SELECT
| SELECT [ALL|DISTINCT] column1,column2,……#ALL表示保留所有,DISTINCT表示去掉目标列值重复的元组 FROM table_name [WHERE condition] [GROUP BY 字段名 HAVING condition]#查询结果按照字段进行分组,该字段相等的为一组 [ORDER BY 字段名 [ASC|DESC]]#每个分组的查询结果按字段排序,ASC升序,DESC降序 |
一般例子:
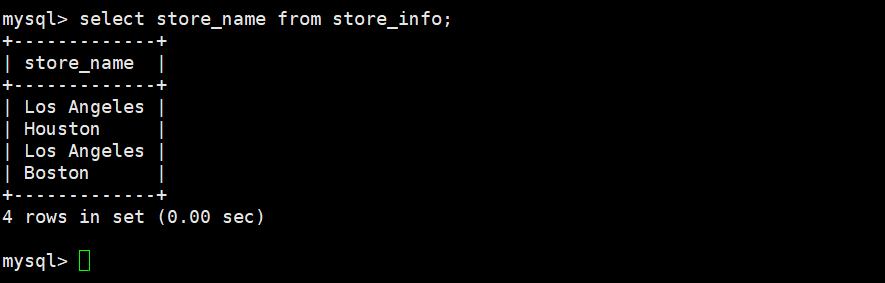
| SELECT * FROM table_name; |
| SELECT column1,column2…… FROM table_name; |
| SELECT DISTINCT sno FROM table_name;#去掉sno重复的列 |
一些下面要用到的聚集函数:
| COUNT(*):统计元组的个数 |
| COUNT([DISTINCT|ALL] 字段名):统计某一列值的个数 |
| SUM([DISTINCT|ALL] 列名):计算某一列值的总和 |
| AVG([DISTINCT|ALL] 列名):计算某一列的平均值 |
| MAX([DISTINCT|ALL] 列名):求某一列的最大值 |
| MIN([DISTINCT|ALL] 列名):求某一列的最小值 |
WHERE的条件中不可以使用聚集函数
GROUP BY语句:
| GROUP BY语句将查询结果按某一列或多列的值分组,值相等的为一组; 如果分组后还要求按一定条件对这些组进行筛选,最终只输出满足条件的组,则可以使用HAVING短语筛选条件,HAVING后的条件语句中可以使用聚集函数。 |
ORDER BY语句:默认为升序,子查询中不可以使用该语句
自身连接:
| SELECT FIRST.id,SECOND.id FROM table_name FIRST,table_name SECOND WHERE FIRST.column1=SECOND.column2; |
外连接:
| FROM table_name1 LEFT OUTER JOIN SC ON (condition);#左外连接 |
嵌套查询:
| SELECT column FROM table_name WHERE condition #condition里面可以是一个查询块 |
带有EXISTS的查询:后续再说
SELECT 的查询结果是元组的集合,所以多个SELECT语句的结果可进行集合操作,集合操作主要包括并操作UNION,交操作INTERSECT,差操作EXCEPT
| 查询块1 集合操作文章来源:https://www.toymoban.com/news/detail-550884.html 查询块2文章来源地址https://www.toymoban.com/news/detail-550884.html |
到了这里,关于MySQL数据查询的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!