问题描述
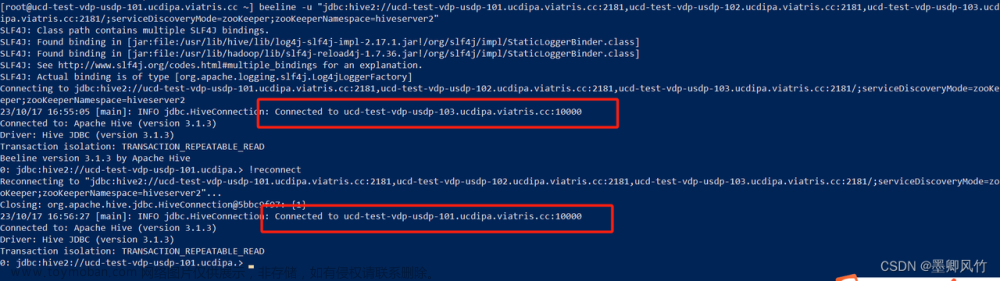
在IEDA连接虚拟机上的Hive报的
Exception in thread “main” org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:110)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:223)
at org.apache.spark.sql.internal.SharedState.externalCatalog
l
z
y
c
o
m
p
u
t
e
(
S
h
a
r
e
d
S
t
a
t
e
.
s
c
a
l
a
:
150
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
i
n
t
e
r
n
a
l
.
S
h
a
r
e
d
S
t
a
t
e
.
e
x
t
e
r
n
a
l
C
a
t
a
l
o
g
(
S
h
a
r
e
d
S
t
a
t
e
.
s
c
a
l
a
:
140
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
i
n
t
e
r
n
a
l
.
S
h
a
r
e
d
S
t
a
t
e
.
g
l
o
b
a
l
T
e
m
p
V
i
e
w
M
a
n
a
g
e
r
lzycompute(SharedState.scala:150) at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:140) at org.apache.spark.sql.internal.SharedState.globalTempViewManager
lzycompute(SharedState.scala:150)atorg.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:140)atorg.apache.spark.sql.internal.SharedState.globalTempViewManagerlzycompute(SharedState.scala:170)
at org.apache.spark.sql.internal.SharedState.globalTempViewManager(SharedState.scala:168)
at org.apache.spark.sql.hive.HiveSessionStateBuilder.
a
n
o
n
f
u
n
anonfun
anonfuncatalog
2
(
H
i
v
e
S
e
s
s
i
o
n
S
t
a
t
e
B
u
i
l
d
e
r
.
s
c
a
l
a
:
70
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
c
a
t
a
l
y
s
t
.
c
a
t
a
l
o
g
.
S
e
s
s
i
o
n
C
a
t
a
l
o
g
.
g
l
o
b
a
l
T
e
m
p
V
i
e
w
M
a
n
a
g
e
r
2(HiveSessionStateBuilder.scala:70) at org.apache.spark.sql.catalyst.catalog.SessionCatalog.globalTempViewManager
2(HiveSessionStateBuilder.scala:70)atorg.apache.spark.sql.catalyst.catalog.SessionCatalog.globalTempViewManagerlzycompute(SessionCatalog.scala:122)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.globalTempViewManager(SessionCatalog.scala:122)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.listTables(SessionCatalog.scala:1031)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.listTables(SessionCatalog.scala:1017)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.listTables(SessionCatalog.scala:1009)
at org.apache.spark.sql.execution.datasources.v2.V2SessionCatalog.listTables(V2SessionCatalog.scala:57)
at org.apache.spark.sql.execution.datasources.v2.ShowTablesExec.run(ShowTablesExec.scala:40)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result
l
z
y
c
o
m
p
u
t
e
(
V
2
C
o
m
m
a
n
d
E
x
e
c
.
s
c
a
l
a
:
43
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
d
a
t
a
s
o
u
r
c
e
s
.
v
2.
