并查集
导论
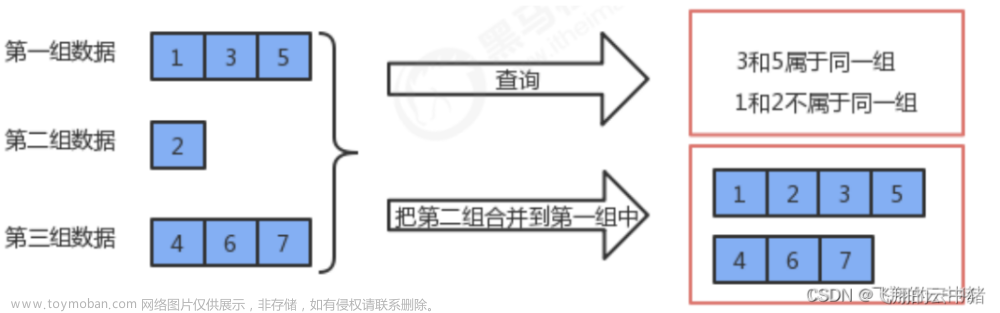
并查集是一种数据结构,主要用于处理一些不相交集合的合并问题。一般应用在连通图、最小生成树、Kruskal算法、最近公共祖先(LCA)等算法中。
举例
用帮派例子理解并查集:在n个人中,分成了不同的帮派,每个帮派的人都互为朋友,朋友的朋友是朋友,例如1号和2号是朋友,1号和3号也是朋友,那么2号和3号也是朋友,问每个人属于哪个帮派?
概念
将编号分别为1~n的n个对象划分不相交的集合,在每个集合中,选择其中某个元素代表所在集合。
主要内容
并查集的基本操作、并查集的合并优化、并查集的查询优化——路径压缩、(按秩合并——不常用)、带权并查集。
一、并查集的基本操作
1.初始化
用每个点代表独立的集。

2.合并
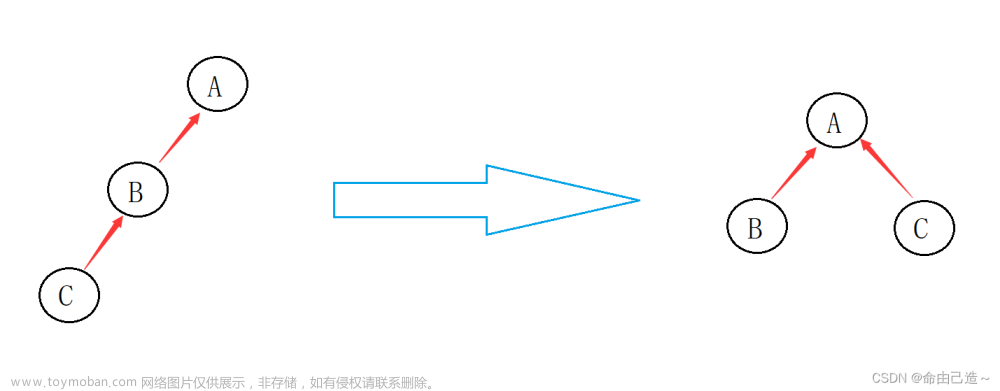
先把(1,2)合并,在合并(2,3),以此类推若合并所有点他们的最终节点就是最后一个合并的数所指向的节点,我们称这个节点为根节点,合并操作就是把每个集合归为一个根节点。

3.查找
通过一个节点查找他的根节点,查找是通过递归进行的,最坏情况是查找的节点是头节点而目标是尾节点那么时间复杂度就是O(n)了(类似链表的查找操作)。
4.统计
如果s[i]=i,这是一个根节点,是他所在集合的代表;统计根节点的数量就是集合的数量。
5.例题
[hdu 1213](问题 - 1213 (hdu.edu.cn))

