编写测试可以让我们的代码在后续迭代过程中不出现功能性缺陷问题;理解迭代器、闭包的函数式编程特性;Box<T>智能指针在堆上存储数据,Rc<T>智能指针开启多所有权模式等;理解并发,如何安全的使用线程,共享数据。
自动化测试
编写测试以方便我们在后续的迭代过程中,不会改坏代码。保证了程序的健壮性。
测试函数通常进行如下操作:
- 设置需要的数据或状态
- 运行需要测试的代码
- 断言其结果是我们期望的
在 rust 中,通过test属性、断言宏和一些属性设置来测试代码。
$> cargo new ifun-grep --lib
创建项目时,通过--lib表明创建一个库,会默认生成一个测试示例,在src/lib.rs中
pub fn add(left: usize, right: usize) -> usize {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}
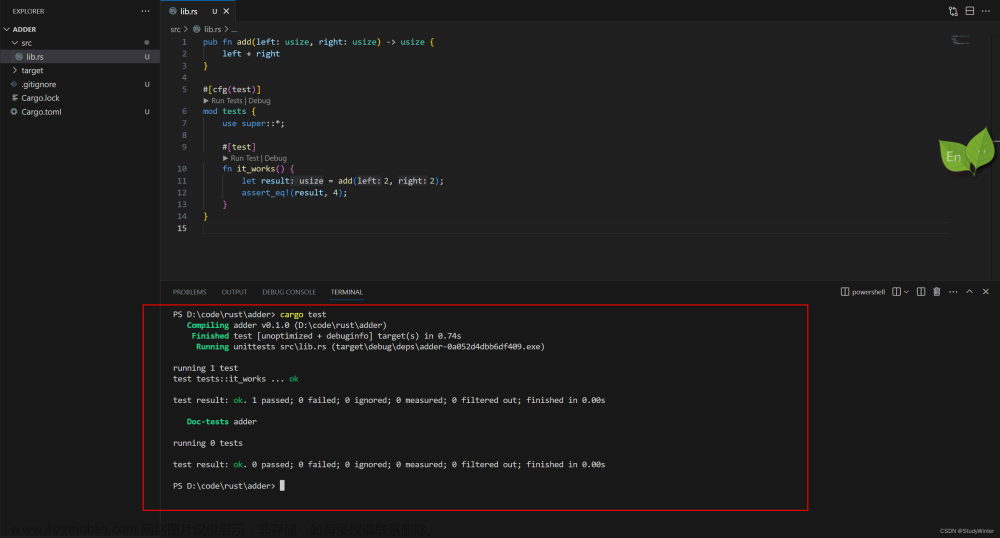
进入到项目中,执行cargo test就会看到执行完测试的详细信息。包括了测试数量、通过测试数、失败测试数等等维度

首先使用mod tests定义了一个 tests 模块,内部函数需要使用外部方法,在最顶部调用了use super::*;。这在包的一节里已有说明。
#[cfg(test)]标注测试模块。它可以告诉 rust 在编译时不需要包含该测试代码。
#[test]表明是测试函数,通过 assert_eq!()断言结果值是否相同。
可以手动改动一下断言值assert_eq!(result, 5),再次执行可以看到测试不通过,并给出了结果的不同之处。
由 rust 标准库提供的断言测试宏,帮助我们处理结果值。结果与预期相同时,则测试会通过;不一样时,则会调用panic!宏,导致测试失败。
-
assert!()一个必传参数,true是测试通过;false测试失败。 -
assert_eq!()两个必传参数,比对它们是否相同。 -
assert_ne!两个必传参数,比对它们是否不相同。
assert_eq!和assert_ne断言失败时,会打印出两个值,便于观察为什么失败。因为会打印输出,所以两个值必须实现PartialEq和Debug trait可以被比较和输出调试。
如果是我们自定义的结构体或枚举类型,则可以直接增加#[derive(PartialEq, Debug)]注解。如果是复杂的类型,则需要派生宏trait,这在后面的文章会讲。
#[derive(PartialEq,Debug)]
struct User {
name: String,
}
宏除了它们必须的参数之外,也可以传递更多的参数,这些参数会被传递给format!()打印输出。这样我们可以增加一些输出,方便解决断言失败的问题
assert_eq!(result, 5, "hello rust!");
测试程序处理错误
除了测试程序正常执行逻辑的结果,也需要测试程序发生错误时,是否按照我们的错误处理逻辑 处理了错误。
假设我们的被测试函数接受的参数不能大于100,大于时panic错误 信息
pub fn add(left: usize, right: usize) -> usize {
if right > 100 {
panic!("the value exceeds 100!");
}
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 102);
assert_eq!(result, 104);
}
}
执行测试cargo test,就算断言结果时逻辑正确的,但是我们的函数限制了参数最大值,测试不通过。
增加测试用例来测试这种场景,通过增加#[should_panic]来处理程序确实有这种限制,并panic!。
#[test]
#[should_panic]
fn value_exceed_100() {
add(5, 120);
}
执行cargo test,可以看到测试示例通过了。如果我们符合参数要求,测试示例就会是失败

但如果我们代码中有多个错误panic!(),就会有同样的多个测试示例不通过,打印输出并没有给我们足够的信息去找到问题所在。
通过should_panic可选择参数expected提供一个错误描述信息,
pub fn add(left: usize, right: usize) -> usize {
if right > 100 {
panic!("the value exceeds 100!,got {}", right)