V
2
C
o
m
m
a
n
d
E
x
e
c
.
r
e
s
u
l
t
(
V
2
C
o
m
m
a
n
d
E
x
e
c
.
s
c
a
l
a
:
43
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
d
a
t
a
s
o
u
r
c
e
s
.
v
2.
V
2
C
o
m
m
a
n
d
E
x
e
c
.
e
x
e
c
u
t
e
C
o
l
l
e
c
t
(
V
2
C
o
m
m
a
n
d
E
x
e
c
.
s
c
a
l
a
:
49
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
Q
u
e
r
y
E
x
e
c
u
t
i
o
n
lzycompute(V2CommandExec.scala:43) at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:43) at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.executeCollect(V2CommandExec.scala:49) at org.apache.spark.sql.execution.QueryExecution
lzycompute(V2CommandExec.scala:43)atorg.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:43)atorg.apache.spark.sql.execution.datasources.v2.V2CommandExec.executeCollect(V2CommandExec.scala:49)atorg.apache.spark.sql.execution.QueryExecution
a
n
o
n
f
u
n
anonfun
anonfuneagerlyExecuteCommands
1.
1.
1.anonfun$applyOrElse
1
(
Q
u
e
r
y
E
x
e
c
u
t
i
o
n
.
s
c
a
l
a
:
98
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
S
Q
L
E
x
e
c
u
t
i
o
n
1(QueryExecution.scala:98) at org.apache.spark.sql.execution.SQLExecution
1(QueryExecution.scala:98)atorg.apache.spark.sql.execution.SQLExecution.
a
n
o
n
f
u
n
anonfun
anonfunwithNewExecutionId
6
(
S
Q
L
E
x
e
c
u
t
i
o
n
.
s
c
a
l
a
:
109
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
S
Q
L
E
x
e
c
u
t
i
o
n
6(SQLExecution.scala:109) at org.apache.spark.sql.execution.SQLExecution
6(SQLExecution.scala:109)atorg.apache.spark.sql.execution.SQLExecution.withSQLConfPropagated(SQLExecution.scala:169)
at org.apache.spark.sql.execution.SQLExecution
.
.
.anonfun$withNewExecutionId
1
(
S
Q
L
E
x
e
c
u
t
i
o
n
.
s
c
a
l
a
:
95
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
S
p
a
r
k
S
e
s
s
i
o
n
.
w
i
t
h
A
c
t
i
v
e
(
S
p
a
r
k
S
e
s
s
i
o
n
.
s
c
a
l
a
:
779
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
S
Q
L
E
x
e
c
u
t
i
o
n
1(SQLExecution.scala:95) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779) at org.apache.spark.sql.execution.SQLExecution
1(SQLExecution.scala:95)atorg.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)atorg.apache.spark.sql.execution.SQLExecution.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.execution.QueryExecutionKaTeX parse error: Can't use function '$' in math mode at position 8: anonfun$̲eagerlyExecuteC…anonfun$eagerlyExecuteCommands
1.
a
p
p
l
y
O
r
E
l
s
e
(
Q
u
e
r
y
E
x
e
c
u
t
i
o
n
.
s
c
a
l
a
:
94
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
c
a
t
a
l
y
s
t
.
t
r
e
e
s
.
T
r
e
e
N
o
d
e
.
1.applyOrElse(QueryExecution.scala:94) at org.apache.spark.sql.catalyst.trees.TreeNode.
1.applyOrElse(QueryExecution.scala:94)atorg.apache.spark.sql.catalyst.trees.TreeNode.anonfun$transformDownWithPruning
1
(
T
r
e
e
N
o
d
e
.
s
c
a
l
a
:
584
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
c
a
t
a
l
y
s
t
.
t
r
e
e
s
.
