Ceph-RDB
1、RBD架构图
Ceph 可以同时提供对象存储 RADOSGW、块存储 RBD、文件系统存储 Ceph FS,RBD 即
RADOS Block Device 的简称,RBD 块存储是常用的存储类型之一,RBD 块设备类似磁盘
可以被挂载,RBD 块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式
存储在 Ceph 集群的多个 OSD 中。
客户端访问RBD设备的方式有两种
- 通过内核模块rbd.ko将image映射为节点本地设备,相关的设备文件一半为/dev/rbd#(#为设备的编号,如0,1,2,3…)
- 通过librbd提供的API接口,它支持C/C++和python等编程语言,qemu即是此类接口的客户端

2、RBD的使用逻辑
RBD接口在ceph环境创建完毕后,就在服务端自动提供了;客户端基于librbd库即可将RADOS存储集群用作块设备
这个过程主要步骤如下:
1、创建一个专用的存储池
2、对存储池启用rbd功能
3、对存储池进行环境初始化
4、基于存储池创建专用的磁盘镜像
2.1 RBD的基本操作
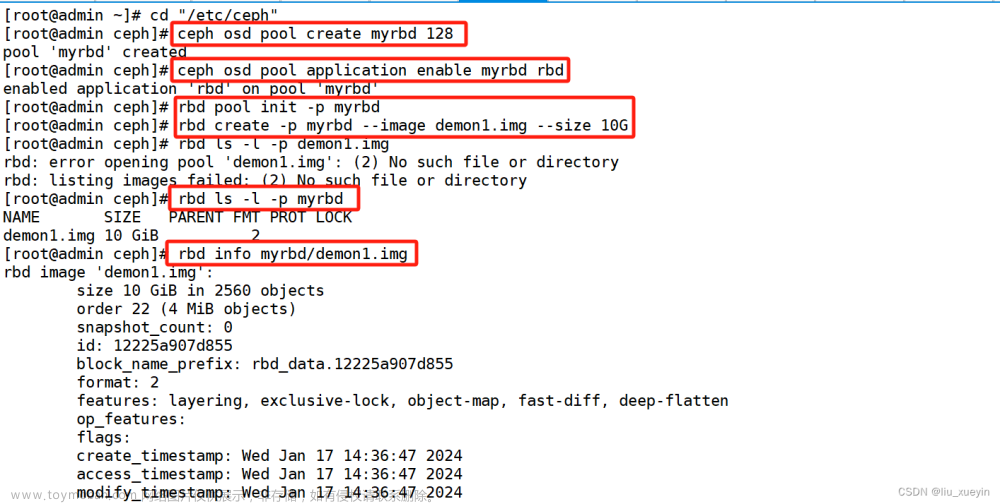
1、创建存储池
cephadmin@ceph-mon1:~$ ceph osd pool create rdb-data1 32 32
2、验证存储池
cephadmin@ceph-mon1:~$ ceph osd pool ls
3、在存储池启动rbd服务
cephadmin@ceph-mon1:~$ ceph osd pool application enable rbd-data1 rbd
4、初始化rbd
cephadmin@ceph-mon1:~$ rbd pool init -p rdb-data1
5、创建img镜像
rbd存储池并不能直接用块设备,而是要事先在存储中按需创建映像(image),并把映像文件作为块设备使用。rbd命令可用于创建、查看、删除块设备相在的映像(image),以及克隆映像、创建快照、将映像回滚到快照和查看快照等管理操作
rbd create data-img1 --size 3G --pool rbd-data1 --image-format 2 --image-feature layering
rbd create data-img1 --size 3G --pool rbd-data1 --image-format 2 --image-feature layering
6、验证镜像
cephadmin@ceph-mon1:~$ rbd ls --pool rdb-data1
data-img1
data-img2
#列出镜像多个信息
cephadmin@ceph-mon1:~$ rbd ls --pool rdb-data1 -l
NAME SIZE PARENT FMT PROT LOCK
data-img1 3 GiB 2 excl
data-img2 5 GiB 2
#查看镜像的详细信息
cephadmin@ceph-mon1:~$ rbd --image data-img1 --pool rdb-data1 info
rbd image 'data-img1':
size 3 GiB in 768 objects #镜像的大小
order 22 (4 MiB objects) #对象大小,每个对象是2^22/1024/1024=4M ,一个object默认是4M
snapshot_count: 0 #快照的数量
id: fbe8dbe36241 #镜像id
block_name_prefix: rbd_data.fbe8dbe36241
format: 2 #镜像文件格式版本
features: layering, exclusive-lock #镜像的特性
op_features:
flags:
create_timestamp: Mon Jul 10 11:38:21 2023
access_timestamp: Mon Jul 10 11:38:21 2023
modify_timestamp: Mon Jul 10 11:38:21 2023
#以json格式显示镜像的信息
cephadmin@ceph-mon1:~$ rbd ls --pool rdb-data1 -l --format json --pretty-format
[
{
"image": "data-img1",
"id": "fbe8dbe36241",
"size": 3221225472,
"format": 2,
"lock_type": "exclusive"
},
{
"image": "data-img2",
"id": "fbf151dcf736",
"size": 5368709120,
"format": 2
}
]
7、设置镜像的特性
#镜像的特性:
(1)layering: 支持镜像分层快照特性,用于快照及写时复制,可以对image创建快照并保护,然后从快照克隆出新的image出来,父子image之间采取COW技术,共享对象数据
(2)striping: 支持条带化 v2,类似 raid 0,只不过在 ceph 环境中的数据被分散到不同的对象
中,可改善顺序读写场景较多情况下的性能。
(3)exclusive-lock: 支持独占锁,限制一个镜像只能被一个客户端使用。
(4)object-map: 支持对象映射(依赖 exclusive-lock),加速数据导入导出及已用空间统计等,此特性开启的时候,会记录 image 所有对象的一个位图,用以标记对象是否真的存在,在一些场景下可以加速 io。
