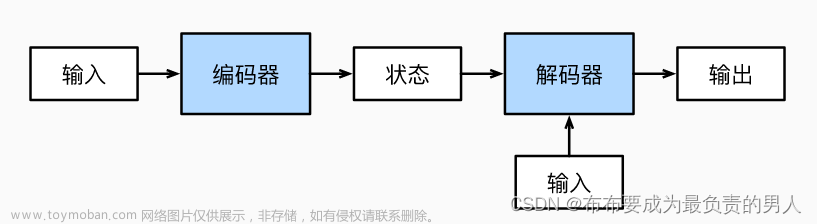
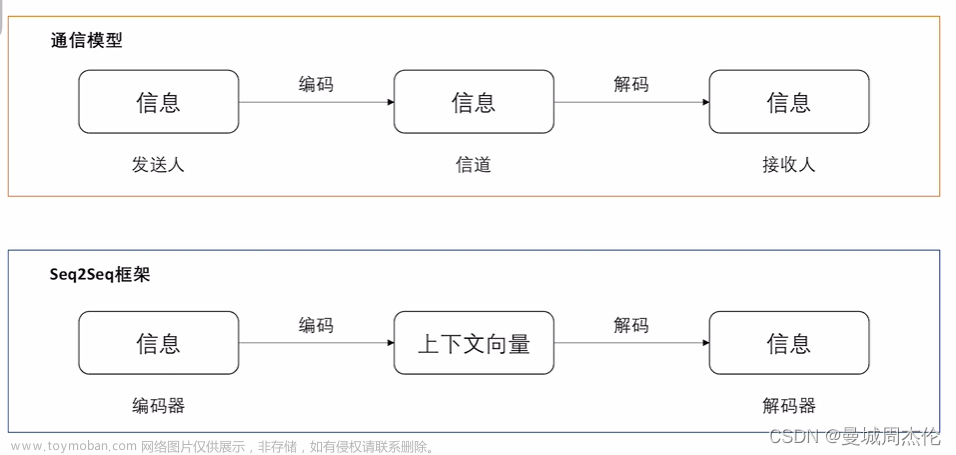
引言
本着“凡我不能创造的,我就不能理解”的思想,本系列文章会基于纯Python以及NumPy从零创建自己的深度学习框架,该框架类似PyTorch能实现自动求导。
要深入理解深度学习,从零开始创建的经验非常重要,从自己可以理解的角度出发,尽量不使用外部完备的框架前提下,实现我们想要的模型。本系列文章的宗旨就是通过这样的过程,让大家切实掌握深度学习底层实现,而不是仅做一个调包侠。
本文我们为seq2seq模型加上注意力机制,同样也来做机器翻译任务。
注意力层

在上篇文章中我们对注意力机制有一个详细的解释,这里直接拿过来用。
class Attention(nn.Module):
def __init__(self, enc_hid_dim=None, dec_hid_dim=None, method: str = "dot") -> None:
"""
Args:
enc_hid_dim: 编码器的隐藏层大小
dec_hid_dim: 解码器的隐藏层大小
method: dot | scaled_dot | general | bahdanau | concat
Returns:
"""
super().__init__()
self.method = method
self.encoder_hidden_size = enc_hid_dim
self.decoder_hidden_size = dec_hid_dim
if self.method not in ["dot", "scaled_dot", "general", "bahdanau", "concat"]:
raise ValueError(self.method, "is not an appropriate attention method.")
if self.method not in ["dot", "scaled_dot"] and (
self.encoder_hidden_size is None or self.decoder_hidden_size is None):
raise ValueError(self.method, "must pass encoder and decoer hidden size parameter.")