} else if right < 50 {
panic!("the value does not less than 50!,got {}", right)
}
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "exceeds 100!")]
fn value_exceed_100() {
add(5, 99);
}
#[test]
#[should_panic(expected = "less than 50!")]
fn value_not_less_50() {
add(59, 59);
}
}
也可以通过Result<T,E>编写测试,在程序失败时,返回Err而不是panic;
#[test]
fn add_equal() -> Result<(), String> {
if add(5, 105) == 111 {
Ok(())
} else {
Err(String::from("Error in add"))
}
}
此时不能使用#[should_panic()]注解。也不能使用表达式?
控制测试运行
cargo test在测试模式下编译代码并发运行生成的测试二进制文件。
- 可以通过设置测试线程,单次只执行一个测试示例
$> cargo test -- --test-threads=1
测试线程为 1,程序不会使用任何并行机制。
- 默认的测试在测试示例通过时,不会打印输出。通过设置在测试成功时也输出程序中的打印
$> cargo test -- --show-output
- 默认的
cargo test会运行所有测试,通过指定名称来运行部分测试
$> cargot test add_equal
过滤运行多个测试,可以通过指定测试名称的一部分,只要匹配这个名称的测试都会被运行。
$> cargot test value
通过#[ignore]标记忽略该测试。
#[test]
#[ignore]
fn add_equal() -> Result<(), String> {
if add(5, 105) == 110 {
Ok(())
} else {
Err(String::from("Error in add"))
}
}
测试被忽略,但是可以通过cargot test -- --ignored来运行被忽略的测试。
如果想运行所有的测试,可以通过cargot test -- --include-ignored
集成测试
单元测试可以在指定的模块中书写测试实例,每次测试一个模块,也可以测试私有接口。
集成测试对库来说是外部的,只能测试公有接口,可测试多个模块。通过创建tests目录编写独立的测试文件。
tests/lib.rs
use ifun_grep;
#[test]
#[should_panic(expected = "exceeds")]
fn value_exceed_100() {
ifun_grep::add(5, 99);
}
随着集成测试模块的增多,我们需要更好的组织它们,可以根据测试的功能将测试分组。将一些测试公共模块抽离出来,作为其他测试功能组的测试函数调用
比如tests/common.rs
pub fn init(){
// something init
}
再执行cargo test,会看到运行了tests/common.rs 运行了 0 个测试。这显然是我们不需要的,可以改写文件目录tests/common/mod.rs,这会告诉 rust 不要将common看作一个集成测试文件。
迭代器与闭包
rust 类似函数式编程语言的特性。可以将函数作为参数值或返回值、将函数赋值给变量等。
闭包
可以储存在变量里的类似函数的结构。保存在一个变量中或作为参数传递给其他函数的匿名函数。
闭包允许捕获被定义时所在作用域中的值。
#[derive(Debug)]
enum Name {
Admin,
Test,
}
#[derive(Debug)]
struct User {}
impl User {
fn get_name(&self, name: Option<Name>) -> Name {
name.unwrap_or_else(|| self.random_name())
}
fn random_name(&self) -> Name {
Name::Admin
}
}
fn main(){
let user = User {};
println!("{:?}", user.get_name(Some(Name::Test)));
