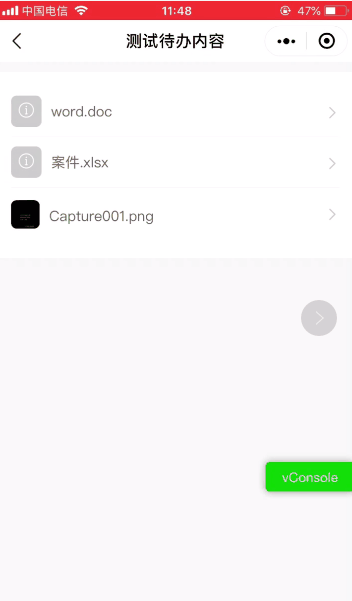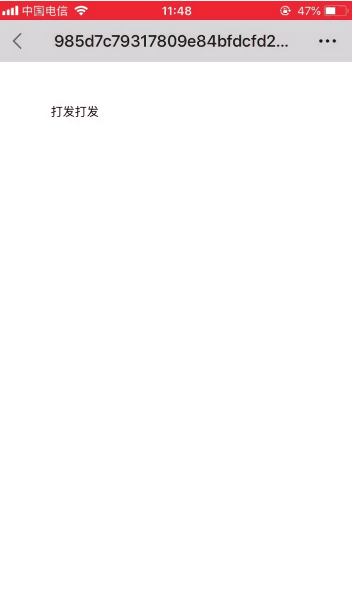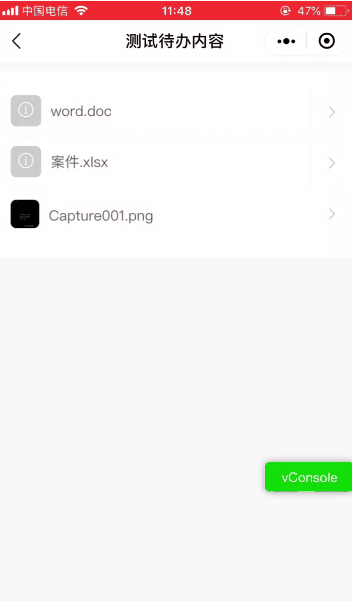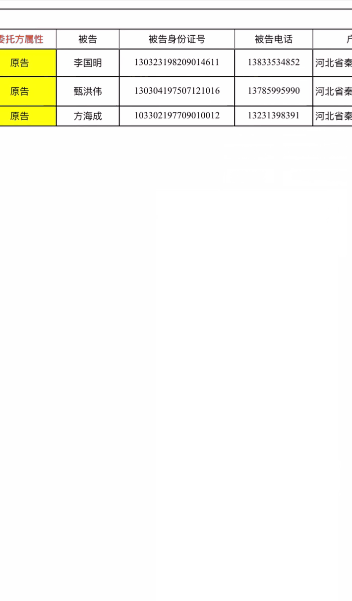
最近想爬取一些excel和word文件中的数据,于是记录下来,方便自己后面复杂粘贴,xls、xlsx、docx文件还是能处理的,但是doc文件处理不了
-
使用cmd文章来源:https://www.toymoban.com/news/detail-554837.html
#创建npm项目 npm init #安装所需包 npm install request --save npm install node-xlsx --save npm install adm-zip --save -
在入口文件文章来源地址https://www.toymoban.com/news/detail-554837.html
const xlsx = require('node-xlsx'); const fs = require('fs'); const path = require('path'); const AdmZip = require('adm-zip'); var request = require("request"); let url = "https://xxxx.cn/442054773520384.xls"; //创建跟该文件同级的data目路 const dataPath = path.resolve("./data"); getFlag(url).then(res => { console.log("res==" + res); }); function getFlag(url) { return new Promise(resolve => { //下载文件 getFileByUrl(url).then(filename => { //处理文件 handleDocxFile(filename); handleExcelFile(filename); resolve(1); }, () => { resolve(2); }).catch((err) => { console.error(err); resolve(3); }); }) } /** * 下载文件 * @param {*} url 网络文件url地址 */ function getFileByUrl(url) { return new Promise((resolve, reject) => { //添加文件名和后缀--start let fileName = "file" + new Date().getTime(); if (url.indexOf(".docx") > -1) fileName += ".docx"; else if (url.indexOf(".xls") > -1) fileName += ".xls"; else if (url.indexOf(".xlsx") > -1) fileName += ".xlsx"; else reject(); console.log(fileName); //添加文件名和后缀--end //保存文件--start let stream = fs.createWriteStream(path.join(dataPath, fileName)); request(url).pipe(stream).on("close", function (err) { if (err) { reject(); } console.log("文件" + fileName + "下载完毕"); resolve(fileName); }); //保存文件--end }) } /** * 处理word文件 * @param {文件名} filename */ function handleDocxFile(filename) { if (filename.indexOf(".docx") != -1) { const filePath = path.join(dataPath, filename); const zip = new AdmZip(filePath); //filePath为文件路径 const str = zip.readAsText("word/document.xml");//将document.xml读取为text内容; //处理该内容 console.log(str); //删除文件 fs.unlink(filePath, err => { if (err) console.log("删除失败"); else console.log("删除成功"); }); } } /** * 处理Excel文件 * @param {文件名} filename */ function handleExcelFile(filename) { if (filename.indexOf(".xls") != -1 || filename.indexOf(".xlsx") != -1) { const filePath = path.join(dataPath, filename); const sheets = xlsx.parse(filePath); //循环工作表 for (let i = 0; i < sheets.length; i++) { let len = sheets[i].data.length; //循环获取每一行 for (let j = 0; j < len; j++) { let row = sheets[i].data[j]; //循环获取每个单元格 for (let k = 0; k < row.length; k++) { let cell = row[k]; //处理 console.log(cell); } } } //删除该文件 fs.unlink(filePath, err => { if (err) console.log("删除失败"); else console.log("删除成功"); }); } }
到了这里,关于node简单处理xls、xlsx、docx文件的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!