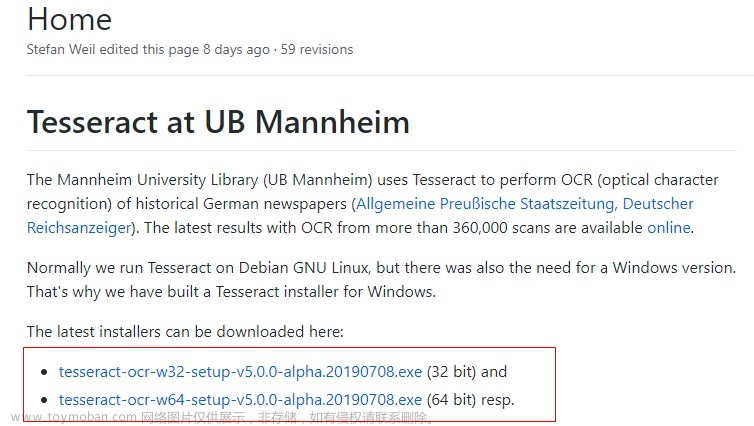
一、简介
PaddleOCR是飞浆开源文字识别模型,最新开源的超轻量PP-OCRv3模型大小仅为16.2M。同时支持中英文识别;支持倾斜、竖排等多种方向文字识别;支持GPU、CPU预测,并且支持使用paddle开源组件训练自己的超轻量模型,对于垂直领域的需求有很大帮助。
二、使用教程
- 环境安装
- 说明:官方推荐使用python3.7以上版本,但是在实际安装使用中发现python3.8更稳定,如果本地python安装包过多,推荐使用Anaconda来进行python包管理,避免包冲突。
- Anaconda下载:
地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
按需下载自己需要的版本
- 安装程序运行所需库
-
安装paddle
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple默认安装CPU版本,安装paddle时建议使用百度源,若需要安装GPU版本,则请打开paddle官网选择适合的版本.
paddle官网:https://www.paddlepaddle.org.cn/
由于安装GPU版本需要先配置好CUDA和cudnn,建议有一定基础后再安装GPU版本 -
安装paddlehub
pip install paddlehub -i https://mirror.baidu.com/pypi/simplepaddlehub介绍文档:https://github.com/PaddlePaddle/PaddleHub/blob/release/v2.1/README_ch.md
对于Windows环境用户:直接通过pip安装的shapely库可能出现 找不到指定模块的问题。建议从下方地址下载shapely安装包完成安装
https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely
-
安装ocr模型
hub install ch_pp-ocrv3==1.2.0模型名称 ch_pp-ocrv3 网络 Differentiable Binarization+SVTR_LCNet 数据集 icdar2015数据集 是否支持Fine-tuning 否 模型大小 13M 最新更新日期 2022-05-11 其它模型: chinese_ocr_db_crnn_server、PP-OCR、PP-OCRv2
三、模型调用
-
命令行预测示例
hub run ch_pp-ocrv3 --input_path "/PATH/TO/IMAGE" -
python代码示例
import paddlehub as hub import cv2 img_path = r'C:\Users\26414\Downloads\test.jpg' ocr = hub.Module(name="ch_pp-ocrv3", enable_mkldnn=True) # mkldnn加速仅在CPU下有效 result = ocr.recognize_text(images=[cv2.imread(img_path)]) # or 传递文件地址调用 # result = ocr.recognize_text(paths=[img_path])注: img_path路径中不能包含中文字符,opencv不支持中文路径
参数
- paths (list[str]): 图片的路径;
- images (list[numpy.ndarray]): 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
- use_gpu (bool): 是否使用 - GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
- box_thresh (float): 检测文本框置信度的阈值;
- text_thresh (float): 识别中文文本置信度的阈值;
- angle_classification_thresh(float): 文本角度分类置信度的阈值
- visualization (bool): 是否将识别结果保存为图片文件;
- output_dir (str): 图片的保存路径,默认设为 ocr_result;
- det_db_unclip_ratio: 设置检测框的大小;
返回
- res (list[dict]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
- data (list[dict]): 识别文本结果,列表中每一个元素为 dict,各字段为: - text(str): 识别得到的文本 - confidence(float): 识别文本结果置信度 - text_box_position(list): 文本框在原图中的像素坐标,4*2的矩阵,依次表示文本框左下、右下、右上、左上顶点的坐标 如果无识别结果则data为[]
- save_path (str, optional): 识别结果的保存路径,如不保存图片则save_path为’’
四、效果展示
-
测试图片

-
结果展示

注:
目前paddle ocr最高版本已更新只pp-ocr-v4,cpu环境下不推荐使用该版本,相比pp-ocr-v3效果虽然略有提升,但是速度要慢很多,且不支持cpu加速
参考文档
paddle ocr官方地址: https://www.paddlepaddle.org.cn/hubdetail?name=ch_pp-ocrv3&en_category=TextRecognition
paddle ocr GitHub地址: https://github.com/PaddlePaddle/PaddleHub
在线体验地址: https://www.paddlepaddle.org.cn/hub/scene/ocr文章来源:https://www.toymoban.com/news/detail-552581.html
查看其他开源中文OCR,点击此处
Docker中部署PaddleOCR,点击此处文章来源地址https://www.toymoban.com/news/detail-552581.html
到了这里,关于Paddle OCR 安装使用教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[软件工具]pdf多区域OCR识别导出excel工具使用教程](https://imgs.yssmx.com/Uploads/2024/01/800177-1.jpeg)