println!("{:?}", user.get_name(None));
}
unwrap_or_else方法接受一个闭包函数,当一个Some值存在时直接返回,如果不存在则执行其传入的闭包函数计算一个值返回。
闭包不需要在参数或返回值上注明类型。闭包通常只关联小范围的上下文而非任意情景,所以编译器可以推导出参数和返回值类型。
也可以显示定义闭包的参数和返回值的类型:
fn main(){
let get_age = |age: i8| -> i8 { age };
// let get_age = |age| age;
println!("{}", get_age(32));
}
相对于增加参数或返回值类型使得书写更加的繁琐。而对于未标注类型的闭包,在第一次调用后就确定其参数和返回值类型,再传其他类型时就会报错。
fn main(){
let get_age = |age| age;
println!("{}", get_age(String::from("admin")));
// 调用出错,已经确定了参数和返回值类型为String
println!("{}", get_age(32));
}
捕获引用或移动所有权
在传递给闭包参数时,需要考虑参数的传递方式:不可变借用、可变借用和获取所有权。这是根据传递的值决定的。
对于不可变借用,变量可以在任何情形下被访问。
let str = String::from("hboot");
let print_str = || println!("{:?}", str);
println!("{str}");
print_str();
println!("{str}");
而对于可变借用,则只能在借用结束后调用.声明的闭包函数也需要mut声明
let mut str = String::from("hboot");
let mut print_str = || str.push_str("-rust");
// println!("{str}");
print_str();
println!("{str}");
通过move关键字将变量的所有权转移闭包所在的环境中。
use std::thread;
fn main(){
let mut str = String::from("hboot");
println!("{str}");
thread::spawn(move || {
str.push_str("-rust");
println!("{str}")
})
.join()
.unwrap();
}
此时,将变量str值的所有权转移到了新线程中,主线程则不能再使用。
将被捕获的值移出闭包和 Fn trait
在闭包环境中,捕获和处理值的方式会影响闭包 trait 的实现。trait 是函数或结构体指定它们可以使用什么类型的闭包。
从闭包如何任何处理值、闭包自动、渐进实现一个、多个 Fntrait
-
FnOnce适用于调用一次的闭包。所有闭包都是实现这个 trait,它会将捕获的值移除闭包。 -
FnMut不会将捕获的值移除闭包,可能会修改值。会被调用 多次。 -
Fn不会移除捕获的值,也不修改捕获的值。会被调用多次而不改变其环境。
这是Option<T>的unwrap_or_else()方法定义
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}
F就是闭包指定的类型,T是返回值类型。FnOnce()->T表明了闭包会被调用一次,有值时Some,返回值;没有值时None,f调用一次。
在使用闭包时,如果我们不需要捕获其环境中的值,则可以不使用闭包,而使用传递函数作为参数。
迭代器
迭代器是处理元素序列的方式。遍历序列中的每一项以及决定序列何时结束的逻辑。
fn main(){
let arr = [1, 2, 3, 4];
for val in arr {
println!("{}", val)
}
}
迭代器都定义了Iteratortrait,并实现next方法。调用next返回迭代器的一个项,封装在Some中,结束后返回None
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
type Item和Self::Item定义了 trait 的关联类型。表明了迭代器返回值类型为Item
可以通过next()方法迭代获取值:
fn main(){
let arr = [1, 2, 3, 4];
let mut iter = arr.iter();
println!("{:?}", iter.next());
