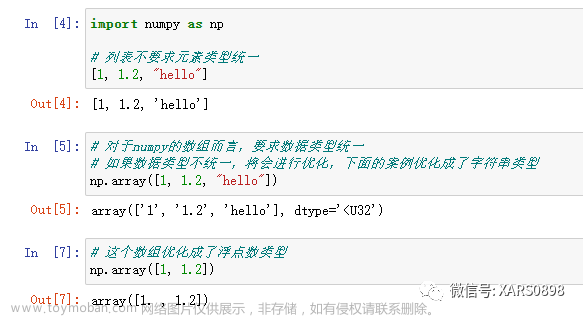
目录
一、NumPy数组操作
1. ndarray更改形状
2. ndarray转置
3. ndarray组合
4. ndarray拆分
5. ndarray排序
二、NumPy数组运算
1. 基本运算
2. 逻辑函数
3. 数学函数
三、日期时间的表示和间隔
1. 日期时间的表示——datetime64
2. 日期时间的计算——timedelta64
3. datetime64与datetime的转换
一、NumPy数组操作
1. ndarray更改形状
在对数组进行操作时,为了满足格式和计算的要求通常会改变其形状。
numpy.ndarray.shape 表示数组的维度,返回一个元组,这个元组的长度就是维度的数目,即 ndim属性(秩)。
shape:通过列表和元组重定义数组形状
import numpy as np
a1 = np.arange(12)
a1
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
a1.shape
# (12,)
a1.shape = [3, 4]
a1
# array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
a1.shape = (4, 3)
# array([[ 0, 1, 2],
# [ 3, 4, 5],
# [ 6, 7, 8],
# [ 9, 10, 11]])reshape:不改变原数组形状,返回一个临时数组
import numpy as np
a1 = np.arange(12)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
a1.shape = [3, 4]
# array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
a1.reshape(2, 2, 3)
# array([[[ 0, 1, 2],
# [ 3, 4, 5]],
#
# [[ 6, 7, 8],
# [ 9, 10, 11]]])
a1
# array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
# -1表示任意个元素,(2, -1)表示两行任意列
a1.reshape(2, -1)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]]
np.reshape(a1, [3, 2, 2])
# array([[[ 0, 1],
# [ 2, 3]],
#
# [[ 4, 5],
# [ 6, 7]],
#
# [[ 8, 9],
# [10, 11]]])
a1
# array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
resize:将数组转换成指定的形状,会直接修改数组本身,并且不会返回任何值
import numpy as np
a1 = np.arange(12)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
a1.shape = [3, 4]
# array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
a1.resize(2, 2, 3)
a1
# array([[[ 0, 1, 2],
# [ 3, 4, 5]],
#
# [[ 6, 7, 8],
# [ 9, 10, 11]]])
numpy.ndarray.flat 将数组转换为一维的迭代器,可以用for访问数组每一个元素。
import numpy as np
arr1 = np.arange(24).reshape(4, 6)
arr1
# array([[ 0, 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10, 11],
# [12, 13, 14, 15, 16, 17],
# [18, 19, 20, 21, 22, 23]])
arr2 = arr1.flat
arr2
# <numpy.flatiter at 0x1f6d67973f0>
for i in arr2:
print(i, end=' ')
# 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23numpy.ndarray.flatten([order='C']) 将数组的副本转换为一维数组,并返回, flatten()函数返回
的是拷贝。
import numpy as np
arr1 = np.arange(24).reshape(4, 6)
arr1
# array([[ 0, 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10, 11],
# [12, 13, 14, 15, 16, 17],
# [18, 19, 20, 21, 22, 23]])
arr2 = arr1.flatten()
arr2
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23])
arr2[2] = 0
arr1
# array([[ 0, 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10, 11],
# [12, 13, 14, 15, 16, 17],
# [18, 19, 20, 21, 22, 23]])
2. ndarray转置
numpy.transpose()、numpy.ndarray.T ,对换数组的维度,numpy.ndarray.T相当于numpy.transpose在二维矩阵情况下的一种简便表达。
import numpy as np
arr = np.random.randint(0, 10, size=(3, 4))
print(arr)
# [[8 7 7 7]
# [7 1 9 1]
# [4 1 4 1]]
print(arr.T)