if self.method == "general":
self.linear = nn.Linear(self.encoder_hidden_size, self.decoder_hidden_size, bias=False)
elif self.method == "bahdanau":
self.W = nn.Linear(self.decoder_hidden_size, self.decoder_hidden_size, bias=False)
self.U = nn.Linear(self.encoder_hidden_size, self.decoder_hidden_size, bias=False)
self.v = nn.Linear(self.decoder_hidden_size, 1, bias=False)
elif self.method == "concat":
# concat
self.linear = nn.Linear((self.encoder_hidden_size + self.decoder_hidden_size), self.decoder_hidden_size,
bias=False)
self.v = nn.Linear(self.decoder_hidden_size, 1, bias=False)
def _score(self, hidden: Tensor, encoder_outputs: Tensor) -> Tensor:
"""
Args:
hidden: (batch_size, decoder_hidden_size) 解码器前一时刻的隐藏状态
encoder_outputs: (src_len, batch_size, encoder_hidden_size) 编码器的输出(隐藏状态)序列
Returns:
"""
src_len, batch_size, encoder_hidden_size = encoder_outputs.shape
if self.method == "dot":
# 这里假设编码器和解码器的隐藏层大小一致,如果不一致,不能直接使用点积注意力
# (batch_size, hidden_size) * (src_len, batch_size, hidden_size) -> (src_len, batch_size, hidden_size)
# (src_len, batch_size, hidden_size).sum(axis=2) -> (src_len, batch_size)
return (hidden * encoder_outputs).sum(axis=2)
elif self.method == "scaled_dot":
# 和点积注意力类似,不过除以sqrt(batch_size),也可以指定一个自定义的值
return (hidden * encoder_outputs / math.sqrt(encoder_hidden_size)).sum(axis=2)
elif self.method == "general":
# energy = (src_len, batch_size, decoder_hidden_size)
energy = self.linear(encoder_outputs)
# (batch_size, decoder_hidden_size) * (src_len, batch_size, decoder_hidden_size)
# -> (src_len, batch_size, decoder_hidden_size)
# .sum(axis=2) -> (src_len, batch_size)
return (hidden * energy).sum(axis=2)
elif self.method == "bahdanau":
# hidden = (batch_size, decoder_hidden_size)
# encoder_outputs = (src_len, batch_size, encoder_hidden_size)
# W(hidden) -> (batch_size, decoder_hidden_size)
# U(encoder_outputs) -> (src_len, batch_size, decoder_hidden_size)
# energy = (src_len, batch_size, decoder_hidden_size)
energy = F.tanh(self.W(hidden) + self.U(encoder_outputs))
# v(energy) -> (src_len, batch_size, 1)
# squeeze -> (src_len, batch_size)
return self.v(energy).squeeze(2)
else:
# concat
# unsqueeze -> (1, batch_size, decoder_hidden_size)
# hidden = (src_len, batch_size, decoder_hidden_size)
hidden = hidden.unsqueeze(0).repeat(src_len, 1, 1)
# encoder_outputs = (src_len, batch_size, encoder_hidden_size)
# cat -> (src_len, batch_size, encoder_hidden_size +decoder_hidden_size)
# linear -> (src_len, batch_size, decoder_hidden_size)
energy = F.tanh(self.linear(F.cat((hidden, encoder_outputs), axis=2)))
# v -> (src_len, batch_size , 1)
# squeeze -> (src_len, batch_size)
return self.v(energy).squeeze(2)
def forward(self, hidden: Tensor, encoder_outputs: Tensor) -> Tuple[Tensor, Tensor]:
"""
Args:
hidden: (batch_size, decoder_hidden_size) 解码器前一时刻的隐藏状态
encoder_outputs: (src_len, batch_size, encoder_hidden_size) 编码器的输出(隐藏状态)序列
Returns: 注意力权重, 上下文向量
"""
# (src_len, batch_size)
attn_scores = self._score(hidden, encoder_outputs)
# (batch_size, src_len)
attn_scores = attn_scores.T
