一、简介
1. 定义
Elasticsearch7.x是一个基于Lucene的分布式搜索引擎具有以下特点:
- 高性能:能够处理海量数据并实现实时搜索。其内置了负载均衡和容错机制,提供了高可用性和伸缩性。
- 灵活性:支持文本全文检索、结构化搜索、地理位置搜索等多种搜索方式,同时支持自定义插件扩展。
- 易用性:使用简单的RESTful API进行交互,支持HTTP/JSON等多种格式传输数据。
- 开源性:采用Apache许可证2.0发布,没有任何商业限制。
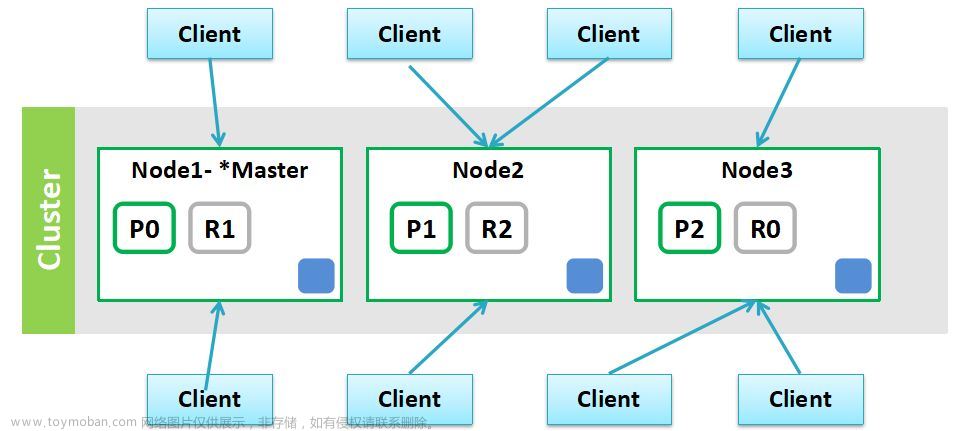
2. 集群架构
集群架构监测、调试、优化对于保障系统的稳定性和高可用性非常重要。在Elasticsearch集群中常见的应用场景包括:
- 监控集群各节点的状态、健康状况和运行指标,诊断和修复故障。
- 针对系统瓶颈进行性能优化,提升搜索、索引等操作的效率。
- 利用分布式计算和集群横向扩展的优势,垂直或水平扩展Elasticsearch集群以达到更高的性能要求。
以下是一个Java程序示例,实现了使用Elasticsearch Java API获取一个集群的健康状况:
import org.elasticsearch.client.Cancellable;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.core.MainResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import org.elasticsearch.cluster.health.ClusterHealthStatus;
import org.elasticsearch.cluster.health.ClusterIndexHealth;
import org.elasticsearch.cluster.health.ClusterHealthResponse;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.rest.RestStatus;
import java.io.IOException;
public class ElasticsearchClusterHealth {
public static void main(String[] args) throws IOException {
RestHighLevelClient client = new RestHighLevelClient();
ClusterHealthResponse response = client.cluster().health(RequestOptions.DEFAULT);
String clusterName = response.getClusterName();
int numberOfNodes = response.getNumberOfNodes();
int numberOfDataNodes = response.getNumberOfDataNodes();
for (ClusterIndexHealth health : response.getIndices().values()) {
String indexName = health.getIndex();
int numberOfShards = health.getNumberOfShards();
int numberOfReplicas = health.getNumberOfReplicas();
ClusterHealthStatus status = health.getStatus();
int activeShards = health.getActiveShards();
int unassignedShards = health.getUnassignedShards();
System.out.println("Cluster: " + clusterName);
System.out.println("Number of Nodes: " + numberOfNodes);
System.out.println("Number of Data Nodes: " + numberOfDataNodes);
System.out.println("Index " + indexName + ":");
System.out.println("- Number of Shards: " + numberOfShards);
System.out.println("- Number of Replicas: " + numberOfReplicas);
System.out.println("- Status: " + status);
System.out.println("- Active Shards: " + activeShards);
System.out.println("- Unassigned Shards: " + unassignedShards);
}
}
}
示例说明:
- 通过
org.elasticsearch.client.RestHighLevelClient类获得ES集群中的健康状况。 -
RestHighLevelClient类是Elasticsearch Java API中访问集群的高级客户端,支持发送各种类型的操作请求,例如索引、搜索或管理应用程序集群的设置。 -
Response对象包含了集群的状态信息。在该示例中使用了ClusterHealthResponse获取整个集群的健康状况信息。 - 通过
ClusterHealthResponse中的方法获取集群名称、节点数、数据节点数等信息,并通过遍历获取每个索引的相关健康信息。
二、 集群架构监测
1. 概念和意义
集群架构监测是指在 Elasticsearch 集群运行过程中,通过收集各种数据指标、统计信息等对集群进行监测和分析。这样可以及时发现问题及时做出调整,以保证 Elasticsearch 集群的正常运行。集群架构监测具有预防故障、提高集群可用性的重要意义。
