背景:我们在kafka经常会听到分区(partition)和消费者,消费者组,那么到底有什么关系呢,下面我们抛开kafka的其他问题,单纯的聊一聊这二者的关系,方便大家理解
一.kafka为什么要分区?
分区可以将topic的消息打散到多个分区分布式的保存在不同的broker上,实现了producer和consumer消息处理的高吞吐量。Kafka的producer和consumer都可以多线程地并行操作,而每个线程处理的是一个分区的数据。因此分区实际上是调优Kafka并行度的最小单元。对于producer而言,它实际上是用多个线程并发地向不同分区所在的broker发起Socket连接同时给这些分区发送消息;而consumer,同一个消费组内的所有consumer线程都被指定topic的某一个分区进行消费。
一句话总结:分区是消息分布式存储,方便并行操作,提高吞吐量
二.分区怎么分,分了之后怎么处理?
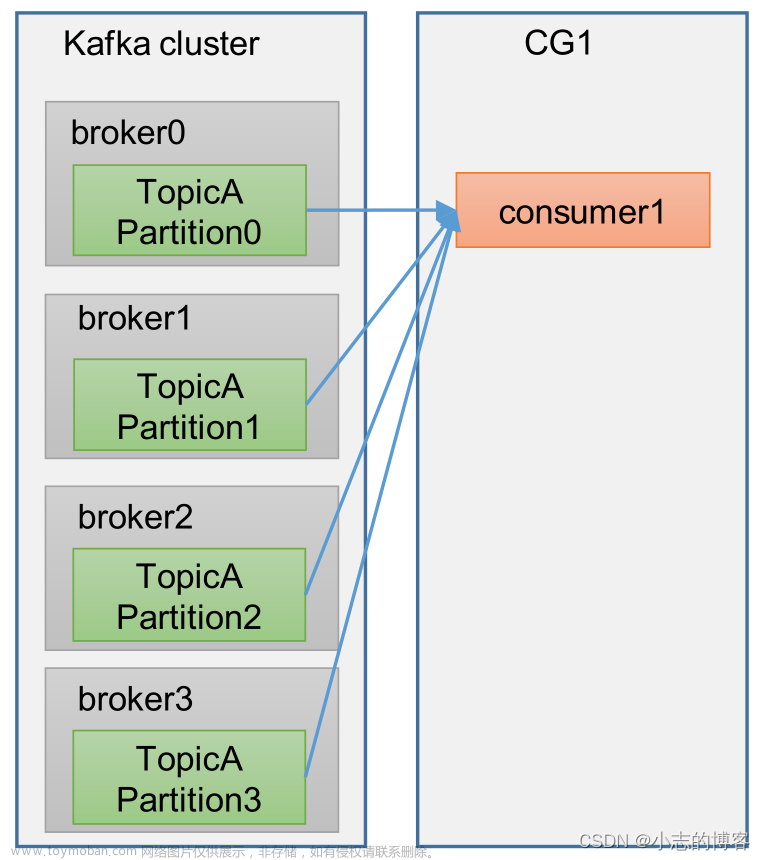
假设主题T1有四个分区
一个消费者组
1.1消费者数量小于分区数量
只有一个消费者时,消费者1将收到4个分区的全部消息,容易造成消费者1扛不住崩溃
当有两个消费者时,每个消费者将分别从两个分区接受消息。
1.2 消费者数量等于分区数量
当有四个消费者时,每个消费者都可以接受一个分区的消息
1.3 消费者数量大于分区数量
当有五个消费者时,会有闲置的消费者
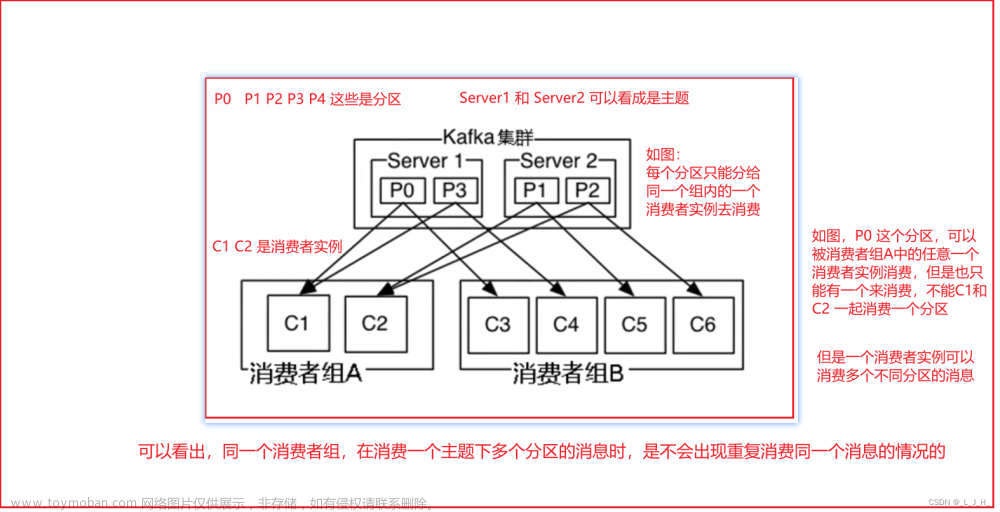
两个消费者组
消费者群组之间是互不影响的,如图 文章来源:https://www.toymoban.com/news/detail-545705.html
文章来源:https://www.toymoban.com/news/detail-545705.html
三.分区Rebalance(再均衡)
- 有新的消费者加入消费者群组
- 已有的消费者退出消费者群组
- 订阅的主题的分区发生变化
以上三种情况都会触发分区的重新分配,重新分配的过程叫Rebalance(再均衡)。
Rebalance给消费者群组带来了高可用性与伸缩性,但是在Rebalance期间,消费者无法读取消息,整个群组一小段时间不可用,而且当分区被重新分配给另一个消费者时,消费者当前的读取状态会丢失。文章来源地址https://www.toymoban.com/news/detail-545705.html
到了这里,关于Kafka-partition和消费者的关系的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!