- 一、爬取目标
- 二、编写爬虫代码
-
三、同步讲解视频
- 3.1 代码演示视频
- 3.2 详细讲解视频
- 四、获取完整源码
一、爬取目标
您好,我是@马哥python说,一名10年程序猿。
本次爬取的目标是:知乎热榜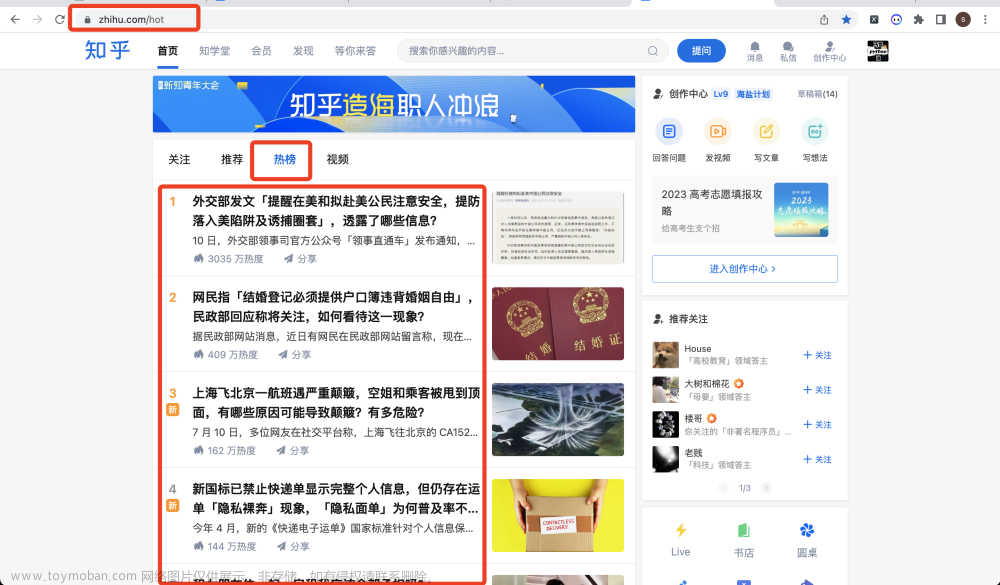
共爬取到6个字段,包含:
热榜排名, 热榜标题, 热榜链接, 热度值, 回答数, 热榜描述。
用CHrome浏览器,右键打开开发者模式,选择:网络->XHR这个选项,重新点击一下【热榜】按钮,或者切换到【视频】页再切换回【热榜】页。
操作过程,如下图所示: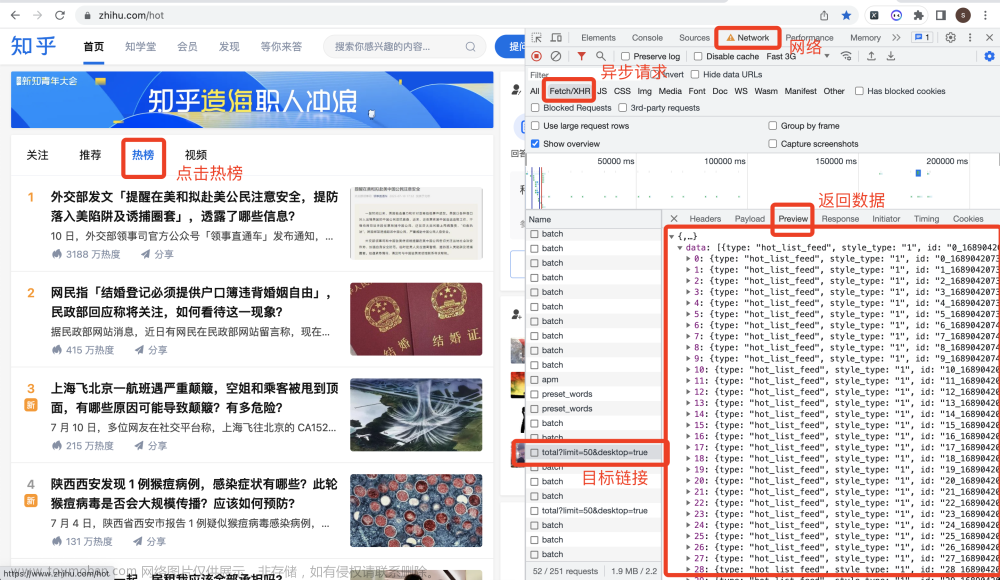
下面,开始编码爬虫代码。
二、编写爬虫代码
首先,导入需要用到的库:
import requests
import pandas as pd
定义一个请求地址,即上图中的目标链接地址:
# 接口地址
url = 'https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total?limit=50&desktop=true'
定义一个请求头,从开发者模式中的Headers->Request Headers中复制下来:
# 构造请求头
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15',
'Referer': 'https://www.zhihu.com/hot',
'Connection': 'keep-alive',
'Cookie': '换成自己的cookie值',
'x-ab-pb': 'CgQnB/gMEgIAAA==',
'x-requested-with': 'fetch',