# (batch_size, 1, src_len)
attention_weight = F.softmax(attn_scores, axis=1).unsqueeze(1)
# encoder_outputs = (batch_size, src_len, num_hiddens)
encoder_outputs = encoder_outputs.transpose((1, 0, 2))
# context = (batch_size, 1, num_hiddens)
context = F.bmm(attention_weight, encoder_outputs)
# context = (1, batch_size, num_hiddens)
context = context.transpose((1, 0, 2))
return attention_weight, context
def __repr__(self):
return f"Attention(self.method={self.method}, encoder_hidden_size={self.encoder_hidden_size}, decoder_hidden_size={self.decoder_hidden_size})"
编码器
class Encoder(nn.Module):
def __init__(self, vocab_size: int, embed_size: int, num_hiddens: int, num_layers: int, dropout: float) -> None:
"""
基于GRU实现的编码器
:param vocab_size: 源词表大小
:param embed_size: 词嵌入大小
:param num_hiddens: 隐藏层大小
:param num_layers: GRU层数
:param dropout: dropout比率
"""
super().__init__()
# 嵌入层 获取输入序列中每个单词的嵌入向量 padding_idx不需要更新嵌入
self.embedding = nn.Embedding(vocab_size, embed_size, padding_idx=0)
# 这里固定为双向GRU实现 注意,这里默认batch_first为False
self.rnn = nn.GRU(input_size=embed_size, hidden_size=num_hiddens, num_layers=num_layers, dropout=dropout,
bidirectional=True)
self.fc = nn.Linear(num_hiddens * 2, num_hiddens)
self.dropout = nn.Dropout(dropout)
def forward(self, input_seq: Tensor) -> Tuple[Tensor, Tensor]:
"""
编码器的前向算法
:param input_seq: 形状 (seq_len, batch_size)
:return:
"""
# (seq_len, batch_size, embed_size)
embedded = self.dropout(self.embedding(input_seq))
# embedded = self.embedding(input_seq)
# outputs (seq_len, batch_size, 2 * num_hiddens)
# hidden (num_direction * num_layers, batch_size, num_hiddens)
# hidden 堆叠了 [forward_1, backward_1, forward_2, backward_2, ...]
# hidden[-2, :, :] 是最后一个前向 RNN
# hidden[-1, :, :] 是最后一个反向 RNN
# outputs 总是来自最后一层
outputs, hidden = self.rnn(embedded)
# 编码器初始隐藏状态是解码器最后一个前向和反向 RNN
# 编码器的RNN喂给一个线性层来融合
hidden = F.tanh(self.fc(F.cat((hidden[-2, :, :], hidden[-1, :, :]), axis=1)))
# outputs = (seq_len, batch_size, num_hiddens)
outputs = outputs[:, :, :num_hiddens] + outputs[:, :, :num_hiddens]
# outputs (seq_len, batch_size, num_hiddens)
# hidden (batch_size, num_hiddens)
return outputs, hidden
编码器没啥变化,这里我们合并了双向上的outputs,最后的大小变成num_hiddens。为了方便使用点积注意力。
解码器
class Decoder(nn.Module):
def __init__(self, vocab_size: int, embed_size: int, num_hiddens: int, num_layers: int, dropout: float,
attention: Attention) -> None:
"""
基于GRU实现的解码器
:param vocab_size: 目标词表大小
:param embed_size: 词嵌入大小
:param num_hiddens: 隐藏层大小
:param num_layers: 层数
:param dropout: dropout比率
:param attention: Attention实例
"""
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size, padding_idx=0)
self.rnn = nn.GRU(input_size=embed_size + num_hiddens, hidden_size=num_hiddens, num_layers=num_layers,
dropout=dropout)
# 将隐状态转换为词典大小维度
self.fc_out = nn.Linear(num_hiddens, vocab_size)
self.vocab_size = vocab_size
self.dropout = nn.Dropout(dropout)
self.attention = attention
def forward(self, input_seq: Tensor, hidden: Tensor, encoder_outputs: Tensor) -> Tuple[Tensor, Tensor]:
"""
解码器的前向算法
