欢迎关注公众号 - 【AICV与前沿】,一起学习最新技术吧
欢迎关注公众号 - 【AICV与前沿】,一起学习最新技术吧
欢迎关注公众号 - 【AICV与前沿】,一起学习最新技术吧
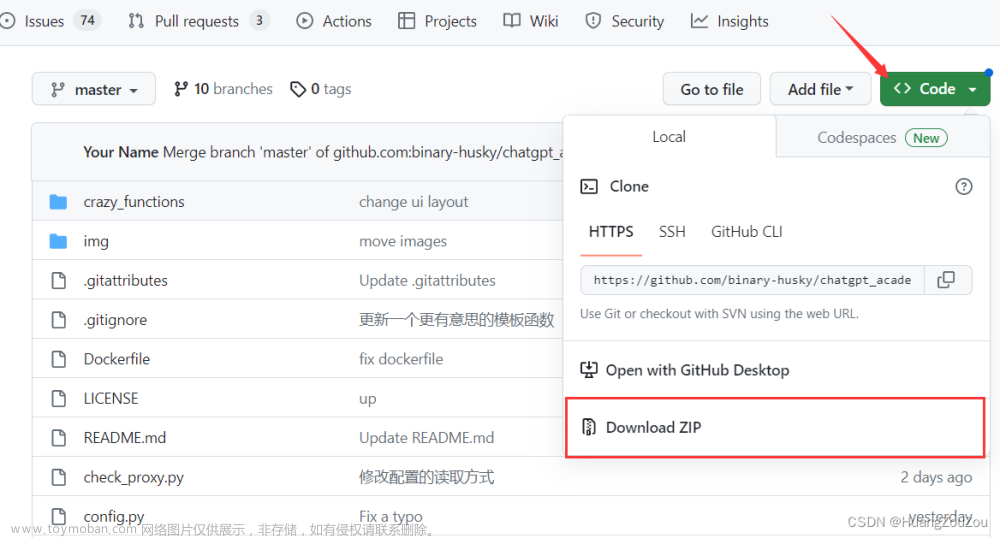
开源地址:https://github.com/ictnlp/BayLing
文章:https://arxiv.org/pdf/2306.10968.pdf
写在前面
大型语言模型(llm)在语言理解和生成方面表现出了非凡的能力。从基础llm到后续llm,指令调整在使llm与人类偏好保持一致方面起着至关重要的作用。
然而,现有的llm通常专注于英语,导致非英语语言的表现较差。为了提高非英语语言的性能,需要为基础llm收集特定语言的训练数据,并构建特定语言的指令进行指令调优,这两者都是繁重的工作。为了最大限度地减少人工工作量,我们建议通过交互式翻译任务将语言生成和指令遵循的能力从英语转移到其他语言。
我们利用LLaMA作为基础LLM,自动构建交互式翻译指令来指导调优,开发了指令跟随LLM BayLing。广泛的评估表明,尽管使用了相当小的参数尺寸,只有130亿,但百灵实现了与gpt -3.5 turbo相当的性能。翻译任务实验结果表明,与GPT-4自动评估相比,BayLing的单轮翻译能力达到95%,与gpt -3.5 turbo人工评估相比,交互式翻译能力达到96%。为了评估一般任务的性能,我们创建了一个多回合指令测试集BayLing-80。在BayLing-80上的实验结果表明,与gpt -3.5 turbo相比,BayLing的性能提高了89%。在中国高考和英语SAT的知识评估中也表现出色,在众多遵循教学的llm中仅次于gpt -3.5 turbo。
相关工作
自然语言处理(NLP)的最新进展导致了强大的大型语言模型的发展,如GPT-3、PaLM、OPT、GLM、BLOOM和LLaMA。在大型语料库上进行预训练使这些基础llm具有非凡的语言理解和生成能力。在此基础上,这些基础llm要发展成为ChatGPT和GPT-4等强大的指令跟随llm,最重要的一步是理解人类指令并与人类偏好保持一致。
ChatGPT是llm领域的一个里程碑,它通过应用指令调优和基于人类反馈的强化学习(RLHF),赋予llm非凡的理解人类指令并与人类偏好保持一致的能力。然而,由于与RLHF阶段相关的大量劳动力成本,研究人员主要通过高质量的指令调谐来努力使llm与人类偏好保持一致,从而在该领域取得了值得注意的进展。
在本研究中,我们关注的是如何将LLM从英语为主的语料库中学习到的语言生成和指令跟随能力转移到其他语言。特别是,我们的目标是找到一种通过指令调优同时转移这些功能的有效方法。为此,我们开发了使用多回合交互式翻译任务的BayLing,以同时提高llm的语言对齐、指令跟随和多回合交互能力。Bayling的出现填补了以往跨语对齐和多回合互动中指令调优研究的空白。

基础模型
LLaMA在广泛的英语任务中表现出了出色的表现,它接受了大约1.4万亿英语主导代币的训练。鉴于LLaMA-7B和LLaMA-13B具有出色的理解能力和生成能力,将它们分别作为BayLing-7B和BayLing-13B的基础模型。
对齐交互式翻译任务
在互动式翻译中,用户与llm进行多轮交流,对译文进行润色,直到满意为止。下图提供了交互式翻译的示例。为了满足用户的需求,LLM首先需要理解用户的意图,然后根据用户的意图生成译文。