println!("{:?}", iter.next());
}
iter()生成一个不可变引用的迭代器。对于迭代器实例iter必须是mut可变的。
-
into_ter()获取到 arr 所有权的迭代器。 -
iter_mut()可以获取到可变引用迭代器。
消费适配器
调用next()方法的方法被称为消费适配器。
fn main() {
let arr = [1, 2, 3, 4];
let total: i8 = arr.iter().sum();
println!("{}", total);
}
这些方法总是会获取迭代器的所有权并反复调用 next来遍历迭代器。sum()方法返回调用next方法获取值,最终返回和值。
迭代器适配器
将当前迭代器变为不同类型的迭代器。可以链式调用多个迭代器适配器,但是每次调用都必须调用消费适配器来获取调用结果。
fn main(){
let arr = [1, 2, 3, 4];
let arr2: Vec<_> = arr.iter().map(|val| val + 1).collect();
for val in arr2 {
println!("{}", val)
}
}
map()方法接受一个闭包函数,可以在遍历元素上执行任何操作。进行了一次迭代适配器操作,然后通过collect()方法获取调用的结果值。
智能指针
指针是一个包含内存地址的变量。智能指针是一类数据结构,表现同指针,并拥有额外的元数据和功能。
智能指针通常使用结构体实现,实现了Deref和Droptrait。deref trait 允许智能指针结构体实例表现的像引用一样;drop trait 允许智能指针离开作用域时自定义运行代码
标准库中常用的智能指针:
-
Box<T>用于在堆上分配值 -
Rc<T>引用计数类型,其数据可以有多个所有者 -
Ref<T>、RefMut<T>通过RefCell<T>访问,这是一个在运行时执行借用规则的类型。
Box<T>
智能指针 box 允许将一个值放在堆上而不是栈上。留在栈上的则是指向堆数据的指针。
在以下情况下可以考虑使用:
- 编译时未知大小的类型,又想在确切大小的上下文中使用这个类型的值。
- 当有大量数据不被拷贝的情况下转移所有权的时候
- 当有一个值只关心它的类型是否实现特定 trait,而不是具体类型的时候
fn main(){
let b = Box::new(100);
println!("{}", b);
}
直接声明创建 box 类型变量,并分配了一个值100存储在堆上, 可以直接访问变量访问值。
通过cons list 数据结构定义递归数据类型
它是construct function的缩写,利用两个参数构造一个新的列表.最后一项值包含了Nil值,标识结束
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main(){
let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil))))));
}
Cons可能会无限嵌套下去,为了保证 rust 编译时计算需要的大小,只能通过Box来帮助 rust 计算出List需要的大小。
Dereftrait 重载解引用运算符*
之前已经使用过*解引用值,可以获取到指针指向引用的值。
fn main(){
let mut s = String::from("hboot");
let s1 = &mut s;
*s1 += " admin";
println!("{}", s)
}
s1是 s 的可变引用,再通过*解引用后,可以修改存储在堆上的数据。
也可以通过Box<T>代替引用,和*拥有相同的功能。
fn main(){
let s = String::from("hboot");
let mut s1 = Box::new(s);
*s1 += " admin";
println!("{:?}", s1);
}
Box会拷贝s在栈上的指针数据,导致存储在堆上的数据所有权被转移,s在后续变的不可用。
自定义实现一个智能指针MyBox,它可以做到上面的解引用操作
#[derive(Debug)]
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(val: T) -> MyBox<T> {
MyBox(val)
}
}
实现了一个元组结构体,自定义实例new方法,接受一个参数进行初始化操作。还需要实现解引用功能,Dereftrait 由标准库提供,实现 deref 方法
