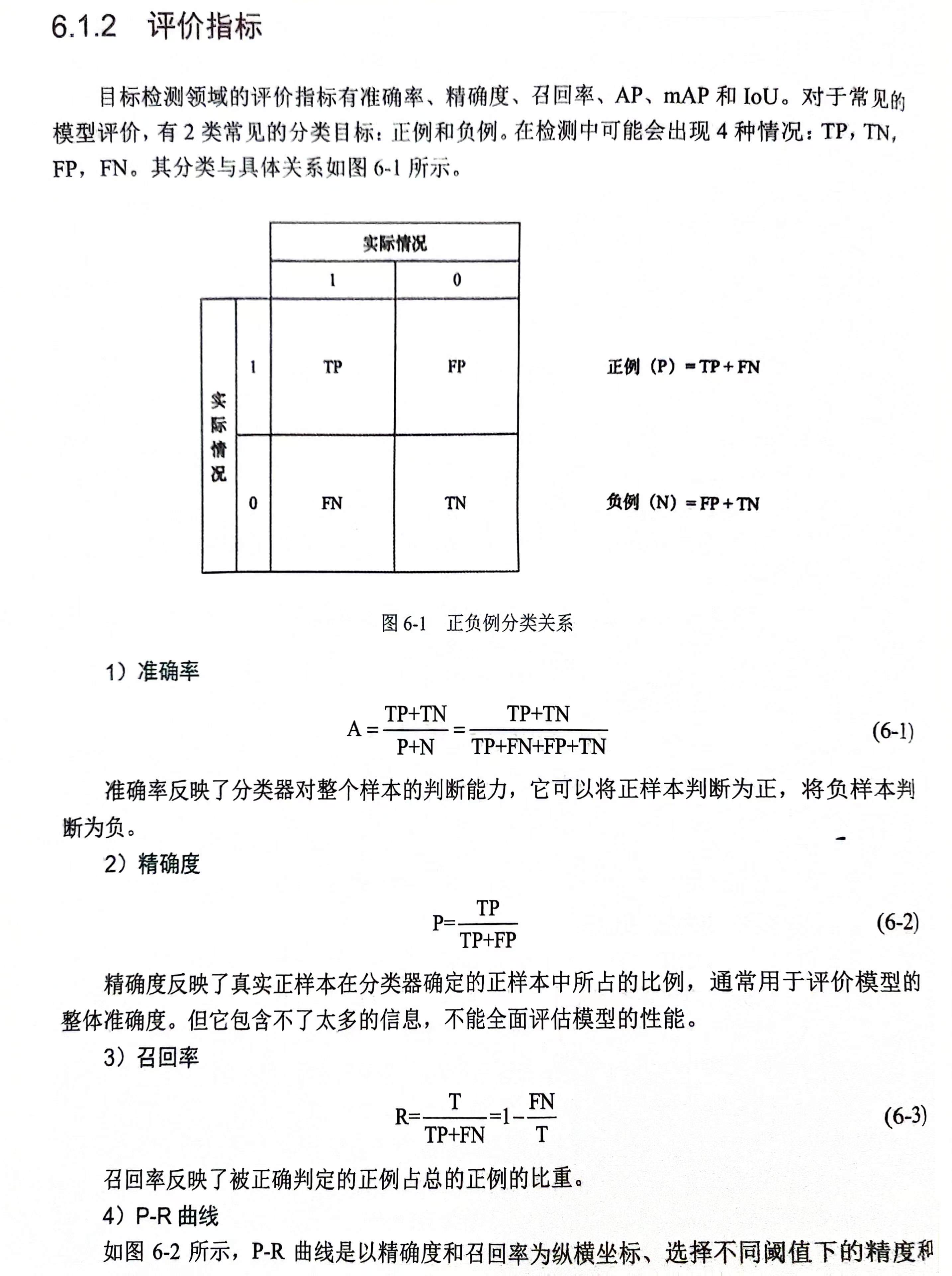
一、感受野的定义
感受野(
R
e
c
e
p
t
i
v
e
Receptive
Receptive
F
i
e
l
d
Field
Field)的定义是卷积神经网络每一层输出的特征图(
f
e
a
t
u
r
e
feature
feature
m
a
p
map
map)上的像素点在原始输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应原始输入图片上的区域,如下图所示。
二、感受野的例子
这里举两个例子来简单说明一下感受野。首先是一个5 * 5的输入图经过两层卷积核为3 * 3的卷积操作后得到的感受野是5*5,其中卷积核(
f
i
l
t
e
r
filter
filter)的步长(
s
t
r
i
d
e
stride
stride)为1、
p
a
d
d
i
n
g
padding
padding为0,如下图所示:
上图中
O
u
t
1
Out1
Out1中左上角第一个值是由
I
n
p
u
t
Input
Input中左上角3 * 3区域的值经过卷积计算出来的,即
O
u
t
1
Out1
Out1中左上角值的感受野是
I
n
p
u
t
Input
Input中左上角3 * 3的区域;
O u t 2 Out2 Out2中的值是由 O u t 1 Out1 Out1中对应3 * 3的区域经过卷积计算得到的,即 O u t 2 Out2 Out2中的感受野是 O u t 1 Out1 Out1中整个3 * 3的区域;
由此可知
O
u
t
2
Out2
Out2的值是由
I
n
p
u
t
Input
Input中所有的区域经过两层卷积计算得到的,即
O
u
t
2
Out2
Out2的感受野是
I
n
p
u
t
Input
Input中所有的5 * 5区域。
再举一个例子,7 * 7的输入图经过三层卷积核为3 * 3的卷积操作后得到
O
u
t
3
Out3
Out3的感受野为7 * 7,也就是
O
u
t
3
Out3
Out3中的值是由
I
n
p
u
t
Input
Input所有区域的值经过卷积计算得到,其中卷积核大小、步长和
p
a
d
d
i
n
g
padding
padding的值均和上面例子相同,如下图所示:
三、感受野的计算
在计算感受野时有下面几点需要说明:
(1)第一层卷积层的输出特征图像素的感受野的大小等于卷积核的大小。
(2)深层卷积层的感受野大小和它之前所有层的滤波器大小和步长有关系。
(3)计算感受野大小时,忽略了图像边缘的影响,即不考虑padding的大小。
下面给出计算感受野大小的计算公式:
R F l + 1 = ( R F l − 1 ) ∗ ∏ i = 1 l s t r i d e s i + f l + 1 RF_{l+1} = (RF_{l}-1)*\prod_{i=1}^{l}strides_i + f_{l+1} RFl+1=(RFl−1)∗i=1∏lstridesi+fl+1
其中 R F l + 1 RF_{l+1} RFl+1为当前特征图对应的感受野的大小,也就是要计算的目标感受野, R F l RF_{l} RFl为上一层特征图对应的感受野大小,f_{l+1}为当前卷积层卷积核的大小,累乘项 s t r i d e s strides strides表示当前卷积层之前所有卷积层的步长乘积。
以上面举的第二个 s a m p l e sample sample为例:
O u t 1 Out1 Out1层由于是第一层卷积输出,即其感受野等于其卷积核的大小,即第一层卷积层输出的特征图的感受野为3, R F 1 RF1 RF1=3;
O u t 2 Out2 Out2层的感受野 R F 2 RF2 RF2 = 3 + (3 - 1) * 1 = 5,即第二层卷积层输出的特征图的感受野为5;
O u t 3 Out3 Out3层的感受野 R F 3 RF3 RF3 = 3 + (5 - 1) * 1 = 7,即第三层卷积层输出的特征图的感受野为7;
下面给出了由上述方法来计算 A l e x n e t Alexnet Alexnet和 V G G 16 VGG16 VGG16网络中每一层输出特征图的感受野大小的 p y t h o n python python代码:
net_struct = {
'alexnet': {'net': [[11, 4, 0], [3, 2, 0], [5, 1, 2], [3, 2, 0], [3, 1, 1], [3, 1, 1], [3, 1, 1], [3, 2, 0]],
'name': ['conv1', 'pool1', 'conv2', 'pool2', 'conv3', 'conv4', 'conv5', 'pool5']},
'vgg16': {'net': [[3, 1, 1], [3, 1, 1], [2, 2, 0], [3, 1, 1], [3, 1, 1], [2, 2, 0], [3, 1, 1], [3, 1, 1], [3, 1, 1],
[2, 2, 0], [3, 1, 1], [3, 1, 1], [3, 1, 1], [2, 2, 0], [3, 1, 1], [3, 1, 1], [3, 1, 1],
[2, 2, 0]],
'name': ['conv1_1', 'conv1_2', 'pool1', 'conv2_1', 'conv2_2', 'pool2', 'conv3_1', 'conv3_2',
'conv3_3', 'pool3', 'conv4_1', 'conv4_2', 'conv4_3', 'pool4', 'conv5_1', 'conv5_2', 'conv5_3',
'pool5']}}
# 输入图片size
imsize = 224
def outFromIn(isz, net, layernum):
totstride = 1
insize = isz
for layer in range(layernum):
fsize, stride, pad = net[layer]
# outsize为每一层的输出size
outsize = (insize - fsize + 2 * pad) / stride + 1
insize = outsize
totstride = totstride * stride
return outsize, totstride
def inFromOut(net, layernum):
RF = 1
for layer in reversed(range(layernum)):
fsize, stride, pad = net[layer]
# 感受野计算公式
RF = ((RF - 1) * stride) + fsize
return RF
if __name__ == '__main__':
print("layer output sizes given image = %dx%d" % (imsize, imsize))
