目录
1.网页的组成
2.HTML
(1)标签
(2)比较重要且常用的标签:
①列表标签
②超链接标签 (a标签)
③img标签:用于渲染,图片资源的标签
④div标签和span标签
(3)属性
(4)常用的语义化标签
(5)元素的分类及特点
①块元素
②行内元素
③行内块元素
(6)文件路径
(7)HTML的基本结构
(8)节点树及节点间的关系
3.CSS
(1)引入css的方法
(2)选择器
(3)单位
(4)css三大特性
1.网页的组成
网页可分为三个部分——HTML、CSS和JavaScript。如果把网页比作一个人的话,HTML相当于骨架,JavaScript相当于肌肉,CSS相当于皮肤,三者结合起来才能形成一个完善的网页。
2.HTML
HTML是用来描述网页的一种语言,全称为超文本标记语言。网页包含文字、按钮、图片和视频等各种复杂的元素,其基础架构就是HTML。不同类型的文字通过不同类型的标签来表示 ,如图片用img标签表示,视频用video标签表示,段落用p 标签表示 ,他们之间的布局又常通过布局标签 div 嵌套组合而戚成,各种标签通过不同的排列和嵌套才形成了网页的框架。
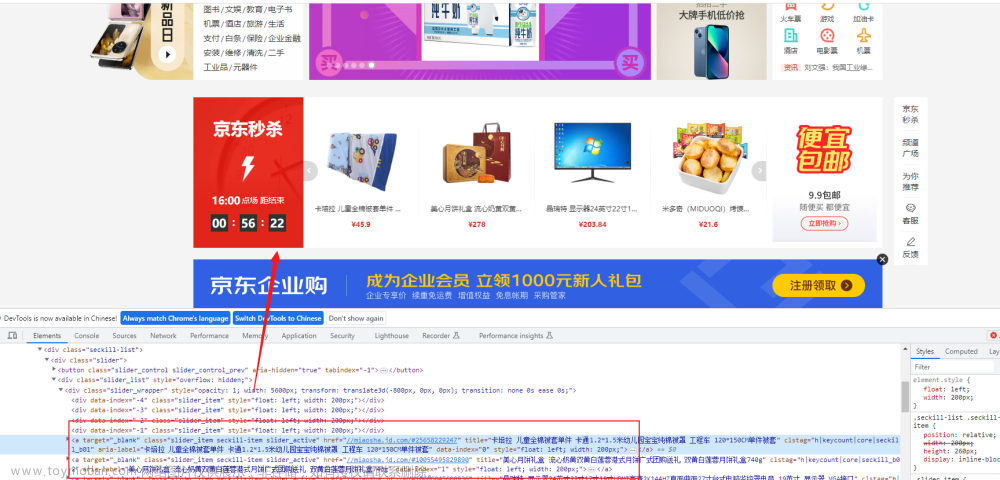
我们可以随意打开一个网站,比如京东首页,然后单击鼠标右键选择“检查元素”菜单或者按 F12,即可打开浏览器开发者工具,接着切换到 Elements 面板,这时候呈现的就是京东网首页对应的 HTML,它包含了一系列标签,浏览器解析这些标签后,便会在网页中将它们渲染成一个个节点,这便形成了我们平常看到的网页。
(1)标签
是由w3c提前制定好的一些针对于html文档的标记符号,这些符号是具备各自的含义的。具体在html中的变现形式 由 < > 括起来的对象 比如: html head body
需要注意的是:
①标签通常是成对出现的,但也有极少部分只有开始标签,没有结束标签 称作 单标签或者空标签 比如:meta
②标签是允许嵌套的,但是要符合嵌套的标准
通常,我们也会将标签称作为元素 ,例如:根元素 、head元素等
(2)比较重要且常用的标签:
①列表标签
1>有序列表,表示如下:
<ol>
<li></li>
<li></li>
<li></li>
</ol> 2>无序列表,表示如下:
<ul>
<li></li>
<li></li>
<li></li>
</ul> 3>定义列表,表示如下:
<dl>
<dt></dt>
<dd></dd>
<dt></dt>
<dd></dd>
</dl>注:列表之间是可以相互嵌套的
②超链接标签 (a标签)
1>可以访问到外部网络的资源
2>可以访问本地网页资源
3>可以作为锚点,在当前页面指定位置进行定位跳转
③img标签:用于渲染,图片资源的标签
④div标签和span标签
小tip:href和src的区别:
href和src都是指向外部资源地址或者本地资源地址
不同点:
href属性:
1>通过该属性去关联另一份外部资源文件
2>如果被关联的资源文件,在页面渲染时需要用到该资源中的内容时,它会下载该资源,
3>如果需要下载资源文件内容时,并行下载的方式,不会阻塞页面的渲染
src属性:
1>通过该属性去访问到对应的外部资源,并替换掉该标签的内容
2>src属性肯定是会下载对应路径的资源的
3>src的下载不是并行下载,在页面渲染时如果遇到src那么会将该资源全部下载完毕并且解析后,才会继续渲染页面后续的内容(src会阻塞页面的渲染)
(3)属性
通常格式:key=value(注:有时候只有key没有value,即表示逻辑值的时候)
①全局属性:全部元素都具备(例id,class,style等等)
②局部属性:只能某些元素使用
(4)常用的语义化标签
标题标签(h1-h6标签)、段落标签(p标签)、i/em标签(斜体)、b/strong标签(粗体)、blockquote/q标签(引用)等等。
(5)元素的分类及特点
①块元素
1>块元素具有布局特点,一般常用页面的整体布局
2>块元素独占(其父元素)页面的一行
3>块元素可以嵌套任何类型的元素(除p元素以外,p元素中不能嵌套任何的块元素)
4>块元素可以设置宽,高 默认的宽度是其父元素的宽度
5>块元素默认高度是由内容决定的
②行内元素
1>正常情况下,行内元素是不会换行的
2>行内元素会在一行排不下时进行换行
3>行内元素不能设置宽 高 行内元素的宽和高都是由其内容决定的
4>行内元素一般不会嵌套块级元素,大多数是嵌套文本或者其他的行内元素
③行内块元素
1.行内块元素不会独占一行,在一行排列
2.可以设置宽高(默认是内容的宽 高)
