Chilloutmix,主要绘制欧美风格的美女,偏 2.5D 介于动漫和写实之间。
- GuoFeng 是一个中国华丽古风风格模型,也可以说是一个古风游戏角色模型,具有 2.5D 的质感。
LoRA
- 文件后缀: .ckpt、.safetensors、.pt
- 存放路径: models/Lora
当下最火的微调模型,可以将某一类型的人物或者事物的风格固定下来,使用了某种 LORA 那么风格就趋近于它。它们通常为10-200 MB。必须与 checkpoint 模型一起使用。现在比较火的 Korean Doll Likeness、Taiwan Doll Likenes、Cute Girl mix 都是真人美女 LoRA 模型,效果很惊艳。还有一些特定风格的 LoRA 也非常受欢迎,最著名的有墨心等。
模型训练器: https://github.com/Akegarasu/lora-scripts
VAE美化模型/变分自编码器
- 文件后缀: .pt
- 存放路径: models/VAE
VAE,全名Variational autoenconder,中文叫变分自编码器。作用是:滤镜+微调。
有的大模型是会自带 VAE 的,比如 Chilloutmix。如果再加 VAE 则可能画面效果不会更好,甚至适得其反。默认的 VAE 是 animevae,效果一般,建议可以使用 kl-f8-anime2 或者 vae-ft-mse-840000-ema-pruned。anime2 适合画二次元,840000 适合画写实人物。
Embedding/Textual lnversion
- 文件后缀: .safetensors, .pt
- 存放路径: embeddings
Textual lnversion 中文翻译过来叫文本反转,通过仅使用的几张图像,就可以向模型教授新的概念。用于个性化图像生成。Embeddings 是定义新关键字以生成新人物或图片风格的小文件。它们很小,通常为10-100 KB。必须将它们与 checkpoint 模型一起使用。比如 EasyNegative 这个 Embeddings,里面包含了大量的负面词,可以减少你每次打一堆负面词的痛苦。
模型下载
- C站镜像: https://civitai.space/
- https://www.liblibai.com/
- http://www.i-desai.com/
- https://www.ai016.com/
- https://tusi.art
ControlNet
ControlNet 是一个用于控制 AI 图像生成的插件。在 ControlNet 出现之前,我们在生成图片之前,永远的不知道 AI 能给我们生成什么,就像抽卡一样看运气。ControlNet 出现之后,我们就能通过模型精准的控制图像生成,比如进行填色渲染,控制人物的姿态等等。提示词的作用是奠定整个图的大致画面,Lora 的作用是让图片主体符合我们的需求,ControNet 的作用是精细化控制整体图片的元素——主体、背景、风格、形式等。
比如你提供一个图片,可以选择采集图片中人物的骨架,从而在新的图片中生成出一样姿势的人,可以选择采集图片中画面的线稿,从而在新的图片中生成一样线稿的画面 ,可以选择采集图片中已有的风格,从而在新的图片中生成一样风格的画面。
参考:15种ControlNet模型
提示词 Prompt
提示词示例
- 提示词:
solo, 1girl, portrait, looking at viewer, masterpiece, best quality, 8k, - 反向提示词:
(worst quality, low quality:1.4), (bad-image-v2-39000:0.75), (bad_prompt_v2:0.85), (censored, bar censor), cropped, mature,
通用提示词
广泛适用于二次元风格,可以考虑搭配不同模型使用!
- 正面提示词后添加:
(masterpiece:1,2), best quality, masterpiece, highres, original, extremely detailed wallpaper, perfect lighting,(extremely detailed CG:1.2), drawing, paintbrush,
- 负面提示词后添加:
NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
Counterfeit-V2.5 二次元示例
提示词:
(((masterpiece))),(((best quality))), ((ultra-detailed)), (best illustration), 1girl, solo, blush, smug, smile, purple eyes, choker, gradient eyes, no pupils, multicolored_hair, pink hair, blue hair, long hair,<lora:sangonomiyaKokomi_v10:0.5>, sangonomiya kokomi, ((kimono)), outdoors, sakura trees, sakura, facing towards viewer, front view
负面提示词:
EasyNegative,extra fingers, fewer fingers, extreme fingers,wrong hand,wrong tail, missing male, extra legs, extra arms, missing legs, missing arms, weird legs, weird arms, watermark, logo, long hand, (poorly drawn hands:1.331), (bad anatomy:1.21), (bad proportions:1.331), (fused fingers:1.61051), (too many fingers:1.61051), extra digit, fewer digits,(mutated hands and fingers:1.5 ), fused fingers, one hand with more than 5 fingers, one hand with less than 5 fingers, one hand with morethan 5 digit, one hand with less than 5 digit, extra digit, fewer digits, fused digit, missing digit,text,watermark,
参数:文章来源:https://www.toymoban.com/news/detail-543099.html
Size: 512x512, Seed: 1396898128, Model: CounterfeitV25_25, Steps: 20, Sampler: DPM++ 2S a Karras, CFG scale: 7, Model hash: a074b8864e, Hires steps: 20, Hires upscale: 2, Hires upscaler: Latent (nearest-exact), Denoising strength: 0.7
工具
- 解析器: https://spell.novelai.dev/ ,可用于查看模型文件类型,图片文件生成时的参数
- 提示器: https://prompt.qpipi.com/ ,帮助编写提示词
课程
- 咖啡猫CuteCat: https://space.bilibili.com/3493136342977164/channel/collectiondetail?sid=1261907
- Nenly同学: BV1Fu4y1o7F1
- 惫懒の欧阳川: BV1ms4y1y7Mx
- SD题词技巧: BV1Fu4y1o7F1
- 流畅使用GPT: BV13s4y1v7BE
- SD高清放大: BV1Ch4y147WE
- 汉字艺术海报: BV1fh4y1u7x9
秋葉aaaki文章来源地址https://www.toymoban.com/news/detail-543099.html
- 目前训练人物模型无脑选择LoRA:https://www.bilibili.com/video/BV1fs4y1x7p2/
- 训练画风模型推荐训练大模型:https://www.bilibili.com/video/BV1SR4y1y7Lv/
到了这里,关于Stable Diffusion AI 绘画入门指南的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!