:param input_seq: 初始输入,这里为<bos> 形状 (batch_size, )
:param hidden: 解码器的隐藏状态 (batch_size, num_hiddens)
:param encoder_outputs: 编码器的输出的隐藏状态序列 形状 (src_len, batch_size, num_hiddens)
:return:
"""
# input = (1, batch_size)
input_seq = input_seq.unsqueeze(0)
# embedded = (1, batch_size, embed_size)
embedded = self.dropout(self.embedding(input_seq))
# attention = (batch_size, 1, src_len)
# context = (1, batch_size, num_hiddens)
attention, context = self.attention(hidden, encoder_outputs)
# embedded_context = (1, batch_size, embed_size + hidden_dim)
embedded_context = F.cat((embedded, context), 2)
# output (1, batch_size, num_hiddens)
# hidden (1, batch_size, num_hiddens)
output, hidden = self.rnn(embedded_context, hidden.unsqueeze(0))
# prediction (batch_size, vocab_size)
prediction = self.fc_out(output.squeeze(0))
# hidden = (batch_size, num_hiddens)
return prediction, hidden.squeeze(0)
解码器初始化时接收Attention实例。
在forward中如何引入这个注意力呢?主要传入解码器上个时间步的隐藏状态和编码器所有时间步的输出即可。主要代码封装到了Attention类中。
他会返回注意力权重和基于它动态计算的上下文。
我们只要把这个上下文拼接到词嵌入之后再喂给RNN即可。
Seq2seq
class Seq2seq(nn.Module):
def __init__(self, encoder: Encoder, decoder: Decoder) -> None:
"""
初始化seq2seq模型
:param encoder: 编码器
:param decoder: 解码器
"""
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, input_seq: Tensor, target_seq: Tensor, teacher_forcing_ratio: float = 0.0) -> Tensor:
"""
seq2seq的前向算法
:param input_seq: 输入序列 (seq_len, batch_size)
:param target_seq: 目标序列 (seq_len, batch_size)
:param teacher_forcing_ratio: 强制教学比率
:return:
"""
tgt_len, batch_size = target_seq.shape
# 保存了所有时间步的输出
outputs = []
# 这里我们只关心编码器输出的hidden
# hidden (num_layers, batch_size, num_hiddens)
encoder_outputs, hidden = self.encoder(input_seq)
# decoder_input (batch_size) 取BOS token
decoder_input = target_seq[0, :] # BOS_TOKEN
# 这里从1开始,确保tgt[t]是下一个token
for t in range(1, tgt_len):
# output (batch_size, target_vocab_size)
# hidden (num_layers, batch_size, num_hiddens)
output, hidden = self.decoder(decoder_input, hidden, encoder_outputs)
# 保存到outputs
outputs.append(output)
# 随机判断是否强制教学
teacher_force = random.random() < teacher_forcing_ratio
# 如果teacher_force==True, 则用真实输入当成下一步的输入,否则用模型生成的
# output.argmax(1) 在目标词表中选择得分最大的一个 (batch_size, 1)
decoder_input = target_seq[t] if teacher_force else output.argmax(1)
# 把outputs转换成一个Tensor 形状为: (tgt_len - 1, batch_size, target_vocab_size)
return F.stack(outputs)
seq2seq实现变动不大,解码时传入编码器的所有输出。
计算BLEU得分
另外我们在测试集上计算BLEU得分来判断模型的好坏,而不是通过损失。
后面也有会一篇文章专门介绍BLEU得分是如何计算的。
def cal_bleu_score(net, data_path, src_vocab, tgt_vocab, seq_len, device):
net.eval()
source, target = build_nmt_pair(os.path.join(data_path, "test.de"),
os.path.join(data_path, "test.en"),
reverse=True)
predicts = []
labels = []
for src, tgt in zip(source, target):
predict = translate(net, src, src_vocab, tgt_vocab, seq_len, device)
predicts.append(predict)
labels.append([tgt]) # 因为reference可以有多条,所以是一个列表
return bleu_score(predicts, labels)
def translate(model, src_sentence, src_vocab, tgt_vocab, max_len, device):
"""翻译一句话"""
# 在预测时设置为评估模式
model.eval()
if isinstance(src_sentence, str):