# [[8 7 4]
# [7 1 1]
# [7 9 4]
# [7 1 1]]
print(arr)
# [[8 7 7 7]
# [7 1 9 1]
# [4 1 4 1]]
print(np.transpose(arr))
# [[2 9 1]
# [7 0 0]
# [0 2 7]
# [2 6 6]]
print(arr)
# [[8 7 7 7]
# [7 1 9 1]
# [4 1 4 1]]3. ndarray组合
在数据分析中,数组组合应该是最常见的操作。数组组合的方式大致可分为两种:一种是沿现有轴(维度)组合数组;另一种是沿新轴(新的维度)组合数组。
- numpy.concatenate((a1, a2, ...), axis=0, out=None) :沿现有轴连接一系列数组。
- numpy.stack(arrays, axis=0, out=None):沿新轴连接一系列数组。
- numpy.vstack(tup):水平(按列)顺序堆叠数组
- numpy.hstack(tup):垂直(行)按顺序堆叠数组
import numpy as np
a1 = np.arange(12).reshape(3, 4)
a2 = np.arange(12, 24).reshape(3, 4)
# numpy.concatenate([a1, a2, ...], axis=0, out=None) 沿现有轴连接一系列数组
a3 = np.concatenate([a1, a2])
print(a3)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]
# [12 13 14 15]
# [16 17 18 19]
# [20 21 22 23]]
a4 = np.concatenate([a1, a2], axis=1) # axis默认为0
print(a4)
# [[ 0 1 2 3 12 13 14 15]
# [ 4 5 6 7 16 17 18 19]
# [ 8 9 10 11 20 21 22 23]]
# numpy.stack(arrays, axis=0, out=None) 沿新轴连接一系列数组,stack为增加维度的拼接
a5 = np.stack([a1, a2])
print(a5)
# [[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
#
# [[12 13 14 15]
# [16 17 18 19]
# [20 21 22 23]]]
a6 = np.stack([a1, a2], axis=1)
print(a6)
# [[[ 0 1 2 3]
# [12 13 14 15]]
#
# [[ 4 5 6 7]
# [16 17 18 19]]
#
# [[ 8 9 10 11]
# [20 21 22 23]]]
a7 = np.stack([a1, a2], axis=2)
print(a7)
# [[[ 0 12]
# [ 1 13]
# [ 2 14]
# [ 3 15]]
#
# [[ 4 16]
# [ 5 17]
# [ 6 18]
# [ 7 19]]
#
# [[ 8 20]
# [ 9 21]
# [10 22]
# [11 23]]]
# hstack(), vstack() 分别表示水平和竖直的拼接方式。在数据维度等于1时,比较特殊。
# 而当维度大于或等于2时,它们的作用相当于 concatenate ,用于在已有轴上进行操作。
a8 = np.hstack([a1, a2])
print(a8)
# [[ 0 1 2 3 12 13 14 15]
# [ 4 5 6 7 16 17 18 19]
# [ 8 9 10 11 20 21 22 23]]
a9 = np.vstack([a1, a2])
print(a9)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]
# [12 13 14 15]
# [16 17 18 19]
# [20 21 22 23]]
a0 = np.arange(5)
# [0 1 2 3 4]
a10 = np.hstack([a0, a0])
print(a10)
# [0 1 2 3 4 0 1 2 3 4]
a11 = np.vstack([a0, a0])
print(a11)
# [[0 1 2 3 4]
# [0 1 2 3 4]]4. ndarray拆分
numpy.split(ary, indices_or_sections, axis) 沿特定的轴将数组分割为子数组
- ary:要切分的数组。
- indices_or_sections:如果是一个整数,就用该数平均切分,如果是一个数组,为沿轴切分的位置(左开右闭)。
- axis:沿着哪个维度进行切分,默认为0,横向切分。为1时,纵向切分。
import numpy as np
a1 = np.arange(9)
# 一维数组
a2 = np.split(a1, 3) # 平均切分,注意整除
print(a2)
# [array([0, 1, 2]), array([3, 4, 5]), array([6, 7, 8])]
a3 = np.split(a1, [3, 8])
print(a3)
# [array([0, 1, 2]), array([3, 4, 5, 6, 7]), array([8])]
# 二维数组
a1 = np.arange(12).reshape(3, 4)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
a2 = np.split(a1, 3)
print(a2)
# [array([[0, 1, 2, 3]]),
# array([[4, 5, 6, 7]]),
# array([[8, 9, 10, 11]])]
a3 = np.split(a1, [1, 3])
print(a3)
# [array([[0, 1, 2, 3]]),
# array([[4, 5, 6, 7],
# [8, 9, 10, 11]]),
# array([], shape=(0, 4), dtype=int32)]
a4 = np.split(a1, [1, 3], axis=1)