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}
上述的解引用例子,则可以由MyBox代替实现。type Target = T定义了 trait 的关联类型,&self.0访问元组结构体的第一个元素。
fn main(){
let s = String::from("hboot");
let s1 = MyBox::new(s);
// *s1 += " admin";
println!("{:?}", *s1);
}
因为实现的是Deref所以不能修改,修改时需要实现DerefMuttrait。
实现了Dereftrait 的数据类型,在函数传参时,可做到隐式转换,而不需要手动去转换为参数需要的类型。
fn print(val: &str) {
println!("{}", val)
}
fn main(){
// 输出上面的示例 s1
print(&s1);
}
对于数据的强制转换,只能将可变引用转为不可变引用;不能将不可变引用转为可变引用。
Drop trait 运行清理代码
实现了Droptrait 的数据,在离开作用域时,会调用其实现的drop方法,它获取一个可变引用。
为上述的MyBox实现Drop,无需引入,Droptrait 是 prelude 的。
impl<T> Drop for MyBox<T> {
fn drop(&mut self) {
println!("mybox drop value");
}
}
再次调用执行,可以看到最终在程序执行完毕后,打印输出了mybox drop value. drop会自动执行,而无需手动调用。
如果想要提前销毁资源,则需要std::mem::drop,可以调用drop方法
fn main(){
drop(s1);
// 手动清理后,后续不能再使用s1
// print(&s1);
}
Rc<T> 引用计数启用多所有权模式
在图形结构中,每个节点都有多个边指向,所以每个节点都会拥有指向它的边的所有权。
通过使用Rc<T>类型,记录被引用的数量,来确定这个值有没有被引用。如果为 0 没有被引用,则会被清理。
Rc<T>只适用于单线程
创建Rc类型的变量s,然后通过Rc::clone克隆变量s生成s1\s2.
use std::rc::Rc;
fn main(){
let s = Rc::new(String::from("hboot"));
let s1 = Rc::clone(&s);
let s2 = Rc::clone(&s);
println!("s:{},s1:{},s2:{}", s, s1, s2)
}
这里可以看到s1、s2没有获取s的所有权,它们仍然同时生效。Rc::clone不同于深拷贝,只会增加引用计数。
可以通过strong_count()方法查看被引用次数
fn main(){
let s = Rc::new(String::from("hboot"));
println!("s create - {}", Rc::strong_count(&s));
let s1 = Rc::clone(&s);
println!("s1 create - {}", Rc::strong_count(&s));
{
let s2 = Rc::clone(&s);
println!("s2 create - {}", Rc::strong_count(&s));
}
println!("s2 goes out of scope - {}", Rc::strong_count(&s));
}
执行测试输出为

通过不可变引用,Rc<T>允许程序在多个部分之间只读地共享数据。
RefCell<T> 允许修改不可变引用
根据 rust 的不可变引用规则,被引用的变量是不允许修改。但是在某些模式下,可以做到修改,也就是内部可变性模式。
内部可变性通过在数据结构中使用unsafe代码来模糊 rust 的不可变性和借用规则。unsafe不安全代码表明我们需要手动去检查代码而不是让编译器检查。
RefCell<T>类型是在代码运行时作用检测不可变或可变借用规则,而通常的规则检测是在编译阶段。
特点:
- 可以在允许出现特定内存安全的场景中使用。
- 需要确认你的代码遵守了借用规则,但是 rust 无法理解
- 只能用于单线程
RefCell<T> 在运行时记录借用,通过borrow()和borrow_mut()方法,会返回Ref<T>和RefMut<T>智能指针,并实现了Dereftrait.
定义一个MixNametrait,然后结构体User实现了它,并实现它的方法mix.