注:元素之间可以相互进行转换,使用diaplay:block(inline/inline-block);
(6)文件路径
①相对路径:与当前的文件是没有联系的,不是根据当前该文件所处的位置去访问对应的资源。
②绝对路径:从当前文件出发去寻找其他的资源,当前的位置为中心。
(7)HTML的基本结构
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>This is a Demo</title>
</head>
<body>
<div id="container">
<div class="wrapper">
<h2 class="titie">Hello Morld</h2>
<p class="text">Hello, this is a parpgtaph.</p>
</div>
</div>
</body>
</html>
(8)节点树及节点间的关系
在HTML中,所有标签定义的内容都是节点,这些节点构成一个 HTML节点树,也叫HTMLDOM树。
先来看一下什么是 DOM。DOM 是 W3C(万维网联盟)的标准,英文全称是 Document Object Model,即文档对象模型。它定义了访问 HTML 和 XML 文档的标准。根据 W3C 的HTMLDOM 标准,HTML 文档中的所有内容都是节点。
- 整个网站文档是一个文档节点。
- 每个 html 标签对应一个根节点,即上例中的 html 标签,它属于一个根节点。
- 节点内的文本是文本节点,比如 a 节点代表一个超链接,它内部的文本也被认为是一个文本节点。
- 每个节点的属性是属性节点,比如 a 节点有一个 href 属性,它就是一个属性节点。
- 注释是注释节点,在 HTML 中有特殊的语法会被解析为注释,它也会对应一个节点。
因此,HTML DOM 将 HTML 文档视作树结构,这种结构被称为节点树,如下图所示。可通过这棵树访问所有节点。可以修改或删除它们的内容,也可以创建新的元素。这颗节点树展示了节点的集合,以及它们之间的联系。这棵树从根节点开始,然后在树的最低层级向文本节点长出枝条:

节点树中的节点彼此之间都有层级关系。常用父节点、子节点和同级节点描述这种关系。父节点拥有子节点,位于相同层级上的子节点称为同级节点(兄弟或姐妹)。
- 在节点树中,顶端的节点称为根节点
- 根节点之外的每个节点都有一个父节点
- 节点可以有任何数量的子节点
- 叶子是没有子节点的节点
- 同级节点是拥有相同父节点的节点
下面的图片展示出节点树的一个部分,以及节点间的关系:

3.CSS
(1)引入css的方法
①行内样式:直接在标签内通过style=""设置。
②内联样式:在head标签里写style标签,在其编写样式即可。
③外联样式:通过link标签引入外部的css文件。
(2)选择器
①基础选择器:元素选择器、id选择器、类选择器、通配符选择器
②复合选择器:交集选择器、并集选择器
③关系选择器:子代选择器、后代选择器、兄弟选择器
④属性选择器:例:[tytle="name"]
⑤伪类选择器:
1>结构伪类( :first-of-type | :last-of-type | :nth-of-type() )
2>动态伪类( link | hover | active | visited )
⑥伪元素选择器( ::first-letter | ::first-line | ::selection | ::before | ::after )
(3)单位
①长度单位:px、em、rem、vh和vw
②比例单位:%
③颜色单位:颜色单词、RGB格式、RGBA格式、#十六进制
(4)css三大特性
①层叠性:当有多个相同选择器或者同类型的选择器选中同一个元素,并为其设置同一个样式属性的不同属性值,会优先使用靠近元素的选择器所设置的样式。
注意:当选择器权重(优先级)不同时,无法通过层叠性解决样式冲突
②优先级(权重)
通配符选择器<元素选择器<类/伪类选择器<id选择器<行内样式<!important(无限大)文章来源:https://www.toymoban.com/news/detail-553698.html
③继承性:子元素(后代元素)继承父元素(祖先元素)已经定义过的属性(即字体相关 、字体颜色、 列表相关的、文本相关的等)。
文章来源地址https://www.toymoban.com/news/detail-553698.html
到了这里,关于Python爬虫学习笔记(一)————网页基础的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2024/01/415693-1.png)







