第9章 Prompt本质解密及Evaluation实战与源码解析
9.1 Customer Service案例
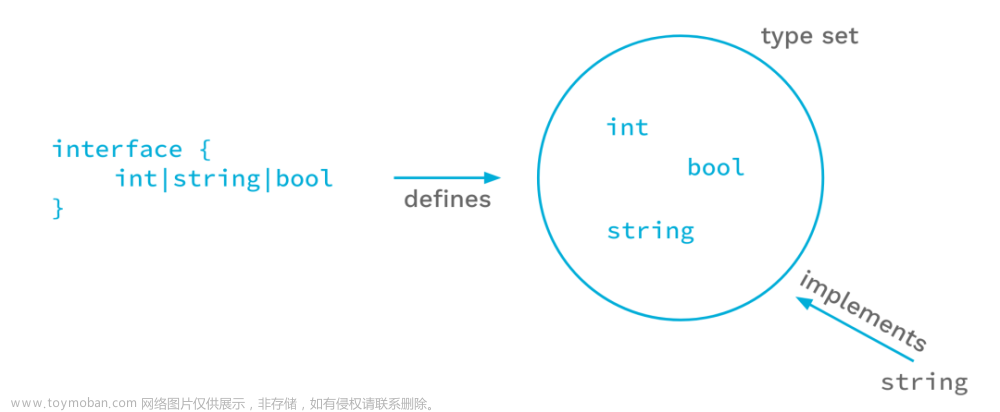
本节主要谈提示词(Prompt)内部的工作机制,围绕案例、源码、论文三个维度展开。首先,我们可以看一下代码部分,这是对基于大模型应用程序开发的一个评估(Evaluation),这显然是一个至关重要的内容。大家做所有基于机器学习的模型,或者所有NLP的项目,对应用程序的评估是一个核心性的东西,因为程序的版本升级或者迭代,需对程序的表现进行评估,提供一些基本的数据,但是对大模型的评估,它跟传统的机器学习不太一样,尤其是基于GPT系列或者生成语言模型,因为它生成的内容,和传统经典意义上的基于内容和标签进行评估,不太完全一样。
Gavin大咖微信:NLP_Matrix_Space
OpenAI官方提供了一些指导,DeepLearning.AI借助OpenAI的一些指导思想,提出了对结果评估的一些具体步骤,我们来看一下,DeepLearning.AI提供的示例中,它的提示词写的非常经典,第一是因为它有效,第二是其他很多开源框架和产品中,都会有类似的实现或者类似的提示词。文章来源地址https://www.toymoban.com/news/detail-551710.html
1. def eval_with_rubric(test_set, assistant_answer文章来源:https://www.toymoban.com/news/detail-551710.html
到了这里,关于Prompt本质解密及Evaluation实战与源码解析(一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!