use std::cell::RefCell;
pub trait MixName {
fn mix(&self, suffix: &str);
}
struct User {
name: RefCell<String>,
}
impl User {
fn new() -> User {
User {
name: RefCell::new(String::from("hboot")),
}
}
}
impl MixName for User {
fn mix(&self, suffix: &str) {
self.name.borrow_mut().push_str(suffix);
}
}
mix方法修改了 self 内部属性name的值,但是我们可以看到&self时不可变引用,这归功于RefCell<T>创建值,使得不可变借用可以修改其内部值。
fn main(){
let user = User::new();
user.mix(" hello");
println!("{:?}", user.name.borrow());
}
执行程序可以看到内部的值已经被修改了。RefCell<T>会在调用borrow时,记录借用次数,当离开了作用域时,借用次数减一。
RefCell<T>只能有一个所有者,结合Rc<T>使其拥有多个可变数据所有者。
use std::cell::RefCell;
use std::rc::Rc;
fn main(){
let s = Rc::new(RefCell::new(String::from("hboot")));
let s1 = Rc::clone(&s);
let s2 = Rc::clone(&s);
*s.borrow_mut() += " good";
println!("{:?}", s);
}
通过RefCell来创建变量,然后通过Rc开启多所有权,这样在*s.borrow_mut() += " good";,修改后,变量s、s1、s2的值都发生了变更。
但是这只能在单线中使用,如果想要多线程使用,则需要使用并发安全的Mutex<T>类型。
无畏并发
并发编程 - 代表程序的不同部分相互独立的运行。
并行编程 - 代表程序不同部分同时执行。
thread多线程运行代码
多线程运行代码可以提高程序的执行效率。也会造成一些问题
- 多个线程在不同时刻访问同一数据资源,形成竞争
- 相互等待对方,造成死锁
- 一些情况下出现的难以修复的 bug
使用thread::spawn创建一个线程,它接受一个闭包函数
use std::thread;
fn main() {
thread::spawn(|| {
println!("hello!");
});
println!("rust!");
}
可以看到输出,先是rust!,也就是主线程先执行。可以多次执行cargo run以观察结果,会出现新线程没有打印输出,这是因为主线程结束,新线程也会结束,而不会等待新线程是否执行完毕。
可以通过线程休眠,展示这一特点
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
thread::sleep(Duration::from_millis(2));
println!("hello!");
});
println!("rust!");
}
程序基本没有什么机会切换到新线程去执行,也看不到新线程的打印输出。
可以通过thread::spawn的返回值线程实例,然后调用join()方法,来等待线程结束
let thread = thread::spawn(|| {
thread::sleep(Duration::from_millis(2));
println!("hello!");
});
println!("rust!");
thread.join().unwrap();
再次执行,可以看到新线程的打印输出。join()会阻塞当前线程,知道线程实例thread执行完毕。
可以将thread.join().unwrap();放在主线程输出之前,优先执行
thread.join().unwrap();
println!("rust!");
通过move关键字强制闭包获取其所有权,thread::spawn创建线程给的闭包函数没有任何参数,需要使用主线程里的变量
let name = String::from("hboot");
let thread = thread::spawn(move || {
thread::sleep(Duration::from_millis(2));
println!("hello! - {}", name);
});
新线程强制获取了环境中变量的所有权,保证了新线程执行不会出错。如果是引用,那么由于新线程的执行顺序,可能会在主线程执行过程使引用失效,从而导致新线程执行报错
线程间消息传递
通过channel实现线程间消息的传递并发。
通过mpsc::channel创建通信通道,这个通道可以有多个发送端,但只能有一个接收端.
