Valley: Video Assistant with Large Language model Enhanced abilitY

大家好,我是卷了又没卷,薛定谔的卷的AI算法工程师「陈城南」~ 担任某大厂的算法工程师,带来最新的前沿AI知识和工具,包括AI相关技术、ChatGPT、AI绘图等, 欢迎大家交流~。
近期基于LLaMA微调的模型有很多,Alpaca,Vicuna都是基于ChatGPT等数据进行文本场景指令微调,LLaVA也使用图文对数据进行了图文场景多模态能力的扩展(这几个模型往期文章都有涉及,不清楚/感兴趣的可以看)。
而本文提到的Valley则是字节发布的视频场景多模态指令微调LLaMA模型。
其中这几个指令微调版本的模型都大差不差,主要还是数据与训练的差异。本文描述Valley当然对标的是其类似模型LLaVA,原文introduction部分翻译修改后如下:
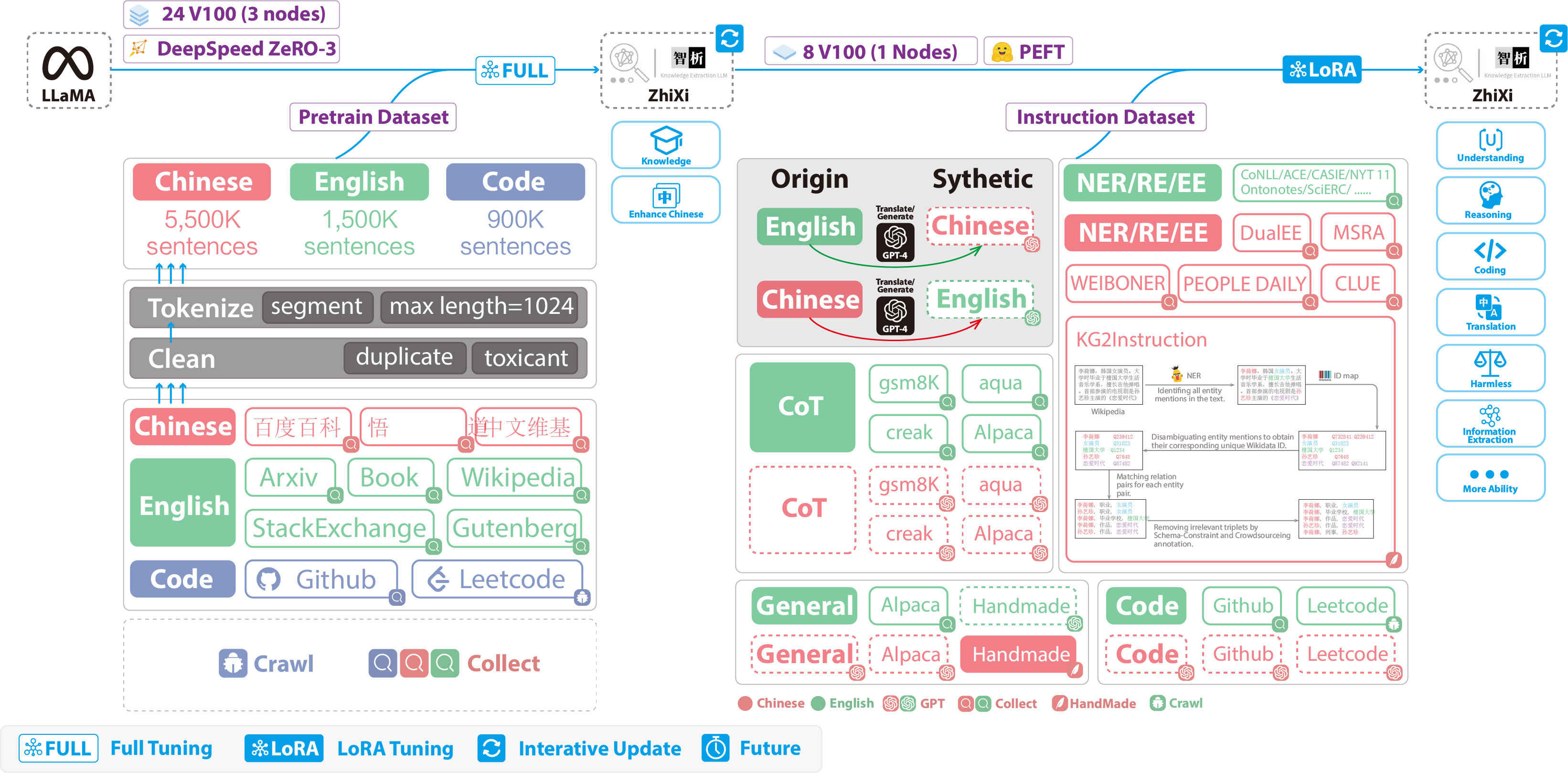
在Valley中,我们遵循 LLaVA 的先预训练然后指令调整的流程,采用一个简单的投影模块作为视频、图像和语言模式之间的桥梁。 我们采用 CLIP (Radford et al., 2021) 的 ViT-L/14 (Dosovitskiy et al., 2021) 作为视觉编码器(与LLaVA一致),然后提出一种时空池化操作来统一视频和图像输入的视觉编码(模型差异点)。 通过更新投影模块进行预训练,以使统一的视觉嵌入与 LLM 保持一致,其中 Stable-Vicuna (Chiang et al., 2023) 由于其多语言能力而成为选择的 LLM。 此外,我们引入了从各种视频任务中收集的多模态指令跟踪数据集,包括视频问答、长描述、随意关系推理和动作识别。 经过指令微调,最终提出了我们的视频理解谷多模态基础模型。 作为人工智能助手,我们预计Valley将在各种视频相关任务中得到广泛的应用,并帮助用户以类似于在现实世界中与人聊天的方式更好地理解和解释复杂的视频。
结合论文内容,我对Valley的贡献作了概括:
- 模型:基于LLaVA的方法,添加了时空池化模块应对视频(多帧)场景,将LLaVA从单图扩展为多图(动态长度),同时将LLaVA的Vicuna语言模型换为Stable-Vicuna模型。;
- 数据:搞了多模态的instruction-following数据集,聚焦于视频理解、比较多样的任务(包括multi-short captions,带时间戳的时间性描述、长视频的复杂陈述。同时使用了ChatGPT生成对话人和视频内容的对话,进一步增强数据集的质量和多样性。
- 开源:LLM时代,开源也是贡献~
Related Work
感兴趣的可以通过 相关工作来了解一下LLM的现状,以下为部分机翻:
现有的方法可以分为两种技术路线,一种是利用LLM作为调度器来调度现有的多模态模型,另一种是基于LLM来训练多模态模型。 前者在接收到用户指令和各个基础模型的功能后,将LLM作为控制器逐步调用相应的模型,并整合各个模型的输出内容生成结果(Wu等,2023;Shen等,2023)。 ,2023;Yang 等人,2023)。 例如,HuggingGPT(Shen et al., 2023)利用ChatGPT根据其功能描述在Hugging Face1中选择合适的模型并总结其执行结果。 后者为法学硕士配备辅助模块,帮助他们通过端到端训练理解多模态内容(Li et al., 2023c; Zhu et al., 2023; Zhu et al., 2023; Zhu et al., 2023; Liu et al., 2023; Su 等人,2023;戴等人,2023)。 例如,LLaVA (Liu et al., 2023) 和 MiniGPT-4 (Zhu et al., 2023) 通过投影层将 LLaMA (Touvron et al., 2023) 与视觉编码器连接起来,赋予其理解图像的能力 。 Video-LLaMA (Zhang et al., 2023) 通过 Q-Former 为 LLaMA (Touvron et al., 2023) 提供视觉和音频信息,赋予其基于视频的对话能力。
方法部分
网络结构

