前言
Pod 是 Kubernetes 集群中能够被创建和管理的最小部署单元。所以需要有工具去操作和管理它们的生命周期,这里就需要用到控制器了。
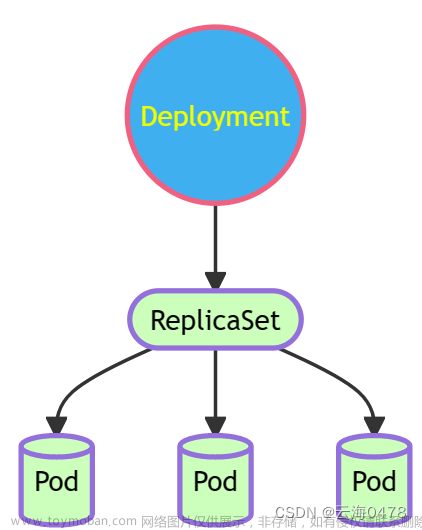
Pod 控制器由 master 的 kube-controller-manager 组件提供,常见的此类控制器有 Replication Controller、ReplicaSet、Deployment、DaemonSet、StatefulSet、Job 和 CronJob 等,它们分别以不同的方式管理 Pod 资源对象。
1.pod控制器的相关知识
1.1 pod控制器的作用
Pod控制器,又称之为工作负载(workload),是用于实现管理pod的中间层,确保pod资源符合预期的状态,pod的资源出现故障时,会尝试进行重启,当根据重启策略无效,则会重新新建pod的资源。
按照pod的创建安方式可以将其分为两类:
自主式pod:kubernetes直接创建出来的pod,这种pod删除后就没有了,也不会重建
控制器创建的pod:通过控制器创建的pod,这种pod删除了之后还会自动重建
控制器和pod的关系:
controllers:在集群上管理和运行容器的 pod 对象, pod 通过 label-selector 相关联。
Pod 通过控制器实现应用的运维,如伸缩,升级等。

1.2 pod控制器的多种类型
1)ReplicaSet: 代用户创建指定数量的pod副本,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能。
ReplicaSet主要三个组件组成:
1)用户期望的pod副本数量
2)标签选择器,判断哪个pod归自己管理
3)当现存的pod数量不足,会根据pod资源模板进行新建
帮助用户管理无状态的pod资源,精确反应用户定义的目标数量,但是RelicaSet不是直接使用的控制器,而是使用Deployment。
(2)Deployment:工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器。支持滚动更新和回滚功能,还提供声明式配置。
ReplicaSet 与Deployment 这两个资源对象逐步替换之前RC的作用。
(3)DaemonSet:用于确保集群中的每一个节点只运行特定的pod副本,通常用于实现系统级后台任务。比如ELK服务
特性:服务是无状态的
服务必须是守护进程
(4)StatefulSet:管理有状态应用
(5)Job:只要完成就立即退出,不需要重启或重建
(6)Cronjob:周期性任务控制,不需要持续后台运行
1.3 pod容器中的有状态和无状态的对比
(1)有状态实例
实例之间有差别,每个实例都有自己的独特性,元数据不同,例如etcd,zookeeper
实例之间不对等的关系,以及依靠外部存储的应用
(2)无状态实例
deployment认为所有的pod都是一样的
不用考虑顺序的要求
不用考虑在哪个node节点上运行
可以随意扩容和缩容
2.1Deployment控制器
部署无状态应用
管理Pod和ReplicaSet
具有上线部署、副本设定、滚动升级、回滚等功能
提供声明式更新,例如只更新一个新的image
应用场景:web服务
vim nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.15.4
ports:
- containerPort: 80kubectl create -f nginx-deployment.yaml
kubectl get pods,deploy,rs
2.2 SatefulSet 控制器的运用
StatefulSet 是用来管理有状态应用的工作负载 API 对象。
StatefulSet 用来管理某 Pod 集合的部署和扩缩, 并为这些 Pod 提供持久存储和持久标识符。
和 Deployment 类似, StatefulSet 管理基于相同容器规约的一组 Pod。但和 Deployment 不同的是, StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
如果希望使用存储卷为工作负载提供持久存储,可以使用 StatefulSet 作为解决方案的一部分。 尽管 StatefulSet 中的单个 Pod 仍可能出现故障, 但持久的 Pod 标识符使得将现有卷与替换已失败 Pod 的新 Pod 相匹配变得更加容易。
StatefulSet 对于需要满足以下一个或多个需求的应用程序很有价值:
稳定的、唯一的网络标识符。
稳定的、持久的存储。
有序的、优雅的部署和扩缩。
有序的、自动的滚动更新。
在上面描述中,“稳定的”意味着 Pod 调度或重调度的整个过程是有持久性的。 如果应用程序不需要任何稳定的标识符或有序的部署、删除或扩缩, 则应该使用由一组无状态的副本控制器提供的工作负载来部署应用程序,比如 Deployment 或者 ReplicaSet可能更适用于你的无状态应用部署需要。
2.2 SatefulSet 控制器
1 名为 nginx-svc 的 Headless Service 用来控制网络域名。
2 名为 nginx-sts 的 StatefulSet 有一个 Spec,它表明将在独立的 3 个 Pod 副本中启动 nginx 容器。
3 volumeClaimTemplates 将通过 PersistentVolume 制备程序所准备的 PersistentVolumes来提供稳定的存储
案例的创建演示
apiVersion: v1
kind: Service
metadata:
name: nginx-svc 服务名
spec:
ports:
- port: 80
targetPort: 80
clusterIP: None 无头服务的clusterIp为None
selector:
app: nginx-sts 拥有此标签的pod 都有此service
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-sts
spec:
replicas: 3
serviceName: "nginx-svc" #声明它属于哪个Headless Service.
