三 链表
3.1 链表的基本概念
前面我们在学习顺序表时,线性表的顺序存储结构的特点是逻辑关系上相邻的两个数据元素在物理位置上也是相邻的。我们会发现虽然顺序表的查询很快,时间复杂度为O(1),但是增删的效率是比较低的,因为每一次增删操作都伴随着大量的数据元素移动。为了解决这个问题我们可以使用另外一种存储结构实现线性表,链式存储结构。
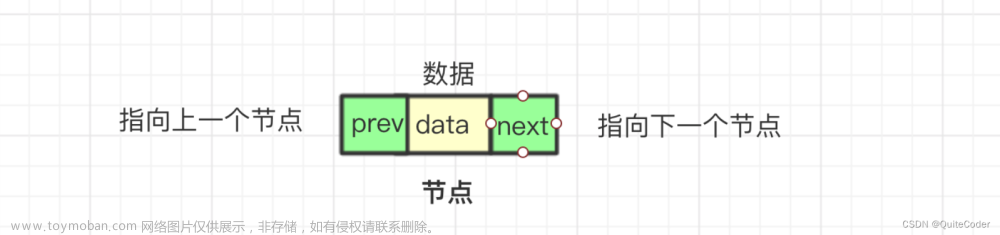
线性表的链式存储结构(也称之为链表)的特点是逻辑关系上相邻的两个数据元素在物理位置上不一定是相邻的,换言之数据元素在存储器中的位置可以是任意的。为了表示每个数据元素ai与其直接后继 ai+1之间的逻辑关系,对于数据元素ai来说,除了存储其本身的信息外,还需存储一个能够保存直接后继的存储位置的指针,这两部分信息组成数据元素ai的存储映像,我们称之为结点(node)。
结点包含两个或者三个域:存储数据元素信息的域叫做数据域,存储直接后继存储位置的域叫做指针域,存储直接前驱存储位置的域也叫做指针域。
如果只有一个指针域保存直接后继存储位置,这样的链表我们称之为单向链表。
如果既有指针域名保存直接后继存储位置,又有指针域存储直接前驱存储位置,这样的链表我们称之为双向链表。
为了方便对链表进行插入结点和删除结点的操作,一般地链表中的第一个结点不存储实际的数据元素,该结点我们称之为:头结点。
单向链表的头结点中数据域不存储实际数据元素,双向链表的头结点中数据域不存储实际数据元素,并且直接前驱指针域为空(因为头结点没有直接前驱结点)
3.2 单向链表
在对单向链表进行访问时,需要使用一个指针指向链表中的第一个结点(头结点),这个指针我们称之为:头指针。头指针保存了链表中头结点的存储位置。
1、单向链表结点
typedef int ElemType;
typedef struct LNode{
ElemType data; //数据域
struct LNode *next; //指针域,指向当前结点的直接后继
}LNode, *LinkList; //LinkList 的类型为 LNode*2、单向链表初始化
当链表为空时,头结点的指针域为空:
初始化一个链表:
-
创建一个头结点,头结点的指针域为空
-
创建一个头指针,头指针指向头结点(将头结点的地址赋值给头指针)
LinkList list_init(){
LNode *t;
t = (LNode *)malloc(sizeof(LNode)); //创建一个头结点
t->next = NULL; //头结点的指针域为空
LinkList head; //定义一个头指针
head = t; //头指针指向头结点
return head;
}3、单向链表头插法
逻辑:
-
创建一个新的结点p
-
将新的结点p的next指向头节点的下一个结点(head->next)
-
头节点的next指向新的结点p
/*
* @brief 头插法插入一个结点
* @param 需要插入的链表的头指针
* @param 需要插入的数据
* @return 成功返回TRUE,失败返回FALSE
* */
int head_insert(LinkList head, LNode **tail, ElemType data){
if (NULL == head){
printf("[%s %d] head pointer is NULL ...\n", __FUNCTION__ , __LINE__);
return FALSE;
}
//创建一个新的结点p
LNode *p;
p = (LNode *)malloc(sizeof(LNode));
p->data = data;
p->next = NULL;
//如果链表为空, 那么第一个插入的结点就是整个链表的尾结点
if (NULL == head->next)
*tail = p;
//将新的结点p的next指向头结点的下一个节点(head->next)
p->next = head->next;
//头结点的next指向新的结点p
head->next = p;
return TRUE;
}4、单向链表的打印
逻辑:
-
使用一个临时指针指向头节点后的第一个结点
-
使用临时指针进行遍历,知道临时指针为NULL
/*
* @brief 输出链表中所有的结点
* @param head 链表的头指针
* @return 成功返回TRUE,失败返回FALSE
* */
int print_list(LinkList head){
if (NULL == head)
return FALSE;
//使用一个临时指针对链表进行遍历
LNode *t;
t = head->next;
while (t != NULL){
printf("%d", t->data);
t = t->next;
}