(5)fast-diff: 快速计算镜像与快照数据差异对比(依赖 object-map)。
(6)deep-flatten: 支持快照扁平化操作,用于快照管理时解决快照依赖关系等。
(7)journaling: 修改数据是否记录日志,该特性可以通过记录日志并通过日志恢复数据(依赖独
占锁),开启此特性会增加系统磁盘 IO 使用。
jewel 默 认 开 启 的 特 性 包 括: layering/exlcusive lock/object map/fast diff/deep flatten
#启用指定存储池中的指定镜像的特性
cephadmin@ceph-mon1:~$ rbd feature enable exclusive-lock --pool rbd-data1 --image data-img1
cephadmin@ceph-mon1:~$ rbd feature enable object-map --pool rbd-data1 --image data-img1
cephadmin@ceph-mon1:~$ rbd feature enable fast-diff --pool rbd-data1 --image data-img1
#禁用指定存储池中的指定镜像的特性
cephadmin@ceph-mon1:~$ rbd feature disable exclusive-lock --pool rbd-data1 --image data-img1
#验证镜像的特性
cephadmin@ceph-mon1:~$ rbd --image data-img1 --pool rbd-data1 info
2.2配置客户端管理用户挂载并使用RBD
1、安装ceph-common
root@client:~# apt -y install ceph-common
2、从部署服务器同步认证文件
cephadmin@ceph-mon1:~$ sudo scp ceph.conf ceph.client.admin.keyring root@172.17.10.10:/etc/ceph
3、客户端映射镜像
root@client:~# rbd -p rbd-data1 map data-img1
4、客户端验证镜像
root@client:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 200G 0 disk
├─sda1 8:1 0 1M 0 part
├─sda2 8:2 0 10G 0 part /boot
└─sda3 8:3 0 100G 0 part /
sr0 11:0 1 969M 0 rom
rbd0 252:0 0 3G 0 disk /data/data1 #映射的镜像
rbd1 252:16 0 5G 0 disk /data/data2 #映射的镜像
5、客户端格式化磁盘
root@client:~# mkfs.xfs /dev/rbd0
root@client:~# mkfs.xfs /dev/rbd1
6、客户端挂载使用磁盘
root@client:~# mkdir -p /data/data1
root@client:~# mount /dev/rbd0 /data/data1
root@client:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 1.9G 0 1.9G 0% /dev
tmpfs 393M 13M 380M 4% /run
/dev/sda3 98G 7.9G 86G 9% /
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/sda2 9.8G 116M 9.2G 2% /boot
/dev/rbd0 3.0G 152M 2.9G 5% /data/data1
7、部署一个mysql容器,数据库的数据挂载到/data/data1,验证是否能写入数据
root@client:~# docker run -it -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 -v /data/data1:/var/lib/mysql mysql:5.6.46
root@client:~# root@client:/data/data1# ll
total 110608
drwxr-xr-x 5 999 mysql 125 Jul 10 07:26 ./
drwxr-xr-x 4 mysql mysql 4096 Jul 10 06:57 ../
-rw-rw---- 1 999 999 56 Jul 10 07:22 auto.cnf
-rw-rw---- 1 999 999 12582912 Jul 10 07:22 ibdata1
-rw-rw---- 1 999 999 50331648 Jul 10 07:22 ib_logfile0
-rw-rw---- 1 999 999 50331648 Jul 10 07:21 ib_logfile1
drwx------ 2 999 999 4096 Jul 10 07:22 mysql/
drwx------ 2 999 999 4096 Jul 10 07:22 performance_schema/
#进入到数据库中,创建一个数据,看数据是否同步到/data/data1目录中
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.6.46 MySQL Community Server (GPL)