selector:
matchLabels:
app: nginx-sts 和下面的标签必须对应
template: 定义pod模板
metadata:
labels:
app: nginx-sts 和上面的标签必须对应
spec:
containers:
- image: nginx:1.14
imagePullPolicy: IfNotPresent
name: nginx-test
ports:
- containerPort: 80
protocol: TCP
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates: #可看作pvc的模板 ---创建pod时,自动创建pvc,请求pv
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs-client-storageclass" #存储类名,改为集群中已存在的
resources:
requests:
storage: 2Gi



案例的更行扩容与缩容演示
kubectl edit sts (sts代表SatefulSet ) 只要时statefulset控制器创建的pod都会显示出来


kubectl get svc #查看创建的无头服务myapp-svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 50d
myapp-svc ClusterIP None <none> 80/TCP 38s
kubectl get sts #查看statefulset
NAME DESIRED CURRENT AGE
myapp 3 3 55s
kubectl get pvc #查看pvc绑定
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
myappdata-myapp-0 Bound pv002 2Gi RWO 1m
myappdata-myapp-1 Bound pv003 2Gi RWO,RWX 1m
myappdata-myapp-2 Bound pv004 2Gi RWO,RWX 1m
kubectl get pv #查看pv绑定
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv001 1Gi RWO,RWX Retain Available 6m
pv002 2Gi RWO Retain Bound default/myappdata-myapp-0 6m
pv003 2Gi RWO,RWX Retain Bound default/myappdata-myapp-1 6m
pv004 2Gi RWO,RWX Retain Bound default/myappdata-myapp-2 6m
pv005 2Gi RWO,RWX Retain Available 6m
//当删除一个 StatefulSet 时,该 StatefulSet 不提供任何终止 Pod 的保证。为了实现 StatefulSet 中的 Pod 可以有序且体面地终止,可以在删除之前将 StatefulSet 缩容到 0。
kubectl scale statefulset myappdata-myapp --replicas=0
kubectl delete -f stateful-demo.yaml
//此时PVC依旧存在的,再重新创建pod时,依旧会重新去绑定原来的pvc
kubectl apply -f stateful-demo.yaml
//总结
无状态:
1)deployment 认为所有的pod都是一样的
2)不用考虑顺序的要求
3)不用考虑在哪个node节点上运行
4)可以随意扩容和缩容
有状态
1)实例之间有差别,每个实例都有自己的独特性,元数据不同,例如etcd,zookeeper
2)实例之间不对等的关系,以及依靠外部存储的应用。
常规service和无头服务区别
service:一组Pod访问策略,提供cluster-IP群集之间通讯,还提供负载均衡和服务发现。
Headless service:无头服务,不需要cluster-IP,而是直接以DNS记录的方式解析出被代理Pod的IP地址。
(1) 为什么要有headless?
在deployment中,每一个pod是没有名称,是随机字符串,是无序的。而statefulset中是要求有序的,每一个pod的名称必须是固定的。当节点挂了,重建之后的标识符是不变的,每一个节点的节点名称是不能改变的。pod名称是作为pod识别的唯一标识符,必须保证其标识符的稳定并且唯一。
为了实现标识符的稳定,这时候就需要一个headless service 解析直达到pod,还需要给pod配置一个唯一的名称。
(2)为什么要有volumeClaimTemplate?