return TRUE;
}5、单向链表尾插法
逻辑:
-
新建一个新的结点
-
将尾指针的next指向新的结点
-
将尾指针指向新的结点
改造head_insert函数,将链表的尾结点指针的地址传入:
/*
* @brief 尾插法插入一个结点
* @param head 需要插入的链表的头指针
* @param tail 尾结点指针的地址
* @param data 需要插入的数据
* @return 成功返回TRUE,失败返回FALSE
* */
int tail_insert(LinkList head, LNode **tail, ElemType data){
if (NULL == head){
printf("[%s %d] head pointer is NULL ...\n", __FUNCTION__ , __LINE__);
return FALSE;
}
//创建一个新的结点p
LNode *p;
p = (LNode *)malloc(sizeof(LNode));
p->data = data;
p->next = NULL;
//如果链表为空,将头结点的next指向新的结点
if (NULL == head->next)
head->next = p;
else{
(*tail)->next = p;
}
*tail = p;
return TRUE;
}6、获取链表上指定的元素
逻辑:
-
从链表的第一个数据结点开始遍历
-
将遍历到的每一个结点上的数据域与需要获取/查找的元素比较
-
如果相等返回该结点的地址
-
如果不相等则继续往后遍历
-
如果遍历到链表末尾依然没有找到则返回NULL
/*
* @brief 获取链表上指定的元素
* @param head 需要查找的链表的头指针
* @param data 需要查找的元素
* @return 成功返回元素所在的结点的地址,失败返回NULL
* */
LNode *get_elem(LinkList head, ElemType data){
if (NULL == head){
printf("[%s %d] head pointer is NULL ...\n", __FUNCTION__, __LINE__);
return NULL;
}
LNode *t;
t = head->next;
while (t != NULL){
if (t->data == data)
return t;
t = t->next;
}
return NULL;
}7、获取链表上指定位置的元素
逻辑:
-
从链表的第一个数据结点开始遍历
-
每遍历一个结点遍历次数+1,同时判断是否遍历到了链表的末尾
-
如果遍历到了链表末尾返回NULL
-
或者遍历到了指定位置返回结点指针
/*
* @brief 获取指定位置的元素
* @param 需要遍历的链表的头指针
* @param index 需要遍历到的位置(从1开始)
* @return 成功返回对应位置的结点指针,失败返回NULL
* */
LNode *get_elem_by_index(LinkList head, uint index){
if (NULL == head){
printf("[%s %d] head pointer is NULL ...\n", __FUNCTION__, __LINE__);
return NULL;
}
//用一个临时指针指向链表的第一个数据结点
LNode *t = head->next;
int i=1;
//判断是否遍历到了链表末尾或者遍历到了指定的位置
while (i<=index && t!=NULL){
i++;
t = t->next;
}
return t;
}8、删除链表上指定位置的元素
逻辑:
-
使用临时指针 t 从链表的第一个数据结点开始遍历
-
使用临时指针 p 保存遍历到的结点的前驱结点
-
每遍历一个结点遍历次数+1,指针 p 与随之往后移动,同时判断是否遍历到了链表的末尾
-
如果遍历到了链表的末尾则返回FALSE
-
如果遍历到的位置恰好是最后一个结点(尾结点),则将尾指针指向该结点的前一个结点,尾指针的next赋值为NULL,并且删除最后一个结点
-
如果遍历到的结点是中间结点,则将前驱结点指向遍历到的结点的下一个结点(指针 p->next = t->next)
/*
* @brief 删除指定位置的结点
* @param head 需要删除的链表的头指针
* @param tail 需要删除的链表的尾指针地址
* @param index 需要删除的元素的位置
* @return 成功返回 TRUE, 失败返回FALSE
* */
int delete_by_index(LinkList head, LNode **tail, uint index){