src_tokens = [src_vocab[Vocabulary.BOS_TOKEN]] + [src_sentence.split(' ')] + [src_vocab[Vocabulary.EOS_TOKEN]]
else:
src_tokens = [src_vocab[Vocabulary.BOS_TOKEN]] + src_vocab[src_sentence] + [src_vocab[Vocabulary.EOS_TOKEN]]
src_tokens = truncate_pad(src_tokens, max_len, src_vocab[Vocabulary.PAD_TOKEN])
# 添加批量轴
src_tensor = Tensor(src_tokens, dtype=int, device=device).unsqueeze(1)
with no_grad():
encoder_outputs, hidden = model.encoder(src_tensor)
trg_indexes = [tgt_vocab[Vocabulary.BOS_TOKEN]]
for _ in range(max_len):
trg_tensor = Tensor([trg_indexes[-1]], dtype=int, device=device)
with no_grad():
output, hidden = model.decoder(trg_tensor, hidden, encoder_outputs)
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
pred_token = output.argmax(1).item()
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred_token == tgt_vocab[Vocabulary.EOS_TOKEN]:
break
trg_indexes.append(pred_token)
return tgt_vocab.to_tokens(trg_indexes)[1:]
参数定义
# 参数定义
embed_size = 256
num_hiddens = 512
num_layers = 1
dropout = 0.5
batch_size = 128
max_len = 40
lr = 0.001
num_epochs = 10
min_freq = 2
clip = 1.0
tf_ratio = 0.5 # teacher force ratio
print_every = 1
device = cuda.get_device("cuda" if cuda.is_available() else "cpu")
加载数据集
# 加载训练集
train_iter, src_vocab, tgt_vocab = load_dataset_nmt(data_path=base_path, data_type="train", batch_size=batch_size,
min_freq=min_freq, shuffle=True)
# 加载验证集
valid_iter, src_vocab, tgt_vocab = load_dataset_nmt(data_path=base_path, data_type="val", batch_size=batch_size,
min_freq=min_freq, src_vocab=src_vocab, tgt_vocab=tgt_vocab)
# 加载测试集
test_iter, src_vocab, tgt_vocab = load_dataset_nmt(data_path=base_path, data_type="test", batch_size=batch_size,
min_freq=min_freq, src_vocab=src_vocab, tgt_vocab=tgt_vocab)
构建模型
注意力先用scaled_dot试试。
# 构建Attention
attention = Attention(num_hiddens , num_hiddens, method="scaled_dot")
# 构建编码器
encoder = Encoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
# 构建解码器
decoder = Decoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout, attention)
model = Seq2seq(encoder, decoder)
model.apply(init_weights)
model.to(device)
print(model)
TGT_PAD_IDX = tgt_vocab[Vocabulary.PAD_TOKEN]
print(f"TGT_PAD_IDX is {TGT_PAD_IDX}")
optimizer = Adam(model.parameters())
criterion = CrossEntropyLoss(ignore_index=TGT_PAD_IDX)
训练&验证
train(model, num_epochs, train_iter, valid_iter, optimizer, criterion, clip, device, tf_ratio)
# 加载valid loss最小的模型
model.load()
model.to(device)
test_loss = evaluate(model, test_iter, criterion, device)
print(f"Test loss: {test_loss:.4f}")
bleu_score = cal_bleu_score(model, base_path, src_vocab, tgt_vocab, max_len, device)
print(f"BLEU Score = {bleu_score * 100:.2f}")
我们在计算损失时还是除以样本个数。
在训练完之后,加载训练过程中验证损失最小的模型。计算测试集上的损失和BLEU得分。
Source vocabulary size: 7859, Target vocabulary size: 5921
max_src_len: 44, max_tgt_len:40
Source vocabulary size: 7859, Target vocabulary size: 5921
max_src_len: 33, max_tgt_len:30
Source vocabulary size: 7859, Target vocabulary size: 5921
max_src_len: 31, max_tgt_len:33
Seq2seq(
(encoder): Encoder(