大部分有状态副本集都会用到持久存储,比如分布式系统来说,由于数据是不一样的,每个节点都需要自己专用的存储节点。而在 deployment中pod模板中创建的存储卷是一个共享的存储卷,多个pod使用同一个存储卷,而statefulset定义中的每一个pod都不能使用同一个存储卷,由此基于pod模板创建pod是不适应的,这就需要引入volumeClaimTemplate,当在使用statefulset创建pod时,会自动生成一个PVC,从而请求绑定一个PV,从而有自己专用的存储卷。
服务发现:就是应用服务之间相互定位的过程。
应用场景:
●动态性强:Pod会飘到别的node节点
●更新发布频繁:互联网思维小步快跑,先实现再优化,老板永远是先上线再慢慢优化,先把idea变成产品挣到钱然后再慢慢一点一点优化
●支持自动伸缩:一来大促,肯定是要扩容多个副本
K8S里服务发现的方式---DNS,使K8S集群能够自动关联Service资源的“名称”和“CLUSTER-IP”,从而达到服务被集群自动发现的目的。
(3)对StatefulSet控制的总结
1、部署有状态应用的
2、每个Pod的名称是唯一且固定不变的,而且每个Pod应该拥有自己专属的持久化存储(基于PVC模板volumeClaimTemplates绑定PV)
3、需要关联 Headless Service(ClusterIP为None),在K8S集群内部可通过 <pod_name>.<svc.name>.<namespace_name>.svc.cluster.local 的格式解析出 PodIP (基于无头服务和CoreDNS实现)
4、创建、删除、升级、扩缩容Pod都是有序进行的(默认为串行执行的):
创建、升级,扩容是升序执行的(顺序为Pod标识序号0..n-1),删除是逆序执行的(顺序为 n-1..0)
缩容和回滚都是逆序执行的(顺序为 n-1..0),会先删除旧Pod,再创建新Pod
3.DaemonSet控制器
3.1 DaemonSet控制器的运用
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
使用 DaemonSet 的一些典型用法:
●运行集群存储 daemon,例如在每个 Node 上运行 glusterd、ceph。
●在每个 Node 上运行日志收集 daemon,例如fluentd、logstash。
●在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter、collectd、Datadog 代理、New Relic 代理,或 Ganglia gmond。
应用场景:Agent
官方案例(监控):
3.2 DaemonSet控制器的案例演示
vim ds.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-daemonSet
labels:
app: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14
ports:
- containerPort: 80
kubectl apply -f ds.yaml
守护进程控制器会在每一个node节点上创建一个相同的pod
DaemonSet
1、理论上可以在K8S集群的所有Node节点上创建同类型的Pod资源(无论Node节点什么加入到K8S集群)
2、会受到Node节点上的污点或者cordon不可调度设置的影响。可以在Pod配置中设置容忍忽略污点,设置uncordon解除不可调度
3、不需要设置副本数replicas
4.Job控制器
4.1 job控制器的运用
Job分为普通任务(Job)和定时任务(CronJob)
常用于运行那些仅需要执行一次的任务
应用场景:数据库迁移、批处理脚本、kube-bench扫描、离线数据处理,视频解码等业务
4.2 job控制器的案例演示
vim job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
参数解释:
.spec.template.spec.restartPolicy该属性拥有三个候选值:OnFailure,Never和Always。默认值为Always。它主要用于描述Pod内容器的重启策略。在Job中只能将此属性设置为OnFailure或Never,否则Job将不间断运行。.spec.backoffLimit用于设置job失败后进行重试的次数,默认值为6。默认情况下,除非Pod失败或容器异常退出,Job任务将不间断的重试,此时Job遵循 .spec.backoffLimit上述说明。一旦.spec.backoffLimit达到,作业将被标记为失败。
5.CronJob
周期性任务,像Linux的Crontab一样。
周期性任务
应用场景:通知,备份
示例:
//每分钟打印hello
vim cronjob.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
//cronjob其它可用参数的配置
spec:
concurrencyPolicy: Allow #声明了 CronJob 创建的任务执行时发生重叠如何处理(并发性规则仅适用于相同 CronJob 创建的任务)。spec仅能声明下列规则中的一种:
●Allow (默认):CronJob 允许并发任务执行。
●Forbid:CronJob 不允许并发任务执行;如果新任务的执行时间到了而老任务没有执行完,CronJob 会忽略新任务的执行。
●Replace:如果新任务的执行时间到了而老任务没有执行完,CronJob 会用新任务替换当前正在运行的任务。
startingDeadlineSeconds: 15 #它表示任务如果由于某种原因错过了调度时间,开始该任务的截止时间的秒数。过了截止时间,CronJob 就不会开始任务,且标记失败.如果此字段未设置,那任务就没有最后期限。