for net in net_struct.keys():
print('************net structrue name is %s**************' % net)
for i in range(len(net_struct[net]['net'])):
p = outFromIn(imsize, net_struct[net]['net'], i + 1)
rf = inFromOut(net_struct[net]['net'], i + 1)
print("Layer Name = %s, Output size = %3d, Stride = % 3d, RF size = %3d" % (net_struct[net]['name'][i], p[0], p[1], rf))
4.感受野的作用
(1)一般 t a s k task task要求感受野越大越好,如图像分类中最后卷积层的感受野要大于输入图像,网络深度越深感受野越大性能越好;
(2)密集预测 t a s k task task要求输出像素的感受野足够的大,确保做出决策时没有忽略重要信息,一般也是越深越好;
(3)目标检测 t a s k task task中设置 a n c h o r anchor anchor要严格对应感受野, a n c h o r anchor anchor太大或偏离感受野都会严重影响检测性能。
5.有效感受野文章来源:https://www.toymoban.com/news/detail-557561.html
U
n
d
e
r
s
t
a
n
d
i
n
g
Understanding
Understanding
t
h
e
the
the
E
f
f
e
c
t
i
v
e
Effective
Effective
R
e
c
e
p
t
i
v
e
Receptive
Receptive
F
i
e
l
d
Field
Field
i
n
in
in
D
e
e
p
Deep
Deep
C
o
n
v
o
l
u
t
i
o
n
a
l
Convolutional
Convolutional
N
e
u
r
a
l
Neural
Neural
N
e
t
w
o
r
k
s
Networks
Networks一文中提出了有效感受野(
E
f
f
e
c
t
i
v
e
Effective
Effective
R
e
c
e
p
t
i
v
e
Receptive
Receptive
F
i
e
l
d
Field
Field,
E
R
F
ERF
ERF)理论,论文发现并不是感受野内所有像素对输出向量的贡献相同,在很多情况下感受野区域内像素的影响分布是高斯,有效感受野仅占理论感受野的一部分,且高斯分布从中心到边缘快速衰减,下图第二个是训练后
C
N
N
CNN
CNN的典型有效感受野。
回到这张图,我们看绿色的这个区域,黄色为图像,绿色框扫过时,对于第一列是只扫过一次,也就是参与一次运算,而之后之间的几列均是参与了多次计算。因此,最终实际感受野,是呈现一种高斯分布。 文章来源地址https://www.toymoban.com/news/detail-557561.html
文章来源地址https://www.toymoban.com/news/detail-557561.html
到了这里,关于计算机视觉中的感受野的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!