1.lightgbm
简单介绍一下ightgbm
首先需要说一说GBDT,它是一种基于决策树的集成算法,它使用的集成方法是boosting,其主要思想是通过多次迭代,每次迭代都学习一棵CART树来拟合之前 t-1 棵树的预测结果与训练样本真实值的残差,最终得到一个准确度更高的模型。
全称为Gradient Boosting Decision Tree。它是一种基于决策树的集成算法,可以用于回归和分类任务。其主要思想是通过多次迭代,每次迭代都根据当前模型预测与真实值之间的差异来调整模型,最终得到一个准确度更高的模型。
其中,GBDT中使用的树算法是CART(Classification And Regression Tree)回归树。CART回归树主要用于解决连续值的预测问题,也是GBDT算法中最基础的建模方法。
ightgbm对GBDT进行了一系列优化,比如通过使用直方图来加速结点分裂、支持并行和默认缺失值处理等,在可扩展性和训练速度上有了巨大的提升,但其核心思想与gbdt相比没有大的变化。
cart回归树使用什么指标确定最佳分裂节点?
cart回归树通常使用平方误差和作为分裂节点的评价指标。具体来说,算法会计算每个可能的分裂点(根据特征值的不同阈值划分数据),并计算每个分裂点上两个子集的平方误差和。然后,选择具有最小平方误差和的分裂点作为最佳分裂节点。
lightgbm对GBDT的改进
GBDT的训练受到样本数量和特征数量的双重影响,lightgbm从这两个方面入手对GBDT进行了改进。
1、在样本数量方面,lightgbm根据样本梯度信息进行采样,保留那些梯度较大的样本,对梯度较小的样本进行采样,同时为采样样本添加一个权重值,从而降低采样对数据分布的影响。
2、在特征数量方面,lightgbm将多个特征值进行融合得到一个特征
3、其他的改进还有,lightgbm进行分裂时采取的是leaf-wise策略,每次选择使得增益最大的叶子结点进行分裂。但这种分裂方式在数据量较少的时候容易过拟合,所以需要限制树的深度来防止过拟合。
4、lightgbm通过使用直方图来加速结点分裂,将连续特征进行离散化,这样在寻找分割点的时候能够大大降低计算复杂度。由于lightgbm的基模型实际上是个二叉树,父结点的直方图实际等于左右两个子结点直方图的累积,所以当已知父结点的直方图时,只需要统计样本数量较少的子结点的直方图,数量较多的子结点的直方图可以通过做差得到。
5、lightgbm的并行方式有特征并行、数据并行、投票并行。但三种并行方式并不是同时存在的,根据数据集和特征的不同可以选择何是的并行方式。
介绍lightgbm中的直方图算法
LightGBM中的直方图算法是一种高效的寻找最优分裂点的算法,其主要对连续特征进行离散化,将连续的特征值分成了若干个直方桶(bin),以桶的统计信息代替原始特征值,减少了数据量的同时也可以使得分裂点的寻找更加高效。
举例来说,如果我们有一个连续的特征值,它的取值范围是[1,10],我们可以将这个范围分成5个直方桶,每个桶的取值范围是[1, 3], [4, 5], [6, 7], [8, 9], [10, 10]。然后我们可以根据每个桶的统计信息,如该桶内样本的数量、平均数、方差等等,来代替原始特征值,从而进行决策树的构建。
