1介绍

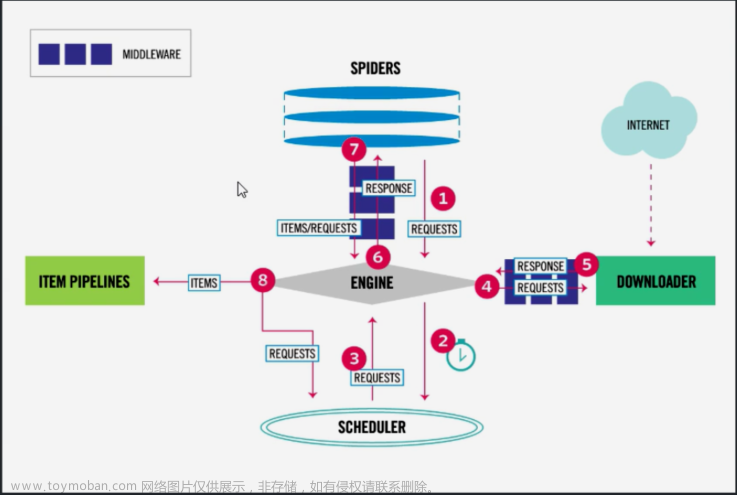
scrapy架构
引擎(EGINE):引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。大总管,负责整个爬虫数据的流动
调度器(SCHEDULER)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(DOWLOADER) 用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的(效率很高,同时可以发送特别多请求出出)
爬虫(SPIDERS) SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
项目管道(ITEM PIPLINES) 在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
# 下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,你可用该中间件做以下几件事
爬虫中间件(Spider Middlewares)位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
2.安装
Windows平台
可以先试一下,
pip3 install scrapy如果不成功,用如下方法:
1.安装wheel后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
pip3 install wheel2.
pip3 install lxmlpip3 install pyopenssl3.下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
4.下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
5.执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
6.pip3 install scrapy
Linux,mac平台
pip3 install scrapy3.创建scrapy项目--->使用命令 cmd
1.先cd到scrapy项目要保存的文件夹
2.创建项目
scrapy startproject 项目名字3创建爬虫
scrapy genspider 爬虫的名字 爬虫的网址
例子 :
scrapy genspider baidu www.baidu.com4. 启动爬虫
scrapy crawl cnblogs也可以在run.py 中写
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'cnblogs','--nolog'])4.scrapy项目目录结构
mysfirstscrapy # 项目名
mysfirstscrapy # 包
spiders # 包,里面放了自定义的爬虫,类似于app
__init__.py
baidu.py # 百度爬虫
cnblogs.py#cnblogs爬虫
items.py #类似于django的 models表模型,一个个模型类
middlewares.py # 中间件
pipelines.py #管道---》写持久化
settings.py #项目配置文件
scrapy.cfg # 项目上线配置
5 scrapy解析数据
1 response对象有css方法和xpath方法
-css中写css选择器
-xpath中写xpath选择
2 重点1:
-xpath取文本内容
'.//a[contains(@class,"link-title")]/text()'
-xpath取属性
'.//a[contains(@class,"link-title")]/@href'
-css取文本
'a.link-title::text'
-css取属性
'img.image-scale::attr(src)'
3 重点2:
.extract_first() 取一个
.extract() 取所有
创建爬虫文件分析
文章来源:https://www.toymoban.com/news/detail-560191.html
import scrapy
爬虫类,继承了scrapy.Spider
class CnblogSpider(scrapy.Spider):
name = "cnblog" #爬虫的名字
allowed_domains = ["www.cnblog.com"] # 允许爬取的域
start_urls = ["https://www.cnblog.com"] # 开始爬取的地址
def parse(self, response):
pass文章来源地址https://www.toymoban.com/news/detail-560191.html
到了这里,关于scrapy---爬虫界的django的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!