def excute(model_name,file_path,start_time):
model = whisper.load_model(model_name)
result = model.transcribe(file_path)
for segment in result["segments"]:
now = arrow.get(start_time)
start = now.shift(seconds=segment["start"]).format("YYYY-MM-DD HH:mm:ss")
end = now.shift(seconds=segment["end"]).format("YYYY-MM-DD HH:mm:ss")
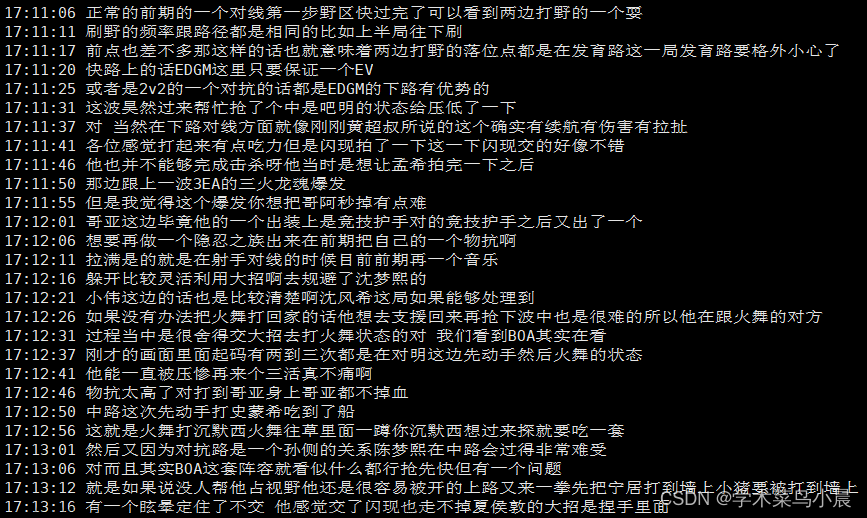
print("【"+start+"->" +end+"】:"+segment["text"])
# excute函数中,第一个参数是whisper模型,第二参数是视频地址,第三个参数是开始时间
if __name__ == '__main__':
excute("small","C:/Users/hp/Desktop/音频测试/1.mp4","2023-4-24 21:20:00")
whisper模型文章来源:https://www.toymoban.com/news/detail-556411.html
 文章来源地址https://www.toymoban.com/news/detail-556411.html
文章来源地址https://www.toymoban.com/news/detail-556411.html
到了这里,关于whisper生成字幕python代码实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!