由于所涉及的固有挑战和复杂性,交互式翻译的有效执行要求llm在语言对齐,指令跟随和上下文理解方面表现出高水平的熟练程度。此外,由于多回合交互任务始终以人为中心,并鼓励llm的输出满足用户的需求和约束,因此llm与人类偏好的一致性自然得到增强。因此,交互式翻译任务为同时提高llm的语言一致性和指令跟随能力提供了一个理想的机会。此外,llm可以利用其强大的泛化能力,将这些从交互式翻译中学到的熟练程度转移到其他任务中。
为此,我们构建了一个包含160K交互翻译实例的指令数据集,包括词汇、语法、风格、创作等多种交互类型。为了增强BayLing指令数据的多样性,我们在指令数据中补充了相关的公共数据集,包括单圈指令数据的Alpaca和多圈指令数据的ShareGPT。下表给出了百灵使用的教学数据统计。
训练细节
以LLaMA-7B和LLaMA-13B作为基础模型,对BayLing-7B和BayLing-13B在上述提出的指令数据上进行微调。训练配置包括学习率为25 -5和权重衰减为0.0。此外,对BayLing进行了3个epoch的微调,使用批大小为32。最大文本长度限制为1024,并且只计算多回合交互中输出部分的损失。
在训练过程中,使用了DeepSpeed和Gradient checkpoint技术来优化内存消耗。在推理过程中,BayLing-13B可以通过8位量化部署在16G内存的GPU上。
测评媲美GPT3.5
为了进行人工评价,首先选择了60个句子,其中包括30个汉语句子和30个英语句子作为源句子进行翻译。然后,邀请了5位英语专业的注释者,与BayLing-13B、BayLing-7B、ChatGPT17、vicana - 13b和ChatGLM-6B这5个系统进行了4次交互,对这60个翻译句子进行了4次交互。系统标识是隐藏的,并且是随机排列的,以确保注释者不知道他们正在与之交互的系统。在互动过程中,要求注释者一半用中文,另一半用英语,以保证教学语言的多样性。此外,我们在60个案例中设计了五个不同的互动类别:词汇,语法,风格,建议和创作(即每个类别由12个案例组成),当面对不同类型的需求时,能够分析系统的性能。
测评发现百聆的交互翻译能力与其他开源大模型相比具有明显优势,13B 参数量的百聆在这一任务上的性能甚至能与 175B 参数量的 ChatGPT 相媲美。
从翻译能力、指令跟随能力和多回合交互能力三个方面分别给出了人的评价。
(a)翻译:评估llm的整体翻译水平。
(b)指令遵循:评估llm能否成功完成指令并满足人类要求的程度。
©多回合互动:衡量llm在多回合对话中理解和保持连贯性的能力,测试他们对语境的理解和一致性。文章来源:https://www.toymoban.com/news/detail-543286.html
对于每个案例,要求注释者同时评估五个系统的交互过程,并从翻译质量、指令遵循和多回合交互性能三个方面(每个方面1分)给出1到10分的分数。此外,要求注释者从这三个方面分别给出5个系统的1到5级。最后将五个注释者的分数和排名取平均值,作为五个系统的最终分数和排名。 文章来源地址https://www.toymoban.com/news/detail-543286.html
文章来源地址https://www.toymoban.com/news/detail-543286.html
到了这里,关于中科院开源多语言大模型Bayling【百聆】:性能媲美GPT-3.5的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!