在LLaVA(如上图)基础上进行了扩展,将其单图扩展为多图(视频),如下图:

多帧的处理通过时空池化模块,具体:
- 有T个图,每个图的特征为 Vcls + 256 个patch token;

- 在patch token上做时间维度的平均,即T个图平均,则剩余特征为 T个Vcls + 256个平均后的patch token,下图为patch token的平均;

- 因为patch token的时间平均会损失时间信息(保留空间信息),所以将Vcls token 拼接在patch token后面,最终得到 T+256个视觉Token的输入,下图的V平均就是patch token;

空间tokens:256 patch(平均),时序tokens:T个CLS Token;这两个Token最终会经过映射层(Projection)与Text tokens衔接在一起送给大模型;
指令微调数据收集
作者基于MSRVTT(10k)、VATEX(22k)、AativityNet(10k)、VIOLIN(5.8k)共多个数据集构建了视频中心多模态指令数据,包含3种上下文类型,这些对应的问答对生成通过stable-vicuna生成,如下图

参考LLaVA和VideoChat中生成Prompt的方式,作者也用了上面的3种上下文文本和Stable-Vicuna生成了指令微调数据,如下图。累积42k对话和5.8k的问答对,其中对话数据涵盖基础视频内容描述(目标信息等)、时间内容理解。问答数据包含因果推理、字符识别和视频复杂内容理解。

训练
同LLaVA类似的两阶段训练方式,第一阶段通过预训练映射层来进行特征对齐;第二阶段再微调语言模型和映射层;
映射层预训练
使用图文对、视频文本对两种数据进行预训练,其中图文对为LLaVA的595k CC3M数据,视频文本对为参考LLaVA过滤方法进行过滤的 702K WebVid2M 数据。两种类型数据的Prompt组织方式一致,均为:

如果输入单个图像,则帧数为1。图像-文本对和视频-文本对构建为单轮对话,使用各种问题询问视频内容,并使用相应的标题进行回答。
微调
不止上面提到的42k对话和5.8k的问答对,为了增强对视觉内容的强调,还从LLaVA中收集了150k的图片指令数据、以及VideoChat收集的11k视频指令。
实验部分
没有什么指标,给了几个case大家感受下性能就行



Limitation
-
加入音频信息,构建 音、画、文三种模态可感知的多模态模型;
-
提供中文感知能力,构建更多的中文多模态数据来增强模型;文章来源:https://www.toymoban.com/news/detail-554976.html
-
存在LLM固有的幻觉问题(hallucination problem)需要解决。幻觉问题指大模型的输出是错误的、无意义的、输出与输入是明显不符合的(比如在摘要生成任务上)等情况,详细可参考:文章来源地址https://www.toymoban.com/news/detail-554976.html
- GPT-4的“hallucination”(幻觉)相关对策
- 对话大模型中的事实错误:ChatGPT 的缺陷文本任务_问题
- Survey of Hallucination in Natural Language Generation arXiv:2202.03629v5
到了这里,关于LLaMA模型指令微调 字节跳动多模态视频大模型 Valley 论文详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!