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>create database rbd-test
root@client:/data/data1# ll
total 110608
drwxr-xr-x 5 999 mysql 125 Jul 10 07:26 ./
drwxr-xr-x 4 mysql mysql 4096 Jul 10 06:57 ../
-rw-rw---- 1 999 999 56 Jul 10 07:22 auto.cnf
-rw-rw---- 1 999 999 12582912 Jul 10 07:22 ibdata1
-rw-rw---- 1 999 999 50331648 Jul 10 07:22 ib_logfile0
-rw-rw---- 1 999 999 50331648 Jul 10 07:21 ib_logfile1
drwx------ 2 999 999 4096 Jul 10 07:22 mysql/
drwx------ 2 999 999 4096 Jul 10 07:22 performance_schema/
drwx------ 2 999 999 20 Jul 10 07:26 rdb-test/
#查看存储池的空间
root@ceph-mon1:~# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 320 GiB 319 GiB 586 MiB 586 MiB 0.18
TOTAL 320 GiB 319 GiB 586 MiB 586 MiB 0.18
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 1.7 KiB 1 12 KiB 0 101 GiB
mypool 2 32 1.7 KiB 1 12 KiB 0 101 GiB
rdb-data1 3 32 136 MiB 63 409 MiB 0.13 101 GiB
2.3配置客户端普通用户挂载并使用RBD
#在ceph部署节点上操作
1、在ceph部署节点上创建普通用户
cephadmin@ceph-mon1:~/ceph-cluster$ ceph auth add client.wsq mon 'allow r' osd 'allow rwx pool=rbd-data1'
2、验证创建的用户信息
cephadmin@ceph-mon1:~/ceph-cluster$ ceph auth get client.wsq
[client.wsq]
key = AQB6t6xkNb7VExAAtjGG24ZolWJMsaI6BAyLjA==
caps mon = "allow r"
caps osd = "allow rwx pool=rbd-data1"
exported keyring for client.wsq
3、创建keyring文件
cephadmin@ceph-mon1:~/ceph-cluster$ sudo ceph-authtool --create-keyring ceph.client.wsq.keyring
4、导出用户的keyring文件
cephadmin@ceph-mon1:~/ceph-cluster$ ceph auth get client.wsq -o ceph.client.wsq.keyring
5、验证指定用户的keyring文件
cephadmin@ceph-mon1:~/ceph-cluster$ sudo cat ceph.client.wsq.keyring
[client.wsq]
key = AQB6t6xkNb7VExAAtjGG24ZolWJMsaI6BAyLjA==
caps mon = "allow r"
caps osd = "allow rwx pool=rbd-data1"
6、同步普通用户认证文件
cephadmin@ceph-mon1:~/ceph-cluster$ sudo scp ceph.conf ceph.client.wsq.keyring root@172.17.10.10:/etc/ceph
#在客户端上操作
7、在客户端验证权限
8、使用普通用户映射rbd镜像
rbd --user wsq -p rbd-data1 map data-img1
rbd --user wsq -p rbd-data1 map data-img2
9、验证映射结果
root@client:~# ceph --user wsq -s
cluster:
id: 772b2ec4-42f6-4bf6-b42e-763144796564
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon1,ceph-mon2,ceph-mon3 (age 2h)
mgr: ceph-mgr1(active, since 2h), standbys: ceph-mgr2
osd: 16 osds: 16 up (since 77m), 16 in (since 4d)
data:
pools: 1 pools, 64 pgs
objects: 62 objects, 153 MiB
usage: 645 MiB used, 319 GiB / 320 GiB avail
pgs: 64 active+clean
10、映射rbd