代码模板
#include <bits/stdc++.h>
using namespace std;
const int N= 1010;
int s[N];
int cnt;
void init_set() //初始化
{
for(int i=1;i<N;i++)s[i]=i;
}
int find_set(int x) //查找
{
return x==s[x]?x:find_set(s[x]);
}
void merge_set(int x,int y) //合并
{
x=find_set(x),y=find_set(y);
if(x!=y)s[x]=s[y]; //把s[y]的值赋给s[x],即s[x]指向s[y]
}
int main()
{
int t;
cin>>t;
while(t--)
{
init_set();
int n,m;
cin>>n>>m;
for(int i=0;i<m;i++)
{
int x,y;
cin>>x>>y;
merge_set(x,y);
}
cnt=0;
for(int i=1;i<=n;i++)
if(s[i]==i)cnt++; //查找集合
cout<<cnt<<endl;
}
}
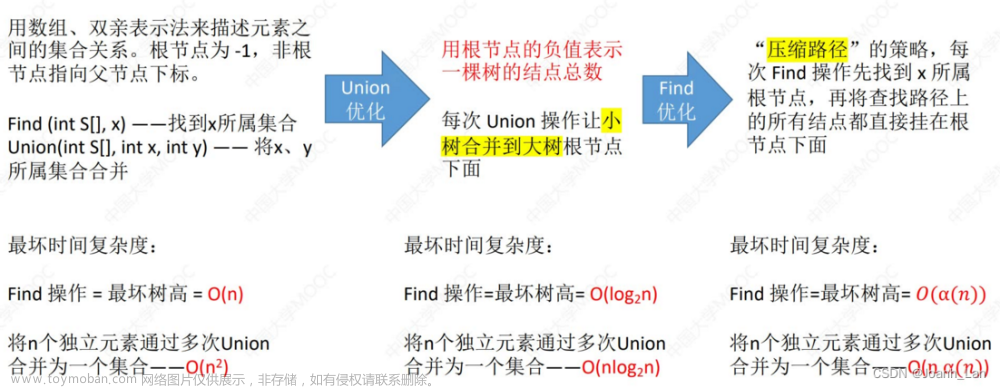
二、合并的优化
步骤
基本操作是把两个集合合并位一个长集合,即每一个点只有一个子节点,在最坏情况下复杂度都为O(n)。
可以通过引入多叉树的概念减小树的长度把复杂度优化到O(n)。

我们可以发现这样优化后一个节点上可以有多个分枝,在大量数据时可以有效减少查询、合并的耗费的时间(相比于朴素版)。
在合并时我们可以发现如果将大树合并到小树上去那么大树的长度会加一,如果把小树合并到大树上去,最大长度还是大树的长度,
即把小树合并到大树上可以减少整颗树的长度。
代码模板
int hight[N];
void init_set()
{
for(int i=1;i<N;i++)s[i]=i;
}
void merge_set(int x,int y)
{
x=find_set(x),y=find_set(y);
if(x!=y)
{
if(hight[x]==hight[y])
{
hight[y]=hight[y]+1;
s[x]=s[y];
}
else
{
if(hight[x]<hight[y])s[x]=s[y];
else s[y]=s[x];
}
}
}
三、路径压缩
优化步骤
由于我们对算法都是精益求精的,想在合并的优化上进一步优化,有些聪明的小朋友就想到了一个办法把递归后的回溯也用上,就出现了路径压缩的代码。这个优化的强大在于在每次查询后都会把沿途上的点指向的节点更新为跟节点,这样我们的合并就只需要把要合并的点直接指向根节点,而且由于每个点都是指向他们的根节点所以查询的复杂度为O(1),不得不说优化这个代码的小朋友太厉害了。

代码模板.1
int find_set(int x)
{
if(x!=s[x])s[x]=find_set(s[x]);
return s[x];
}
如果数据规模太大引起爆栈,这可以把栈换为循环
代码模板.2
int find_set(int x)
{
int r=x;
while(s[r]!=r)r=s[r]; //查找根节点
int i=x,j; //j是用户记录s当前值的桥梁和冒泡排序中的桥梁作用一样
while(i!=r)
{
j=s[i];
s[i]=r;
i=j;
}
return r;
}
通过先查找到根节点,找到了根节点的值,在重头开始遍历把每个点的指向都改为根节点。
四、带权并查集
上述的操作中只讲述了并查集处理集合的问题——判断集合的归属关系,很多时候集合往往会附带一些独特的权值,独特在于有些权值是通过某种建模从具体问题中抽象出来的某种属性,在问题中需要维护这种属性才能得到应有的答案,而这种抽象能力需要大量做题才能培养出来。
并查集实际上是在维护若干颗树。并查集的合并和查询优化实际上是在改变树的形状,把原来‘’细长‘’的、操作效率低的‘’小树‘’,变为‘’粗短‘’的、操作效率高的少量‘’大树‘’。如果在原来的‘’小树‘’上,点之间有权值,那么经过并查集的优化变成‘’大树‘’后,这些权值的操作也变得高效了。
定义一个权值数组d[],把节点i到父节点的权值记为d[i]。
1.带权值的路径压缩

