一、scrapy介绍和快速使用
scrapy是python的爬虫框架,类似于django(python的web框架)。
安装:
- Mac、Linux
执行pip3 install scrapy,不存在任何问题 - Windows
执行pip3 install scrapy,如果安装失败,执行下面步骤:
(1)安装wheel(为支持通过文件安装软件):pip3 install wheel(wheel官网)
(2)安装lxml:pip3 install lxml
(3)安装pyopenssl:pip3 install pyopenssl
(4)下载并安装pywin32(pywin32官网 或 github地址)
(5)下载twisted的wheel文件(twisted官网),执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
(6)最后执行pip3 install scrapy
注:twisted是一个流行的事件驱动的python网络框架,性能很高的网络框架。
使用:
1 使用命令行创建scrapy项目
scrapy startproject 项目名
2 创建爬虫(相当于django创建app)
scrapy genspider 爬虫名 爬虫地址
3 运行爬虫
scrapy crawl 爬虫名
4 使用IDE打开爬虫项目(项目根目录)
5 目录结构
myfirst_crawl # 项目名
myfirst_crawl # 文件夹
-spiders # 文件夹(所有的爬虫都放在下面,一个py文件就是一个爬虫)
-cnblogs.py # 爬虫
middlewares.py # 以后中间件写在这里
pipelines.py # 以后存数据
settings.py # 配置文件
scrapy.cfg # 项目部署相关
items.py # 相当于models.py
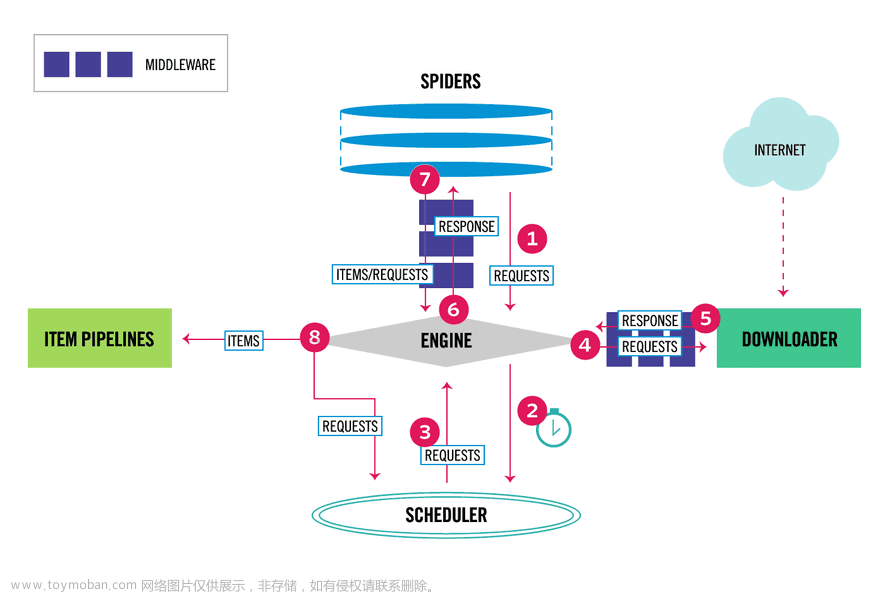
二、scrapy框架原理

五大组件
spider:爬虫,我们写代码的地方,爬取网址和解析数据
engine:引擎,大总管,掌管数据的流向(我们不管)
scheduler:调度器,负责调度哪个地址先爬取,哪个后爬取(深度优先,广度优先)
downloader:下载器,负责真正的下载(twisted,异步)
pipeline:管道,存储数据的地方(文件,mysql、redis…)
两大中间件
爬虫中间件:爬虫和引擎之间
下载中间件:引擎和下载器之间(用的多)
三、scrapy解析数据
1.执行命令
直接敲这个名令:scrapy gensipder 名字 地址,等同于新建一个py文件
执行爬虫,不打印日志:scrapy crawl cnblogs --nolog
使用脚本运行爬虫:
项目根目录下创建main.py
# 脚本执行爬虫,不用使用命令了
from scrapy.cmdline import execute
execute(['scrapy','crawl','cnblogs','--nolog'])
2.response对象的css方法和xpath方法
css中写css选择器,xpath中写xpath选择器
语法:
-xpath取文本内容
'.//a[contains(@class,"link-title")]/text()'
-xpath取属性
'.//a[contains(@class,"link-title")]/@href'
-css取文本
'a.link-title::text'
-css取属性
'img.image-scale::attr(src)'
两个方法:
.extract_first() # 取一个
.extract() # 取所有
spiders目录下爬虫文件参数:文章来源:https://www.toymoban.com/news/detail-553413.html
import scrapy
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs' # 爬虫名
allowed_domains = ['www.cnblogs.com'] # 允许爬取的域
start_urls = ['http://www.cnblogs.com/'] # 爬取的起始地址
def parse(self, response): # 响应对象response,从中解析出想要的数据
print('--------------',response)
print(response.text) # bs4解析
示例:
spiders目录下的cnblogs.py文件文章来源地址https://www.toymoban.com/news/detail-553413.html
import scrapy
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs' # 爬虫名
allowed_domains = ['www.cnblogs.com'] # 允许爬取的域
start_urls = ['http://www.cnblogs.com/'] # 爬取的起始地址
def parse(self, response): # 响应对象response,从中解析出想要的数据
# print('--------------',response)
# print(response.text) # bs4解析
############ css ###########
# article_list=response.css('.post-item') # 查出所有类名为post-item的标签,取多条
# # print(len(article_list))
# for article in article_list:
# title=article.css('div.post-item-text>a::text').extract_first() # 取一条
# # article.css('section>div>a::text')
# href=article.css('div.post-item-text>a::attr(href)').extract_first()
# author=article.css('a.post-item-author>span::text').extract_first()
# desc=article.css('p.post-item-summary::text').extract_first()
#
# # 取不到就是None
# photo=article.css('p.post-item-summary>a>img::attr(src)').extract_first()
#
#
# print(title)
# print(href)
# print(author)
# print(desc)
# print(photo)
# print('----------')
########### xpath ###########
article_list = response.xpath('//*[@class="post-item"]') # 查出所有类名为post-item的标签,取多条
# print(len(article_list))
for article in article_list:
# 注意:使用 . 从当前标签下找
title = article到了这里,关于爬虫框架scrapy基本原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!