use std::sync::mpsc;
fn main(){
let (send, receive) = mpsc::channel();
thread::spawn(move || {
let name = String::from("rust");
send.send(name).unwrap();
});
let receive_str = receive.recv().unwrap();
println!("get thread msg :{}", receive_str);
}
mpsc::channel()生成一个通过,返回一个元组,第一个是发送者,第二个是接收者。然后创建一个新线程,通过实例对象send发送一条信息;在主线程中通过实例对象receive接受数据。
不管是send()发送方法还是recv()方法,它们都返回Result<T,E>类型,如果接受端或发送端被清除了,则会返回错误。
接受recv()方法是阻塞线程的,也就是必须接收到一个值。还有一个方法try_recv()方法则不会阻塞,需要频繁去调用,在有可用消息时进行处理。
新线程将变量name发送出去,那么它的所有权也被转移 出去了,后续不能使用它
send.send(name).unwrap();
// 在发送后,不能再使用改变量
println!("{}", name);
当在子线程中连续多次发送多个值时,可以通过迭代器遍历receive获取值
fn main(){
let (send, receive) = mpsc::channel();
thread::spawn(move || {
send.send(1).unwrap();
send.send(10).unwrap();
send.send(100).unwrap();
});
for receive_str in receive {
println!("{}", receive_str);
}
}
上述例子只是单发送者,可以通过clone()方法克隆send发送对象,然后传给另一个线程
fn main(){
let (send, receive) = mpsc::channel();
let send_str = send.clone();
thread::spawn(move || {
send_str.send("hello").unwrap();
send_str.send("rust").unwrap();
});
thread::spawn(move || {
send.send("good").unwrap();
send.send("hboot").unwrap();
});
for receive_str in receive {
println!("{}", receive_str);
}
}
创建两个线程,一个线程传入时克隆的send_str,它们都发送消息,然后在主线程中,接收到所有消息。
多个线程由于执行顺序导致打印输出的顺序也不尽相同。这依赖于系统,我们可以通过线程休眠做实验,观察到输出的顺序不同
线程间共享状态
除了相互之间发送消息外, 还可以通过共享数据,来传递数据状态变化。
通过Mutex<T>创建共享数据,在需要使用的线程中通过lock()获取锁,以访问数据。
use std::sync::{Mutex};
fn main()[
let name = Mutex::new(String::from("hboot"));
{
let mut name = name.lock().unwrap();
*name += " good!";
}
println!("{:?}", name.lock().unwrap());
]
新创建的数据hboot,在局部作用域中获取锁,然后解引用后变更值,最终打印输出可以看到变更后的数据。
Mutext<T>是一个智能指针,调用lock()返回了一个MutexGuard智能指针,它实现了Deref来指向内部数据,同时也提供Drop实现了当离开作用域时自动释放锁。
正因为这样,我们在编码时,不会因为忘记释放锁而导致其他线程访问不了数据。
如果想要在多个线程中访问共享数据,因为线程需要转移所有权,这样导致共享数据每次只能在一个线程中使用,通过Arc<T>来创建多所有者,使得共享数据可被多个线程同时访问。
use std::sync::{Arc, Mutex};
use std::thread;
fn main(){
let name = Arc::new(Mutex::new(String::from("hboot")));
let mut thread_arr = vec![];
for val in ["admin", "test", "hello", "rust"] {
let name = Arc::clone(&name);
let thread = thread::spawn(move || {
let mut name = name.lock().unwrap();
*name += val;
});
thread_arr.push(thread);
}
for thread in thread_arr {
thread.join().unwrap();
}
println!("{:?}", name.lock().unwrap())
}
Arc<T>拥有和Rc<T>相同的 api,它可以用于并发环境的类型。这是一个原子引用计数类型。
Mutex<T>同RefCell<T>一样,提供了内部可变性,通过获取内布值的可变引用修改值。当然,Mutex<T>也会有出现相互引用锁死的风险,两个线程需要锁住两个资源而各自已经锁了一个,造成了互相等待的问题。
Sync和Send trait扩展并发
除了使用 rust 标准库提供的处理并发问题,还可以使用别人编写的并发功能
当尝试编写并发功能时,有两个并发概念:
-
通过
Send trait表明实现了Send的类型值的所有权可以在线程间传递。rust 几乎所有类型都是Send, 还有一些不能Send,比如Rc<T>,它只能用于单线程, -
通过
Sync trait表明实现了Sync的类型可以安全的在多个线程中拥有其值的引用。Rc<T>、RefCell<T>都不是Sync类型的。文章来源:https://www.toymoban.com/news/detail-559088.html
根据这两个概念,可以手动创建用于并发功能的并发类型,在使用时需要多加小心,以维护其安全保证。文章来源地址https://www.toymoban.com/news/detail-559088.html
到了这里,关于rust 自动化测试、迭代器与闭包、智能指针、无畏并发的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!