2. 集群架构的基本指标
Elasticsearch7.x 集群架构的基本指标包括以下几个方面:
- 节点状态(Node Status):节点的状态分为 Green、Yellow、Red 三种,其中 Green 表示集群运行正常;Yellow 表示存在部分不可用的副本分片或数据丢失;Red 表示集群的主分片不可用,需要尽快恢复。
- 分片数量(Shard Count):每个索引分成的分片数目,如果数量太小,可能会导致数据无法均衡分布;如果数量太大,可能会导致硬件成本增加,查询效率下降。
- 分片大小(Shard Size):每个分片的大小,如果过大可能会导致网络传输瓶颈;如果过小则会增加 CPU 和 I/O 等资源消耗。
- 索引数量(Index Count):集群中索引的数量。索引数量过多会影响查询效率和硬件成本。
- 文档数量(Document Count):集群中文档的数量。如果文档数量过多,可能会导致查询效率下降。
- 内存使用率(Memory Usage):集群中节点的内存使用情况。过高的内存使用率可能会导致节点出现缓慢或崩溃等问题。
- CPU 使用率(CPU Usage):集群中节点的 CPU 使用情况。过高的 CPU 使用率可能会导致节点出现缓慢或崩溃等问题。
- 磁盘使用率(Disk Usage): 集群中节点的磁盘使用情况。过高的磁盘使用率可能导致磁盘空间不足,从而影响数据的写入和查询。
可以通过以下方式进行监测:
- 节点状态:通过 Elasticsearch API 或 Kibana 的 Cluster Health Dashboard 进行监测;
- 分片数量、分片大小、索引数量、文档数量等基本指标:可以通过 Elasticsearch API 或 Kibana Metrics Dashboard 进行监测;
- 内存使用率、CPU 使用率、磁盘使用率等系统指标:可以通过 Elasticsearch Exporter、Metricbeat 和 Kibana Metrics Dashboard 进行监测。
3. 使用 Elastic Stack 进行集群监测
Elastic Stack 提供了一套完整的数据采集、存储、分析和可视化的解决方案,可以帮助运维人员更加有效地监测 Elasticsearch7.x 集群的架构情况。
具体步骤如下:
- 采集数据:使用 Beats 系列工具(如 Metricbeat)从 Elasticsearch 集群中采集数据,将采集的数据发送到 Elasticsearch 或 Logstash 中。
- 存储数据:使用 Elasticsearch 进行数据存储。
- 分析数据:使用 Kibana 对采集的数据进行分析,展现数据的状态、趋势或异常情况。
- 可视化数据:将采集的数据在 Kibana 中进行可视化展示,包括图表、仪表盘、报表等形式,帮助运维人员更加直观地了解 Elasticsearch 集群的架构情况。
代码示例:
// 1. 采集数据:使用 Metricbeat 从 Elasticsearch 集群中采集数据,
// 将采集的数据发送到 Elasticsearch 或 Logstash 中。
URL elasticSearchUrl = new URL("http://localhost:9200");
MetricbeatConfig config = new MetricbeatConfig.Builder()
.setHost(elasticSearchUrl.getHost())
.setPort(elasticSearchUrl.getPort())
.setScheme(elasticSearchUrl.getProtocol())
.build();
Metricbeat metricbeat = new Metricbeat(config);
// 2. 存储数据:使用 Elasticsearch 进行数据存储。
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost(elasticSearchUrl.getHost(), elasticSearchUrl.getPort(), elasticSearchUrl.getProtocol())
)
);
// 3. 分析数据:使用 Kibana 对采集的数据进行分析,展现数据的状态、趋势或异常情况。
// 这里可以通过 Kibana 的 Watcher、Alerting 等功能进行告警设置和机器学习分析。
// 4. 可视化数据:将采集的数据在 Kibana 中进行可视化展示。
// 在 Kibana 中创建仪表盘、图表等可视化工具,来展现 Elasticsearch 集群的架构情况。
三、 集群架构调试
1.概念和意义
在 Elasticsearch 集群中可能会发生一些故障和问题,比如节点异常、数据分片失效等。因此对于 Elasticsearch 集群架构的调试非常重要。通过集群架构调试,可以快速定位问题,解决故障,保证集群的稳定性和可靠性。
2. 常见故障及其排查方法
2.1 节点异常
节点异常是指 Elasticsearch 集群中的某个节点异常退出或者无法启动。这种情况下可以通过以下步骤进行排查:
- 检查 Elasticsearch 日志,查看具体错误信息。
- 检查系统日志,查看资源是否足够。
- 检查磁盘空间,是否已满或不足。
- 检查网络连接,是否通畅。
- 检查 Elasticsearch 配置,是否有错误或者不一致的地方。
2.2 数据分片失效
数据分片失效通常是由于某些原因导致 Elasticsearch 集群中的某个分片无法正常工作或者已经丢失。这种情况下可以通过以下步骤进行排查:
- 执行
GET /_cat/shards命令获取分片信息,查看是否有分片处于未分配状态。 - 执行
GET /_cat/nodes命令获取节点信息,查看包含分片的节点是否可用。 - 执行
GET /_cluster/health命令查看集群健康状态,如果状态为黄色或红色,说明集群存在一些问题。 - 检查 Elasticsearch 配置,是否有错误或者不一致的地方。
- 如果分片丢失,可以尝试重新复制分片,或者直接删除分片并重建。