successfulJobsHistoryLimit: 3 #要保留的成功完成的任务数(默认为3)
failedJobsHistoryLimit:1 #要保留多少已完成和失败的任务数(默认为1)
suspend:true #如果设置为 true ,后续发生的执行都会被挂起。 这个设置对已经开始的执行不起作用。默认是 false。
schedule: '*/1 * * * *' #必需字段,作业时间表。在此示例中,作业将每分钟运行一次
jobTemplate: #必需字段,作业模板。这类似于工作示例
kubectl create -f cronjob.yaml
kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 <none> 25s
kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-1621587180-mffj6 0/1 Completed 0 3m
hello-1621587240-g68w4 0/1 Completed 0 2m
hello-1621587300-vmkqg 0/1 Completed 0 60s
kubectl logs hello-1621587180-mffj6
Fri May 21 09:03:14 UTC 2021
Hello from the Kubernetes cluster
//如果报错:Error from server (Forbidden): Forbidden (user=system:anonymous, verb=get, resource=nodes, subresource=proxy) ( pods/log hello-1621587780-c7v54)
//解决办法:绑定一个cluster-admin的权限
kubectl create clusterrolebinding system:anonymous --clusterrole=cluster-admin --user=system:anonymous文章来源:https://www.toymoban.com/news/detail-549880.html
总结
Pod 控制器有几种?
1、Deployment+ReplicaSet 部署无状态应用的Pod
2、StatefulSet 部署有状态应用的Pod
3、DaemonSet 在K8S集群的所有Node节点上部署相同的Pod
4、Job 部署一次性的任务Pod,完成后就会退出并不会重启
5、CronJob 部署周期性的任务Pod,完成后就会退出并不会重启
Deployment
1、部署无状态应用的
2、创建和管理 ReplicaSet(RS)和Pod资源,维护Pod副本数量与期望值相同
3、创建和删除Pod时是并行执行的,升级时是先创建一部分新Pod,再删除一部分旧Pod
StatefulSet
1、部署有状态应用的
2、每个Pod的名称是唯一且固定不变的,而且每个Pod应该拥有自己专属的持久化存储(基于PVC模板volumeClaimTemplates绑定PV)
3、需要关联 Headless Service(ClusterIP为None),在K8S集群内部可通过 <pod_name>.<svc.name>.<namespace_name>.svc.cluster.local 的格式解析出 PodIP (基于无头服务和CoreDNS实现)
4、创建、删除、升级、扩缩容Pod都是有序进行的(默认为串行执行的):
创建、升级是升序执行的(顺序为Pod标识序号0..n-1),删除是逆序执行的(顺序为 n-1..0)
扩缩容都是逆序执行的(顺序为 n-1..0),会先删除旧Pod,再创建新Pod
spec.podManagementPolicy: Parallel #可设置StatefulSet创建和删除Pod时为并行执行
service类型种类 4+1
ClusterIP
NodePort
LoadBalancer
ExtenalName
Headless Service
常规service与Headless Service的区别
常规service:一组Pod的访问策略,提供ClusterIP在K8S集群内部访问,还提供负载均衡和服务发现功能
Headless Service:无头服务,可以不需要ClusterIP,与StatefulSet资源关联配合CoreDNS实现通过 Pod名称 解析出 PodIP
DaemonSet
1、理论上可以在K8S集群的所有Node节点上创建同类型的Pod资源(无论Node节点什么加入到K8S集群)
2、会受到Node节点上的污点或者cordon不可调度设置的影响。可以在Pod配置中设置容忍忽略污点,设置uncordon解除不可调度
3、不需要设置副本数replicas
Job
1、部署一次性任务的资源
2、任务正常完成后Pod容器会立即退出并不会再重启(Job类型Pod容器的retartPolicy通常设置为Never),也不会重建Pod
3、如果任务异常完成Pod容器异常退出,会重建Pod重试任务,重试次数根据 backoffLimit 配置(默认6次)
CronJob
1、部署周期性任务的资源,一次任务至少创建一个Pod
2、任务正常完成后Pod容器会立即退出并不会再重启(Job类型Pod容器的retartPolicy不设置为Always),也不会重建Pod
3、使用 spec.schedule 字段设置时间周期表,格式为 '分 时 日 月 周'文章来源地址https://www.toymoban.com/news/detail-549880.html
到了这里,关于【云原生】k8s之pod控制器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!