以权值相加操作为例,d[x]代表到父节点x的权值,通过递归到根节点,d[x]就表示到根节点的权值。
代码模板
int find_set(int x)
{
if(x!=s[x])
{
int t=s[x];
s[x]=find_set(s[x]);
d[x]+=d[t];
}
return s[x];
}
用递归记录当前节点的父节点,回溯是d[x]已经指向跟节点,再通过之前记录的t把路径上的权值相加。
2.带权值的合并
在合并操作中,把x和y合并,就是把x的根节点f(x)合并到y的根节点f(y)。在f(x)和f(y)之间加上权值,这个权值要符合题目要求。
3.例题
[hdu-3038](Problem - 3038 (hdu.edu.cn))

分析题目
题目大意,在[1,n]这个范围中,给出m调指令,遇到冲突就忽略掉,问一共忽略了几条。
需要注意的是,题目指出如果没有逻辑错误答案都是正确的,如果给出[1,3]=100、[1,2]=200并不冲突,因为权值可以为负数。
思路:我们只需要判断所求区间在已知区间(可以计算得出的区间)内冲突才忽略,权值存在负数就可以用矢量来表示,即可以用向量法。
对于求两段之间的距离参考前缀和的区间距离计算公式是b-(a-1),所以要把a的值-1,如果不-1的话计算的距离会把a本身的值减去得到的就是a+1~b的距离。

只有两个点同属于一个集合时才没有v(ra),这时可以计算出剩余区间的值,如果这个值与给定的值相同则成立,反之则冲突。
对于区间权值的合并就交给并查集完成,因为相加的权值所以直接套模板就行。
代码模板
#include <bits/stdc++.h>
using namespace std;
const int N=2e5+10;
int s[N];
int d[N];
int ans;
void init()
{
for(int i=0;i<N;i++){s[i]=i;d[i]=0;}
}
int find(int x)
{
if(x!=s[x])
{
int t=s[x];
s[x]=find(s[x]);
d[x]+=d[t];
}
return s[x];
}
void merge(int a,int b,int v)
{
int ra=find(a),rb=find(b);
if(ra==rb)
{
if(d[a]-d[b]!=v)ans++;
}
else
{
s[ra]=rb;
d[ra]=d[b]-d[a]+v;
}
}
int main()
{
int n,m;
while(cin>>n>>m)
{
ans=0;
init();
for(int i=0;i<m;i++)
{
int x,y,v;
cin>>x>>y>>v;
x--;
merge(x,y,v);
}
cout<<ans;
}
return 0;
}
[poj-1182](1182 -- 食物链 (poj.org))

这一题的权值是从题目中抽象出来的一种属性,这个属性可以表示两个动物的关系,而这个属性的难点在于找出权值的更新关系。

合并并查集是类似上一题的做法,把权值抽象为距离关系,找到两个值同属于一个集合计算出的值与既定的值矛盾即可忽略
代码模板
#include <bits/stdc++.h>
using namespace std;
const int N=5e4+10;
int s[N];
int d[N];
int ans;
void init()
{
for(int i=1;i<N;i++)s[i]=i;
}
int find(int x)
{
if(x!=s[x])
{
int t=s[x];
s[x]=find(s[x]);
d[x]=(d[x]+d[t])%3;
}
return s[x];
}
void merge(int x,int y,int v)
{
int rx=find(x),ry=find(y);
if(rx==ry)
{
if((d[x]-d[y]+3)%3!=v)ans++;
}
else
{
s[rx]=ry;
d[rx]=(d[y]-d[x]+v)%3;
}
}
int main()
{
int n,k;
cin>>n>>k;
init();
while(k--)
{
int d,x,y;
cin>>d>>x>>y;
d--; //在题目中1是同类,2是吃,我们规定的是0是同类1是吃。
if(x>n||y>n||(x==y&&d==1))ans++;
else merge(x,y,d);
}
cout<<ans;
return 0;
}
五、习题集
poj
2524/1611/1703/2236/2492/1988/1182
hud
3635/1856/1272/1325/1198/2586/6109
洛谷
P1111/P3958/P1525/P4185/P2024/P1197/P1196/P1955文章来源:https://www.toymoban.com/news/detail-560050.html
声明
本文是《算法竞赛》的笔记,仅此而已。文章来源地址https://www.toymoban.com/news/detail-560050.html
到了这里,关于并查集笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!