3. 使用 Elasticsearch 内置API 进行调试
Elasticsearch 提供了丰富的 API可以用于对集群进行调试和监控。以下是常用的一些 API:
-
GET /_cat:查看集群中的节点、分片等信息。 -
GET /_cat/shards:查看集群中每个索引的分片情况。 -
GET /_cat/nodes:查看节点的详细信息。 -
GET /_cluster/health:查看集群的健康状态。
这些 API 可以通过浏览器、curl 或者编程语言等方式进行访问和调用,如果发现集群存在问题,可以通过这些 API 进行及时排查和修复。
代码示例 访问 Elasticsearch API 的示例:
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
public class ElasticsearchTest {
public static void main(String[] args) throws Exception {
// 建立连接
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
// 查询集群节点信息
NodesStatsRequest nodesStatsRequest = new NodesStatsRequest();
NodesStatsResponse nodesStatsResponse = client.nodes().stats(nodesStatsRequest, RequestOptions.DEFAULT);
List<NodeStats> nodeStatsList = nodesStatsResponse.getNodes();
// 遍历节点信息并打印
for (NodeStats nodeStats : nodeStatsList) {
System.out.println(nodeStats.getNode().getName());
System.out.println(nodeStats.getIndices().getStore());
}
// 关闭连接
client.close();
}
}
上述代码通过 Java High Level REST Client 访问 Elasticsearch API,查询集群中所有节点的存储情况。通过类似的方式可以轻松地使用编程语言对 Elasticsearch 集群进行调试。
四、集群架构优化
1.概念和意义
Elasticsearch是一种分布式搜索和分析引擎,它的集群架构对于整个系统的性能和稳定性有非常重要的影响。集群架构优化可以提高系统的吞吐量、减少延迟、增加稳定性和可靠性,从而满足业务和用户的需求。
2.优化方案及实现方法
1. 节点配置优化
1.1 内存设置
将ES节点的JVM内存设置为建议值的一半,剩余一半留给操作系统使用。
# ElasticSearch JVM内存设置
-Xms4g
-Xmx4g
1.2 硬盘存储
使用SSD硬盘存储数据,同时保证服务器机器的数据写入带宽大于等于SSD的写入速度,以避免瓶颈。
1.3 CPU数量
建议每个节点努力保持12个CPU线程以获得最佳性能。
2. 索引设计优化
2.1 Shard数量设置
每个索引的Shard数量不应该超过30个。如果超过30个会对集群性能产生负面影响。
2.2 索引分片副本设置
建议为每个索引至少分配1个副本。每个节点最好不要超过3个副本,以避免资源浪费。
3. 集群安全优化
3.1 防火墙设置
在ES集群中的所有节点上设置防火墙,限制ES的监听端口对于外网的访问,保证ES集群的安全性。
3.2 X-Pack 安全功能
使用X-Pack 安全功能来加强数据传输和访问的安全性,例如:SSL/TLS加密、权限控制等。
3. 如何使用 Elastic Stack 进行集群架构优化
Elastic Stack是一个完整的数据收集、存储和分析的解决方案,可以帮助用户优化ES集群架构。
具体的操作方法包括:
- 在Kibana中查看和监控ES集群的运行状态和性能指标。
- 使用Beats数据采集器向ES集群中收集服务器日志数据。
- 使用Logstash处理和转换数据,并将其发送到ES集群进行存储和分析。
- 使用Apm服务生成应用程序性能指标,并将其与其他指标一起在Kibana中进行展示和分析。
以上就是使用Elasticsearch7.x集群架构优化的建议方案和实现方法,通过适当的硬件升级、索引设计和集群安全优化等措施可以在保证ES集群稳定性的同时提升性能。文章来源:https://www.toymoban.com/news/detail-549424.html
五、案例分析
1. Elasticsearch的集群架构监测、调试、优化案例简介
本案例研究基于Elasticsearch7.x的集群架构进行监测、调试和优化。该案例主要针对在高并发情况下,Elasticsearch搜索引擎在性能方面遇到的问题。文章来源地址https://www.toymoban.com/news/detail-549424.html
2. 案例分析中方法
监测方法
- 监控JVM内存使用情况,检查是否出现内存泄漏
- 监控网络流量
- 监控CPU负载
- 监控文件系统空间
调试方法
- 使用slowlog分析工具进行查询性能优化
- 使用profiling工具进行代码性能优化
- 尝试缩减shard数量,提高索引性能
- 合理设置索引路由,减少单个节点的负载
优化方法
- 提高后台服务的QPS来减少查询请求的等待时间
- 使用索引的segment merge功能来提高查询性能
- 进行负载均衡操作,减少节点之间的压力差异
- 使用Elasticsearch的插件和模块来进行系统性能优化
到了这里,关于Elasticsearch 集群架构监测 调试 优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![四、初探[ElasticSearch]集群架构原理与搜索技术](https://imgs.yssmx.com/Uploads/2024/02/484387-1.png)