if (NULL == head){
printf("[%s %d] head pointer is NULL ...\n", __FUNCTION__, __LINE__);
return FALSE;
}
LNode *t = head->next;
LNode *p = head;
int i = 1;
while (i < index && t != NULL){
i++;
t = t->next;
p = p->next;
}
if (t == NULL){
printf("[%s %d] can not delete\n", __FUNCTION__, __LINE__);
return FALSE;
}
//如果刚好是遍历到了最后一个结点
if (t->next == NULL){
*tail = p;
(*tail)->next = NULL;
free(t);
return TRUE;
}
//如果是中间的结点
p->next = t->next;
free(t);
return TRUE;
}9、删除链表上指定元素所在的结点
逻辑:
-
使用临时指针t从链表的第一个数据结点开始遍历,一直遍历到链表末尾
-
使用临时指针 p 保存遍历到的结点的前驱结点
-
将遍历到的每一个结点上的数据域与需要删除的元素比较
-
如果遍历到的结点恰好是尾结点,将尾指针tail指向需要删除的结点的前驱结点p,尾指针tail->next=NULL,释放当前结点free(t),返回TRUE
-
如果遍历到的结点是中间结点,驱结点指向当前结点的下一个结点p->next = t->next, 释放当前结点free(t),临时指针t指向下一个结点继续往后遍历 t = p->next
/*
* @brief 删除指定元素所在的结点
* @param head 需要删除的链表的头指针
* @param tail 需要删除的链表的尾指针地址
* @param data 需要删除的元素的值
* @return 成功返回TRUE, 失败返回FALSE
* */
int delete_by_elem_value(LinkList head, LNode **tail, ElemType data){
if (NULL == head){
printf("[%s %d] head pointer is NULL ...\n", __FUNCTION__, __LINE__);
return FALSE;
}
LNode *t = head->next;
LNode *p = head;
//遍历到链表的末尾
while (t != NULL){
//如果遍历到了需要删除的结点
if (t->data == data){
//如果当前结点为尾结点
if (t->next == NULL){
*tail = p;
(*tail)->next = NULL;
free(t);
return TRUE;
}
//如果是中间的结点,前驱结点指向当前结点的下一个结点
p->next = t->next;
free(t);
t = p->next;
}
else{
t = t->next;
p = p->next;
}
}
return TRUE;
}10、在链表指定位置/指定位置前插入一个结点
逻辑:
-
使用临时指针 t 从链表的第一个数据结点开始遍历
-
使用临时指针 p 保存遍历到的结点的前驱结点
-
每遍历一个结点遍历次数+1,指针 p 与随之往后移动,同时判断是否遍历到了链表的末尾
-
如果遍历到了链表的末尾则返回FALSE
-
如果遍历到了指定的位置
-
创建一个新的结点n
-
将前驱结点p指向新的结点n,p->next = n,将新的结点指向遍历到的结点, n->next = t
-
返回TRUE
/*
* @brief 在指定的位置插入一个元素
* @param head 需要插入的链表的头指针
* @param index 需要插入的元素的位置
* @param data 需要插入的元素的值
* @return 成功返回TRUE,失败返回FALSE
* */
int insert_by_index(LinkList head, uint index, ElemType data){
if (NULL == head){
printf("[%s %d] head pointer is NULL ...\n", __FUNCTION__, __LINE__);
return FALSE;
}
LNode *t = head->next;
LNode *p = head;
int i = 1;
while (i < index && t != NULL){
i++;
t = t->next;
p = p->next;
}
//如果将整个链表遍历完毕,就说明需要插入在不在链表
if (NULL == t){
