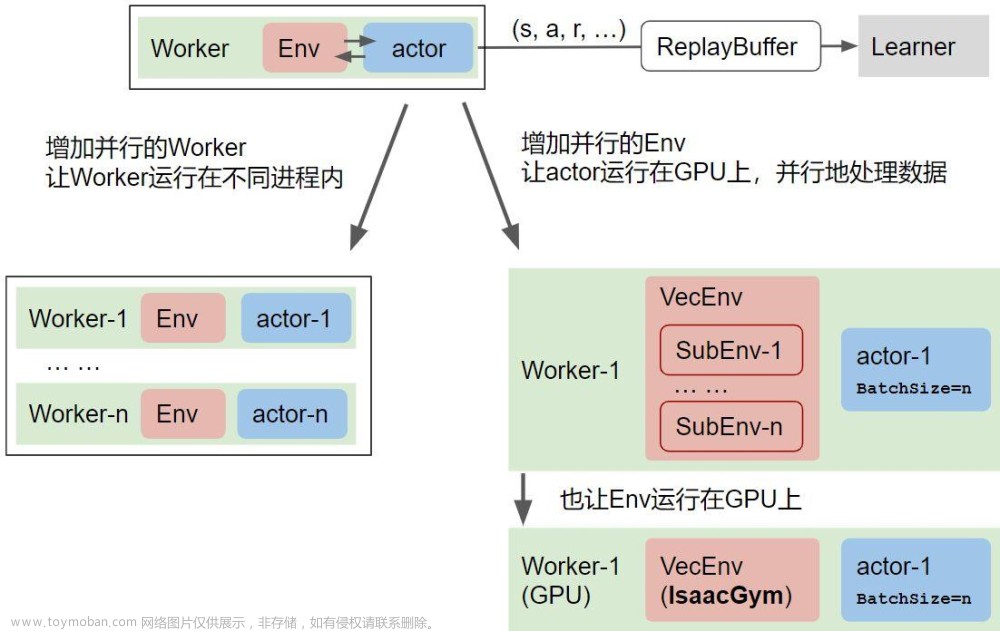
仿真环境的采样速度慢,是强化学习的一个瓶颈。例如,论文中常用的 MuJoCo 环境,台式机或服务器的 CPU 上运行仿真环境,一小时大概采集十万或百万步(1e5 或 1e6 步);训练一个智能体(收敛后)需要十多个小时。
加快仿真环境的采样速度,通常有以下方法:
- 增加并行的 Worker 数(Multiple workers)
- 增加并行的 Env 数(Vectorized Env)

NVIDIA 的 Isaac Gym(上图中右下角),用单块 GPU 一小时内可以采集一亿步(1e8 步)。也就是说,GPU 上的并行仿真环境,采样速度快了两个量级! 下图是我们的一组测试结果
Isaac Gym 的命名根据 Isaac Newton 艾萨克 · 牛顿
 文章来源:https://www.toymoban.com/news/detail-560038.html
文章来源:https://www.toymoban.com/news/detail-560038.html
左图以采样数 #samples 为横坐标,右图以训练时间 (hours) 为横坐标。上图中可以看到,GPU 并行仿真环境在一文章来源地址https://www.toymoban.com/news/detail-560038.html
到了这里,关于并行环境让采样速度快两个量级:Isaac Gym提速强化学习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!