print(a4)
# [array([[0], [4], [8]]),
# array([[1, 2], [5, 6], [9, 10]]),
# array([[3], [7], [11]])]5. ndarray排序
numpy.sort() 指定轴进行排序。默认是使用数组的最后一个轴进行排序。
ndarray.sort() 这个方法会直接影响到原来的数组,而不是返回一个新的排序后的数组。
import numpy as np
a1 = np.random.randint(0, 12, size=(3, 4))
print(a1)
# [[ 3 8 1 7]
# [ 0 4 10 3]
# [10 5 8 11]]
# numpy.sort 指定轴排序,不改变原数组
print(np.sort(a1)) # 默认axis=1, 行排序
# [[ 1 3 7 8]
# [ 0 3 4 10]
# [ 5 8 10 11]]
print(np.sort(a1, axis=0)) # 指定axis=0, 列排序
# [[ 0 4 1 3]
# [ 3 5 8 7]
# [10 8 10 11]]
print(-np.sort(-a1)) # 降序排序
# [[ 8 7 3 1]
# [10 4 3 0]
# [11 10 8 5]]
# ndarray.sort 直接修改原数组
a1.sort()
print(a1)
# [[ 1 3 7 8]
# [ 0 3 4 10]
# [ 5 8 10 11]]
a1.sort(axis=0)
print(a1)
# [[ 0 3 4 8]
# [ 1 3 7 10]
# [ 5 8 10 11]]
# numpy.argsort 返回排序后的下标值二、NumPy数组运算
1. 基本运算
- Numpy数组不需要写循环即可对数据执行批量运算
- NumPy用户称其为矢量化(vectorization)
大小相等的数组之间的任何算术运算都会将运算应用到元素级:
import numpy as np
arr1 = np.array([[1, 2, 3], [4, 5, 6]])
arr2 = np.array([[2, 4, 6], [1, 3, 5]])
print(arr1 + arr2)
# [[ 3 6 9]
# [ 5 8 11]]
print(arr1 - arr2)
# [[-1 -2 -3]
# [ 3 2 1]]
print(arr1 * arr2)
# [[ 2 8 18]
# [ 4 15 30]]
print(arr1 / arr2)
# [[0.5 0.5 0.5]
# [4. 1.66667 1.2]]
print(arr1 ** 2)
# [[ 1 4 9]
# [16 25 36]]2. 逻辑函数
- numpy.all() 函数用于判断整个数组中的元素的值是否全部满足条件,如果满足条件返回True,否则返回False。
- numpy.any() 相当于或(or)操作,任意一个元素为True,输出为True
- numpy.isnan() 函数用于判断数据是否为 NaN
- numpy.isinf() 函数用于判断数据是否为 inf
import numpy as np
arr1 = np.arange(5)
arr2 = np.copy(arr1)
# [0 1 2 3 4]
print(np.all(arr1 == 0)) # False
print(np.all(arr1 == arr2)) # True
arr1[1] = 0
print(arr1 == arr2) # [True False True True True]
print(np.all(arr1 == arr2)) # False
print(np.any(arr1 == arr2)) # True
print(np.any(arr1 == 0)) # True
print(np.any(arr1 == 10)) # False3. 数学函数
| 函数名 | 含义 | 示例 | 结果 |
| numpy.add | 加 | np.add(np.array([1, 2, 3,4]), 1) | array([2, 3, 4, 5]) |
| numpy.subtract | 减 | np.subtract(np.array([1, 2, 3, 4]), 1) | array([0, 1, 2, 3]) |
| numpy.multiply | 乘 | np.multiply(np.array([1, 2, 3, 4]), 2) | array([2, 4, 6, 8]) |
| numpy.divide | 除 | np.divide(np.array([1, 2, 3, 4]), 2) | array([0.5, 1. , 1.5, 2.]) |
| numpy.power | power(x, y) 计算 x 的 y 次方 |
np.power(2, 3) | 8 |
| numpy.sqrt | 计算各元素的平 方根 |
np.sqrt([1, 4, 9]) | array([1., 2., 3.]) |
| numpy.square | 计算各元素的平 方 |
np.square([1, 2, 3]) | array([1, 4, 9]) |
| numpy.sum | 各元素求和 | np.sum(np.array([1, 2, 3])) | 6 |
| numpy.cumsum | 各元素累加和 | np.cumsum(np.array([1, 2, 3])) | array([1, 3, 6]) |
| numpy.prod | 各元素的乘积 | np.prod(np.array([1, 2, 3, 4])) | 24 |
| numpy.cumprod | 各元素累积乘积 | np.prod(np.array([1, 2, 3, 4])) | array([ 1, 2, 6, 24]) |
| numpy.min | 最小的元素 | np.min(np.array([1, 2, 3, 4])) | 1 |
| numpy.max | 最大的元素 | np.max(np.array([1, 2, 3, 4])) | 4 |