printf("[%s %d] index: %d out of range ...\n", __FUNCTION__ , __LINE__);
return FALSE;
}
//创建一个新的结点p
LNode *n;
n = (LNode *)malloc(sizeof(LNode));
n->data = data;
n->next = NULL;
p->next = n;
n->next = t;
return TRUE;
}11、插入一个元素使得整个链表依然保持为升序(原链表为升序)
逻辑:找到一个比需要插入的元素大的结点,在这个结点的前面插入新的结点
-
使用临时指针 p 保存遍历到的结点的前驱结点
-
使用临时指针 t 从链表的第一个数据结点开始遍历
-
每遍历一个结点遍历次数+1,指针 p 与随之往后移动,同时判断遍历到的结点是否比需要插入的元素大
-
如果比需要插入的元素小则继续往后遍历
-
如果比需要插入的元素大,新创建一个结点n
-
判断该结点是否为尾结点,如果是尾结点 t->next = n, tail = n
-
如果不是尾结点将前驱结点p指向新的结点n,p->next = n,将新的结点指向遍历到的结点, n->next = t
-
如果将整个链表遍历完毕依然没有找到比需要插入的元素大的结点,则说明该结点将会是整个链表上最大的结点,应该插入到链表的末尾。 p->next = n, tail = n ,或者调用尾插法函数
/*
* @brief 插入一个元素使得整个链表依然保持为升序(原链表为升序)
* @param head 链表的头指针
* @param pTail 链表的尾指针地址
* @param data 需要插入的元素的值
* @return 成功返回TRUE,失败返回FALSE
* */
int ascending_insert(LinkList head, LNode **pTail, ElemType data)
{
if (NULL == head)
{
printf("[%s %d] head pointer is NULL ...\n", __FUNCTION__ , __LINE__);
return FALSE;
}
//创建一个新的结点p
LNode *n;
n = (LNode *)malloc(sizeof(LNode));
n->data = data;
n->next = NULL;
LNode *t = head->next;
LNode *p = head;
while (t != NULL)
{
if (t->data <= data)
{
t = t->next;
p = p->next;
continue;
}
//前驱结点p指向新的结点n,p->next = n,将新的结点指向遍历到的结点, n->next = t
p->next = n;
n->next = t;
break;
}
//如果将整个链表遍历完毕依然没有找到比需要插入的元素大的结点,则说明该结点将会是整个链表上最大的结点,应该插入到链表的末尾
// p->next = n, tail = n ,或者调用尾插法函数
p->next = n;
*pTail = n;
return TRUE;
}12、销毁链表
逻辑:
-
使用临时指针 t 从链表的第一个数据结点开始遍历,直到遍历到链表的末尾
-
每遍历到一个结点首先将头结点的next赋值为当前节点的下一个结点 head->next = t->next, 然后临时指针t指向下一个结点 t = head->next文章来源:https://www.toymoban.com/news/detail-560632.html
-
如果整个链表遍历完毕则删除结点文章来源地址https://www.toymoban.com/news/detail-560632.html
/*
* @brief 销毁链表
* @param head 需要销毁的链表的头指针
* @return 成功返回TRUE, 失败返回FALSE
* */
int list_destroy(LinkList head)
{
if (NULL == head)
{
printf("[%s %d] head pointer is NULL ...\n", __FUNCTION__ , __LINE__);
return FALSE;
}
LNode *t = head->next;
while (t != NULL)
{
head->next = t->next;
free(t);
t = head->next;
}
//把头结点也释放掉
free(head);
return TRUE;
}到了这里,关于02-链表 (数据结构和算法)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!