在使用直方图算法时,最佳的分裂点是通过遍历每个直方桶来确定的。
例如,我们有一个含有4个bin的特征,当我们进行决策树节点的分裂时,我们可以先计算出每个bin的统计信息(如均值)。然后,我们可以尝试在4个桶的统计信息上确定最优的分割点,得到4种分割方案。最后,从这4个方案中选择最优的分裂点方案,作为该节点的分裂点。
总的来说,LightGBM中的直方图算法可以帮助我们更加高效地寻找最佳分裂点,从而构建出更加精准的决策树模型。
CART回归树和CART分类树的区别
CART回归树和CART分类树的区别
2.word2vec
解释word2vec原理
Word2Vec是一种基于神经网络的词向量表示模型,通过将词语映射为向量,在向量空间中捕捉词语的语义信息。
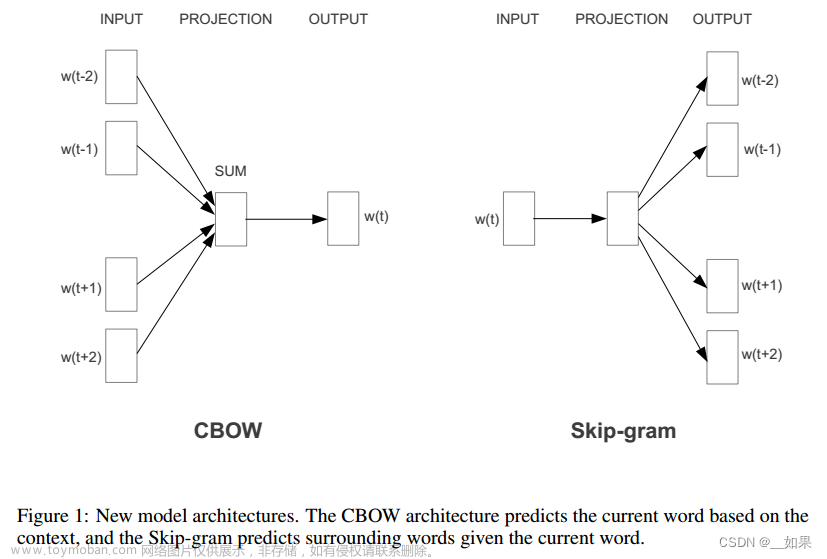
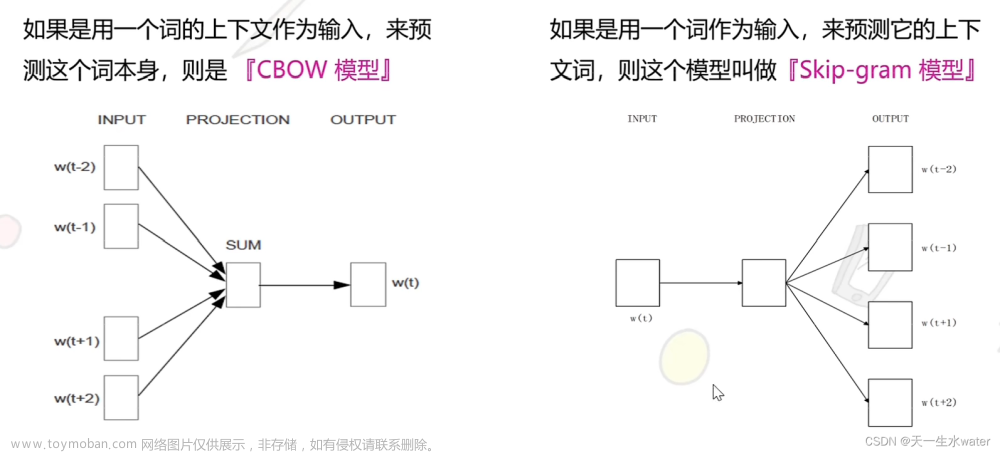
Word2Vec模型有两种常见的架构:CBOW(Continuous Bag-of-Words)和Skip-gram。CBOW模型根据上下文词语来预测当前词语,而Skip-gram模型则根据当前词语来预测上下文词语。这两种模型都通过训练神经网络,学习得到了每个词语的稠密向量表示。文章来源:https://www.toymoban.com/news/detail-544302.html
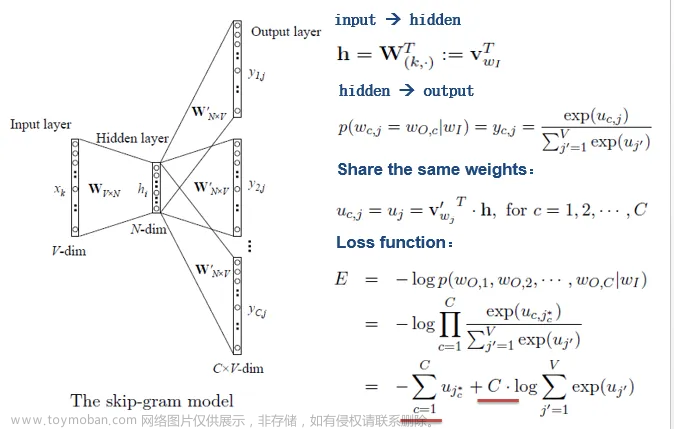
Word2Vec中skip-gram是什么,Negative Sampling怎么做
Word2Vec通过学习文本然后用词向量的方式表示词的语义信息,然后使得语义相似的单词在嵌入式空间中的距离很近。而word2vec是借用神经网络的方式实现的。在Word2Vec模型中有Skip-Gram和CBOW两种模式,Skip-gram模型是用一个词语作为输入,来预测它周围的上下文,CBOW模型是拿一个词语的上下文作为输入,来预测这个词语本身。。Negative Sampling是对于给定的词,并生成其负采样词集合的一种策略,已知有一个词,这个词可以看做一个正例,而它的上下文词集可以看做是负例,但是负例的样本太多,而在语料库中,各个词出现的频率是不一样的,所以在采样时可以要求高频词选中的概率较大,低频词选中的概率较小,这样就转化为一个带权采样问题,大幅度提高了模型的性能。文章来源地址https://www.toymoban.com/news/detail-544302.html
3.CNN
4.LSTM
5.textCNN
6.BERT
7.transformer
8.随机森林
9.lr
到了这里,关于机器学习算法原理lightgbm、word2vec、cnn、lstm、textcnn、bert、transformer、随机森林、lr的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!