root@client:~# rbd --user wsq -p rbd-data1 map data-img1
root@client:~# rbd --user wsq -p rbd-data1 map data-img2
11、验证rbd是否映射成功
root@client:~# lsblk
12、格式化并挂载
root@client:~# mkfs.ext4 /dev/rbd0
root@client:~# mkfs.ext4 /dev/rbd1
root@client:~# mount /dev/rbd0 /data/data1
root@client:~# mount /dev/rbd1 /data/data2
13、验证ceph内核模块
root@client:~# apt -y install module-init-tools
root@client:~# lsmod |grep ceph
2.4RBD其他操作
2.4.1 rbd镜像的拉伸(镜像可以扩展但是不建议缩小空间)
cephadmin@ceph-mon1:~/ceph-cluster$ rbd ls -p rbd-data1 -l
NAME SIZE PARENT FMT PROT LOCK
data-img1 5 GiB 2
data-img2 10 GiB 2
cephadmin@ceph-mon1:~/ceph-cluster$ rbd resize --pool rbd-data1 --image data-img1 --size 10G
Resizing image: 100% complete...done.
cephadmin@ceph-mon1:~/ceph-cluster$ rbd ls -p rbd-data1 -l
NAME SIZE PARENT FMT PROT LOCK
data-img1 10 GiB 2
data-img2 10 GiB 2
2.4.2卸载rbd镜像
[root@ceph-client ceph]# umount /data
[root@ceph-client ceph]# rbd --user wsq -p rbd-data1 unmap data-img2
2.4.3删除rbd镜像(此方法镜像无法还原,生产中建议把镜像先移动回收站,后确定不用再删除)
cephadmin@ceph-mon1:~/ceph-cluster$ rbd rm --pool rbd-data1 --image data-img1
Removing image: 100% complete...done.
cephadmin@ceph-mon1:~/ceph-cluster$ rbd ls -p rbd-data1 -l
NAME SIZE PARENT FMT PROT LOCK
data-img2 10 GiB
2.4.4 rbd镜像回收站机制
删除的镜像数据无法恢复,但是还有另外一种方法可以先把镜像移动到回收站,后期确认删
除的时候再从回收站删除即可。文章来源:https://www.toymoban.com/news/detail-552337.html
cephadmin@ceph-mon1:~/ceph-cluster$ rbd ls -p rbd-data1 -l
NAME SIZE PARENT FMT PROT LOCK
data-img2 10 GiB 2
cephadmin@ceph-mon1:~/ceph-cluster$ rbd trash move --pool rbd-data1 --image data-img2
cephadmin@ceph-mon1:~/ceph-cluster$ rbd ls -p rbd-data1 -l
#查看回收站镜像
cephadmin@ceph-mon1:~/ceph-cluster$ rbd trash list --pool rbd-data1
197c760956e7 data-img2
#还原镜像
cephadmin@ceph-mon1:~/ceph-cluster$ rbd trash restore --pool rbd-data1 --image data-img2 --image-id 197c760956e7
cephadmin@ceph-mon1:~/ceph-cluster$ rbd ls -p rbd-data1 -l
NAME SIZE PARENT FMT PROT LOCK
data-img2 10 GiB 2
2.5 管理镜像快照
2.5.1 快照的相关命令
[ceph@ceph-deploy ceph-cluster]$ rbd help snap
snap create (snap add) #创建快照
snap limit clear #清除镜像的快照数量限制
snap limit set #设置一个镜像的快照上限
snap list (snap ls) #列出快照
snap protect #保护快照被删除
snap purge #删除所有未保护的快照
snap remove (snap rm) #删除一个快照
snap rename #重命名快照
snap rollback (snap revert) #还原快照
snap unprotect #允许一个快照被删除(取消快照保护)
2.5.3 创建并验证快照
#创建快照
cephadmin@ceph-mon1:~/ceph-cluster$ rbd snap create --pool rbd-data1 --image data-img2 --snap data-img2-snap
Creating snap: 100% complete...done.