| numpy.mean | 元素的均值 | np.mean(np.array([1, 2, 3, 4])) | 2.5 |
| numpy.around | 四舍五入 可指定精度 |
np.around(np.array([1.2, 2.6, 3.1, 4.7])) | array([1., 3., 3., 5.]) |
| numpy.ceil | 向上取整 | np.ceil(np.array([-2.1, -1.7,1.2, 2.6, 3.1])) | array([-2., -1., 2., 3., 4.]) |
| numpy.floor | 向下取整 | np.floor(np.array([-2.1, -1.7, 1.2, 2.6, 3.1])) | array([-3., -2., 1., 2., 3.]) |
| numpy.exp | 返回e的幂次方 | np.exp(np.array([1, 2])) | array([2.718, 7.389]) |
| numpy.log | 自然对数 以e为底 |
np.log(np.e) | 1.0 |
三、日期时间的表示和间隔
在 Numpy中,我们可以很方便的将字符串转换成时间日期类型datetime64(datetime已被Python 包含的日期时间库所占用)。
| 日期单位 | 代码含义 | 时间单位 | 代码含义 |
| Y | 年 | h | 小时 |
| M | 月 | m | 分钟 |
| W | 周 | s | 秒 |
| D | 天 | ms | 毫秒 |
1. 日期时间的表示——datetime64
字符串转时间类型时,NumPy会根据字符串自动选择对应的单位,也可以强制指定使用单位。
import numpy as np
dt1 = np.datetime64('2023-06-01')
print(dt1, dt1.dtype) # 2023-06-01 datetime64[D]
dt2 = np.datetime64('2023-06')
print(dt2, dt2.dtype) # 2023-06 datetime64[M]
dt3 = np.datetime64('2023-06-01 10')
print(dt3, dt3.dtype) # 2023-06-01T10 datetime64[h]
dt4 = np.datetime64('2023-06-01 10:30:59')
print(dt4, dt4.dtype) # 2023-06-01T10:30:59 datetime64[s]
dt5 = np.datetime64('2023', 'D')
print(dt5, dt5.dtype) # 2023-01-01 datetime64[D]
dt6 = np.datetime64('2023-01-01 23:00:00', 'h')
print(dt6, dt6.dtype) # 2023-01-01T23 datetime64[h]
dt_lst = np.array(['2023-06', '2022-10-20', '2021', '2023-03-10 17:50:20'], dtype='datetime64')
print(dt_lst, dt_lst.dtype)
# ['2023-06-01T00:00:00' '2022-10-20T00:00:00' '2021-01-01T00:00:00' '2023-03-10T17:50:20'] datetime64[s]2. 日期时间的计算——timedelta64
timedelta64 表示两个 datetime64 之间的差。文章来源:https://www.toymoban.com/news/detail-553952.html
相减后timedelta64的单位与两个 datetime64 中的较小的单位保持一致。文章来源地址https://www.toymoban.com/news/detail-553952.html
import numpy as np
dt1 = np.datetime64('2023-01-01')
dt2 = dt1 - np.datetime64('2022-01-01')
dt3 = dt1 - np.datetime64('2022-12-01 12')
dt4 = dt1 - np.datetime64('2021-06')
print(f"{dt2}, {dt3}, {dt4}")
# 365 days, 732 hours, 579 days
# 不支持 M 和 Y 的运算
dt5 = dt1 + np.timedelta64(10, 'D')
dt6 = dt1 + np.timedelta64(10, 'h')
dt7 = dt1 - np.timedelta64(10, 'm')
dt8 = dt1 - np.timedelta64(10, 's')
print(f"{dt5}, {dt6}, {dt7}, {dt8}")
# 2023-01-11, 2023-01-01T10, 2022-12-31T23:50, 2022-12-31T23:59:503. datetime64与datetime的转换
import numpy as np
import datetime
dt1 = datetime.datetime(year=2022, month=10, day=1, hour=10, minute=30, second=30)
dt64 = np.datetime64(dt1, 's')
print(dt64, dt64.dtype)
# 2022-10-01T10:30:30 datetime64[s]
dt2 = dt64.astype(datetime.datetime)
print(dt2, type(dt2))
# 2022-10-01 10:30:30 <class 'datetime.datetime'>到了这里,关于【Python爬虫与数据分析】NumPy进阶——数组操作与运算的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[数据分析大全]基于Python的数据分析大全——Numpy基础](https://imgs.yssmx.com/Uploads/2024/02/627794-1.png)