(embedding): Embedding(7859, 256, padding_idx=0)
(rnn): GRU(input_size=256, hidden_size=512, dropout=0.5, bidirectional=True)
(fc): Linear(in_features=1024, out_features=512, bias=True)
(dropout): Dropout(p=0.5)
)
(decoder): Decoder(
(embedding): Embedding(5921, 256, padding_idx=0)
(rnn): GRU(input_size=768, hidden_size=512, dropout=0.5)
(fc_out): Linear(in_features=512, out_features=5921, bias=True)
(dropout): Dropout(p=0.5)
(attention): Attention(self.method=scaled_dot, encoder_hidden_size=512, decoder_hidden_size=512)
)
)
TGT_PAD_IDX is 0
Training: 0%| | 0/10 [00:00<?, ?it/s]Save module to model.pkl
epoch 1 , train loss: 0.0197 , validate loss: 0.0188, best validate loss: 0.0188
Training: 10%|█████████████████ | 1/10 [01:01<09:16, 61.84s/it]Save module to model.pkl
epoch 2 , train loss: 0.0158 , validate loss: 0.0159, best validate loss: 0.0159
Training: 20%|██████████████████████████████████ | 2/10 [02:02<08:10, 61.33s/it]Save module to model.pkl
epoch 3 , train loss: 0.0132 , validate loss: 0.0146, best validate loss: 0.0146
Training: 30%|███████████████████████████████████████████████████ | 3/10 [03:02<07:03, 60.52s/it]Save module to model.pkl
epoch 4 , train loss: 0.0115 , validate loss: 0.0135, best validate loss: 0.0135
Training: 40%|████████████████████████████████████████████████████████████████████ | 4/10 [04:02<06:02, 60.39s/it]Save module to model.pkl
epoch 5 , train loss: 0.0106 , validate loss: 0.0132, best validate loss: 0.0132
Training: 50%|█████████████████████████████████████████████████████████████████████████████████████ | 5/10 [05:03<05:02, 60.46s/it]Save module to model.pkl
epoch 6 , train loss: 0.0098 , validate loss: 0.0130, best validate loss: 0.0130
Training: 60%|██████████████████████████████████████████████████████████████████████████████████████████████████████ | 6/10 [06:03<04:01, 60.33s/it]Save module to model.pkl
epoch 7 , train loss: 0.0090 , validate loss: 0.0129, best validate loss: 0.0129
Training: 70%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉ | 7/10 [07:02<03:00, 60.13s/it]Save module to model.pkl
epoch 8 , train loss: 0.0086 , validate loss: 0.0128, best validate loss: 0.0128
Training: 80%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 8/10 [08:02<01:59, 59.99s/it]Save module to model.pkl
epoch 9 , train loss: 0.0081 , validate loss: 0.0125, best validate loss: 0.0125
epoch 10 , train loss: 0.0077 , validate loss: 0.0125, best validate loss: 0.0125
Test loss: 0.0128
BLEU Score = 32.05
从上面的训练过程可以看到,从第9个epoch开始,验证损失已经不再下降了。
最终得到了BLEU得分是32.05,还可以的一个分数。
上面是scaled_dot注意力的结果,如果改成简单的dot呢?
epoch 10 , train loss: 0.0097 , validate loss: 0.0139, best validate loss: 0.0139
Test loss: 0.0140
BLEU Score = 21.21
可以看到,效果就差了不少了。
至此,seq2seq相关的核心内容已经学习的差不多了,上面介绍了一些trick,比如定义clip,使用teacher force等。剩下一个让我们实现的RNN支持PackedSequence高效计算。文章来源:https://www.toymoban.com/news/detail-550957.html
完整代码
点此 github文章来源地址https://www.toymoban.com/news/detail-550957.html
到了这里,关于从零实现深度学习框架——带Attentiond的Seq2seq机器翻译的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!