#验证快照
cephadmin@ceph-mon1:~/ceph-cluster$ rbd snap list --pool rbd-data1 --image data-img2
SNAPID NAME SIZE PROTECTED TIMESTAMP
4 data-img2-snap 10 GiB Tue Jul 11 12:02:33 2023
#删除数据并还原快照
root@client:/data/data1# ll
total 28
drwxr-xr-x 3 root root 4096 Jul 11 04:00 ./
drwxr-xr-x 4 mysql mysql 4096 Jul 10 06:57 ../
drwx------ 2 root root 16384 Jul 11 03:58 lost+found/
-rw-r--r-- 1 root root 1774 Jul 11 04:00 passwd
root@client:/data/data1# rm -rf *
root@client:/data/data1# ll
total 8
drwxr-xr-x 2 root root 4096 Jul 11 04:04 ./
drwxr-xr-x 4 mysql mysql 4096 Jul 10 06:57 ../
#客户端卸载rbd
root@client:~# umount /data/data1
root@client:~# rbd unmap /dev/rbd0
#回滚快照
cephadmin@ceph-mon1:~/ceph-cluster$ rbd snap rollback --pool rbd-data1 --image data-img2 --snap data-img2-snap
Rolling back to snapshot: 100% complete...done.
#客户端重新映射rbd并挂载
root@client:~# rbd --user wsq -p rbd-data1 map data-img2
root@client:~# mount /dev/rbd0 /data/data1
root@client:~# ll /data/data1 #删除数据已恢复
total 28
drwxr-xr-x 3 root root 4096 Jul 11 04:00 ./
drwxr-xr-x 4 mysql mysql 4096 Jul 10 06:57 ../
drwx------ 2 root root 16384 Jul 11 03:58 lost+found/
-rw-r--r-- 1 root root 1774 Jul 11 04:00 passwd
2.5.4 限制快照的数量并删除快照
1、删除快照
root@ceph-mon1:~# rbd snap remove --pool rbd-data1 --image data-img2 --snap data-img2-snap
Removing snap: 100% complete...done.
root@ceph-mon1:~# rbd snap list --pool rbd-data1 --image data-img2
2、设置快照的数量
root@ceph-mon1:~# rbd snap limit set --pool rbd-data1 --image data-img2 --limit 30
root@ceph-mon1:~# rbd snap limit set --pool rbd-data1 --image data-img2 --limit 20
3、清除快照数量限制
root@ceph-mon1:~# rbd snap limit clear set --pool rbd-data1 --image data-img2
ap data-img2-snap
Removing snap: 100% complete…done.
root@ceph-mon1:~# rbd snap list --pool rbd-data1 --image data-img2
2、设置快照的数量
root@ceph-mon1:~# rbd snap limit set --pool rbd-data1 --image data-img2 --limit 30
root@ceph-mon1:~# rbd snap limit set --pool rbd-data1 --image data-img2 --limit 20
3、清除快照数量限制
root@ceph-mon1:~# rbd snap limit clear set --pool rbd-data1 --image data-img2文章来源地址https://www.toymoban.com/news/detail-552337.html
到了这里,关于ceph--RBD的使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!