'x-zst-81': '3_2.0aR_sn77yn6O92wOB8hPZn490EXtucRFqwHNMUrL8YunpELY0w6SmDggMgBgPD4S1hCS974e1DrNPAQLYlUefii_qr6kxELt0M4PGDwN8gGcYAupMWufIoLVqr4gxrRPOI0cY7HL8qun9g93mFukyigcmebS_FwOYPRP0E4rZUrN9DDom3hnynAUMnAVPF_PhaueTF8Lme9gKSq3_BBOG1UVmggHYFJefYqeYfhO_rTgBSMSMpGYLwqcGYDVfXUSTVHefr_xmBq399qX0jCgKNcr_cCSmi9xYvhoLeXx18qCYEw3Of0NLwuc8TUOpS8tMdCcGuCo8kCp_pbLf6hgO_JVKXwFY2JOLG7VCSXxYqrSBICL_5GxmOg_z6XVxqBLfMvxqYDuf3DOf6GLGhDHCbRxO0qLpTDXfbvxCSAH0BhCmJ4NmRBY8rJwB6MS124SqKuo_ywS8ACtBfqwC8XC9QA3KxCepuuCYXhLyWgNCuwYs',
'x-zse-93': '101_3_3.0',
'x-api-version': '3.0.76',
'x-zse-96': '2.0_CkAT7RdDtmW9PikRDfWa4CZIMx50XeUMQ7r34wP2JRAtFiCKXsSmoxCzrKWi2nJ1'
}
不知如何获取Cookie?参考下图: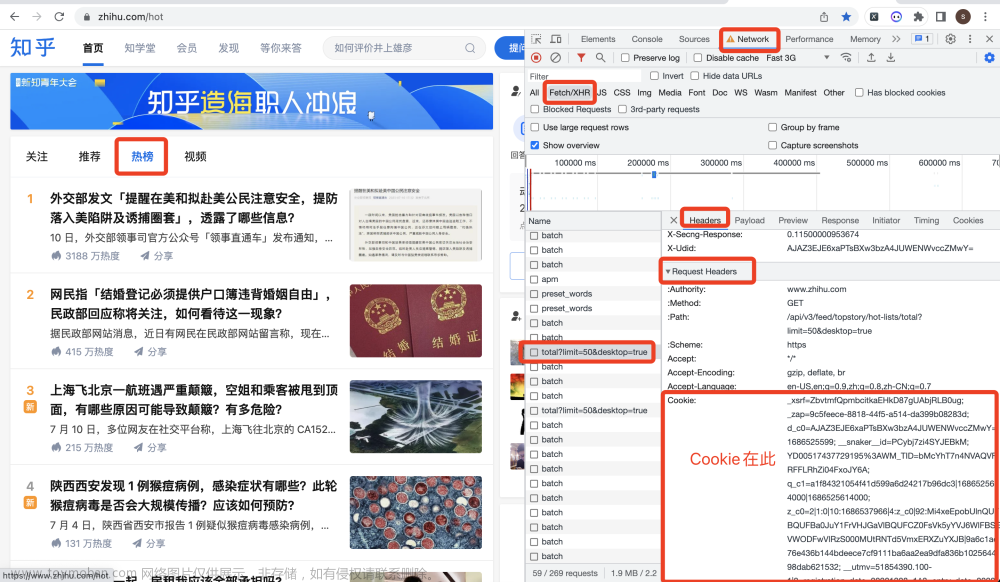
向目标地址发送请求(带上请求头),并用json格式接收返回数据:
# 发送请求
r = requests.get(url, headers=headers)
# 用json接收请求数据
json_data = r.json()
定义一些空列表,用于存储数据:
order_list = [] # 热榜排名
title_list = [] # 热榜标题
desc_list = [] # 热榜描述
url_list = [] # 热榜链接
hot_value_list = [] # 热度值
answer_count_list = [] # 回答数
以“热榜标题”为例,解析数据:
for data in data_list:
# 热榜标题
title = data['target']['title_area']['text']
print(order, '热榜标题:', title)
title_list.append(title)
其他字段同理,不再赘述。
最后,把解析到的数据,存储到Dataframe中,并保存到csv文件里:
# 拼装爬取到的数据为DataFrame
df = pd.DataFrame(
{
'热榜排名': order_list,
'热榜标题': title_list,
'热榜链接': url_list,
'热度值': hot_value_list,
'回答数': answer_count_list,
'热榜描述': desc_list,
}
)
# 保存结果到csv文件
df.to_csv('知乎热榜.csv', index=False, encoding='utf_8_sig')
这里需要注意的是,to_csv要加上encoding='utf_8_sig'参数,防止保存到csv文件产生乱码数据。
查看爬取结果:
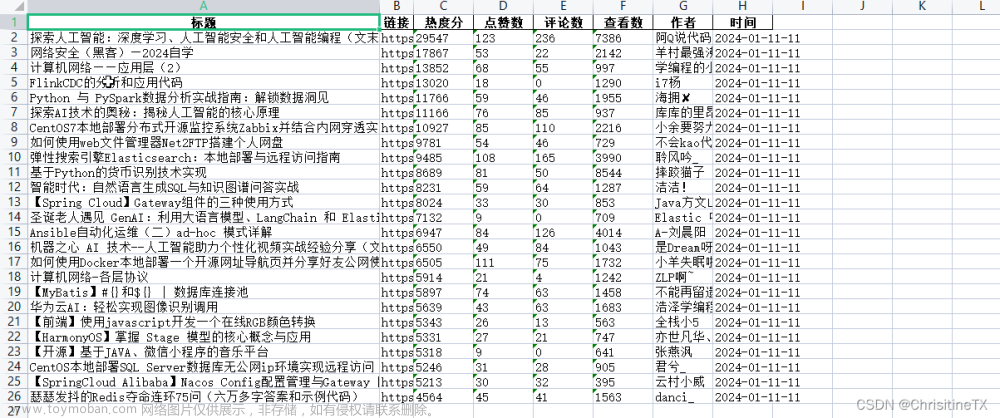
共50条数据,对应热榜TOP50排名。
每条数据含6个字段:热榜排名, 热榜标题, 热榜链接, 热度值, 回答数, 热榜描述。
三、同步讲解视频
3.1 代码演示视频
代码演示: 【Python爬虫演示】用Python爬知乎热榜数据
3.2 详细讲解视频
讲解教程:【Python爬虫教程】5分钟讲解用Python爬取知乎热榜
四、获取完整源码
get完整源码:【爬虫案例】用Python爬取知乎热榜数据!文章来源:https://www.toymoban.com/news/detail-557752.html
我是@马哥python说 ,持续分享python源码干货中!文章来源地址https://www.toymoban.com/news/detail-557752.html
到了这里,关于【爬虫案例】用Python爬取知乎热榜数据!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!