C
u
r
r
e
n
t
O
r
i
g
i
n
1(TreeNode.scala:584) at org.apache.spark.sql.catalyst.trees.CurrentOrigin
1(TreeNode.scala:584)atorg.apache.spark.sql.catalyst.trees.CurrentOrigin.withOrigin(TreeNode.scala:176)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:584)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org
a
p
a
c
h
e
apache
apachespark
s
q
l
sql
sqlcatalyst
p
l
a
n
s
plans
planslogical
A
n
a
l
y
s
i
s
H
e
l
p
e
r
AnalysisHelper
AnalysisHelper
s
u
p
e
r
super
supertransformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:267)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning
(
A
n
a
l
y
s
i
s
H
e
l
p
e
r
.
s
c
a
l
a
:
263
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
c
a
t
a
l
y
s
t
.
p
l
a
n
s
.
l
o
g
i
c
a
l
.
L
o
g
i
c
a
l
P
l
a
n
.
t
r
a
n
s
f
o
r
m
D
o
w
n
W
i
t
h
P
r
u
n
i
n
g
(
L
o
g
i
c
a
l
P
l
a
n
.
s
c
a
l
a
:
30
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
c
a
t
a
l
y
s
t
.
p
l
a
n
s
.
l
o
g
i
c
a
l
.
L
o
g
i
c
a
l
P
l
a
n
.
t
r
a
n
s
f
o
r
m
D
o
w
n
W
i
t
h
P
r
u
n
i
n
g
(
L
o
g
i
c
a
l
P
l
a
n
.
s
c
a
l
a
:
30
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
c
a
t
a
l
y
s
t
.
t
r
e
e
s
.
T
r
e
e
N
o
d
e
.
t
r
a
n
s
f
o
r
m
D
o
w
n
(
T
r
e
e
N
o
d
e
.
s
c
a
l
a
:
560
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
Q
u
e
r
y
E
x
e
c
u
t
i
o
n
.
e
a
g
e
r
l
y
E
x
e
c
u
t
e
C
o
m
m
a
n
d
s
(
Q
u
e
r
y
E
x
e
c
u
t
i
o
n
.
s
c
a
l
a
:
94
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
Q
u
e
r
y
E
x
e
c
u
t
i
o
n
.
c
o
m
m
a
n
d
E
x
e
c
u
t
e
d
(AnalysisHelper.scala:263) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:560) at org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:94) at org.apache.spark.sql.execution.QueryExecution.commandExecuted
(AnalysisHelper.scala:263)atorg.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)atorg.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)atorg.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:560)atorg.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:94)atorg.apache.spark.sql.execution.QueryExecution.commandExecutedlzycompute(QueryExecution.scala:81)
at org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:79)
at org.apache.spark.sql.Dataset.(Dataset.scala:220)
at org.apache.spark.sql.Dataset
.
.
.anonfun$ofRows
2
(
D
a
t
a
s
e
t
.
s
c
a
l
a
:
100
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
S
p
a
r
k
S
e
s
s
i
o
n
.
w
i
t
h
A
c
t
i
v
e
(
S
p
a
r
k
S
e
s
s
i
o
n
.
s
c
a
l
a
:
779
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
D
a
t
a
s
e
t
2(Dataset.scala:100) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779) at org.apache.spark.sql.Dataset
2(Dataset.scala:100)atorg.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)atorg.apache.spark.sql.Dataset.ofRows(Dataset.scala:97)
at org.apache.spark.sql.SparkSession.
a
n
o
n
f
u
n
anonfun
anonfunsql$1(SparkSession.scala:622)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:617)
at inputandoutput.Test05_Hive.main(Test05_Hive.java:27)
原因分析:
看报的异常是org.apache.hadoop.hive.ql.metadata.HiveException,说明是我Hive的metastore服务的问题,应该是启动,然后我又因为是在本机连接虚拟机中的Hive,所以应该还要开启Hiveserver2这个服务
解决方案:
开启metastore服务和Hiveserver2服务即可
开启脚本:文章来源:https://www.toymoban.com/news/detail-553141.html
vim hiveservices.sh
插入如下内容:文章来源地址https://www.toymoban.com/news/detail-553141.html
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
到了这里,关于常见的bug---3、没有启动metaStore和Hiveserver2服务导致在本机上的IDEA无法连接上虚拟机上的HIve的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!